Что такое нечеткая экспертная система?
Date: 21-APR-93
A fuzzy expert system is an expert system that uses a collection of
fuzzy membership functions and rules, instead of Boolean logic, to
reason about data. The rules in a fuzzy expert system are usually of a
form similar to the following:
Нечеткая экспертная система - экспертная система, которая использует нечеткие функции принадлежности и правила, вместо Булевой логики, для рассуждения относительно данных. Правила в нечеткой экспертной системе имеют обычно форму, подобную следующему:
if x is low and y is high then z = medium
если x - низко и y - высоко тогда z = среднее
where x and y are input variables (names for know data values), z is an
output variable (a name for a data value to be computed), low is a
membership function (fuzzy subset) defined on x, high is a membership
function defined on y, and medium is a membership function defined on z.
The antecedent (the rule's premise) describes to what degree the rule
applies, while the conclusion (the rule's consequent) assigns a
membership function to each of one or more output variables. Most tools
for working with fuzzy expert systems allow more than one conclusion per
rule. The set of rules in a fuzzy expert system is known as the rulebase
or knowledge base.
Где x и y - входные переменные (имена для известных значений данных), z - переменная вывода (имя для значения данных, которое будет вычислено), низко - функция принадлежности (нечеткое подмножество) определенная на x, высоко - функция принадлежности, определенная на y, и среднее - функция принадлежности, определенная на z. Априорно (предпосылка правил) описывается, что степень правила применяется, в то время как заключение (следствие правила) назначает функцию принадлежности для каждой из переменных вывода. Большинство инструментальных средств для работы с нечеткими экспертными системами позволяет больше чем одно заключение на правило. Набор правил в нечеткой экспертной системе известен как база правил или база знаний.
The general inference process proceeds in three (or four) steps.
Общий логический вывод происходит в три (или четыре) шага.
1. Under FUZZIFICATION, the membership functions defined on the
input variables are applied to their actual values, to determine the
degree of truth for each rule premise.
1. НЕЧЕТКОСТЬ. Функции принадлежности, определенные на входных переменных применяются к их фактическим значениям, для определения степени правды для каждой предпосылки правила.
2. Under INFERENCE, the truth value for the premise of each rule is
computed, and applied to the conclusion part of each rule. This results
in one fuzzy subset to be assigned to each output variable for each
rule. Usually only MIN or PRODUCT are used as inference rules. In MIN
inferencing, the output membership function is clipped off at a height
corresponding to the rule premise's computed degree of truth (fuzzy
logic AND). In PRODUCT inferencing, the output membership function is
scaled by the rule premise's computed degree of truth.
2. ЛОГИЧЕСКИЙ ВЫВОД. Значение истинности для предпосылки каждого правила вычислено, и применяется к части заключения каждого правила. Это приводит к одному нечеткому подмножеству, которое будет назначено к каждой переменной вывода для каждого правила. Обычно только МИНИМУМ или УМНОЖЕНИЕ используется как правила логического вывода. В логическом выводе МИНИМУМА, функция принадлежности вывода отсекается по высоте, соответствующей предпосылки правила вычисленной степень правды (нечеткая логика И). В логическом выводе УМНОЖЕНИЕ, функция принадлежности вывода масштабируется при помощи предпосылки правила вычисленной степень правды.
3. Under COMPOSITION, all of the fuzzy subsets assigned to each output
variable are combined together to form a single fuzzy subset
for each output variable. Again, usually MAX or SUM are used. In MAX
composition, the combined output fuzzy subset is constructed by taking
the pointwise maximum over all of the fuzzy subsets assigned tovariable
by the inference rule (fuzzy logic OR). In SUM composition, the
combined output fuzzy subset is constructed by taking the pointwise sum
over all of the fuzzy subsets assigned to the output variable by the
inference rule.
3. КОМПОЗИЦИЯ. Все нечеткие подмножества, назначенные к каждой переменной вывода(во всех правилах), объединены вместе, чтобы формировать одно нечеткое подмножество для каждой переменной вывода. Снова, обычно МАКСИМУМ или СУММА используются. При композиции МАКСИМУМ, комбинированый вывод нечеткого подмножества конструируется, принимая поточечный максимум по всеми нечеткими подмножествами, назначая переменной правила заключения (нечеткая логика ИЛИ). При композиции СУММЫ, комбинированный вывод нечеткого подмножества конструируется, принимая поточечно сумму по всеми нечеткими подмножествами, назначенными к переменной вывода правилом логического вывода.
4. Finally is the (optional) DEFUZZIFICATION, which is used when it is
useful to convert the fuzzy output set to a crisp number. There are
more defuzzification methods than you can shake a stick at (at least
30). Two of the more common techniques are the CENTROID and MAXIMUM
methods. In the CENTROID method, the crisp value of the output variable
is computed by finding the variable value of the center of gravity of
the membership function for the fuzzy value. In the MAXIMUM method, one
of the variable values at which the fuzzy subset has its maximum truth
value is chosen as the crisp value for the output variable.
4. В заключение - (дополнительно) ПРИВЕДЕНИЕ К ЧЕТКОСТИ, которое используется, когда полезно преобразовать нечеткий набор выводов в четкое число. Имеется большее количество методы приведения к четкости (по крайней мере 30). Два наболее общих метода - ЦЕНТРАЛЬНЫЙ и МАКСИМАЛЬНЫЙ методы. В ЦЕНТРАЛЬНОМ методе, четкое значение переменной вывода вычисляется, нахождением значения переменной центра тяжести для функции принадлежности нечеткого значения.
В МАКСИМАЛЬНОМ методе, одно из значений переменной, при которой нечеткое подмножество имеет максимальное значение истинности, выбрано как четкое значение для переменной вывода.
Extended Example:
Расширенный пример:
Assume that the variables x, y, and z all take on values in the interval
[0,10], and that the following membership functions and rules are defined:
Примем, что переменные x, y, и z, имеют значения в интервале [0,10], и что следующая функция принадлежности и правила определены:
низко(t) = 1 - ( t / 10 )
высоко(t) = t / 10
правило 1: если x - низко и y - низко тогда z = высоко
правило 2: если x - низко и y - высоко тогда z = низко
правило 3: если x - высоко и y - низко тогда z = низко
правило 4: если x - высоко и y - высоко тогда z = высоко
Notice that instead of assigning a single value to the output variable z, each
rule assigns an entire fuzzy subset (low or high).
Обратите внимание, что вместо того, чтобы назначать одно значение переменной вывода z, каждое правило назначает все нечеткое подмножество (низко или высоко).
Notes:
Примечание:
1. In this example, low(t)+high(t)=1.0 for all t. This is not required, but
it is fairly common.
1. В этом примере, низко(t) + высоко(t) = 1.0 для всех t. Это не требуется, но это довольно общее.
2. The value of t at which low(t) is maximum is the same as the value of t at
which high(t) is minimum, and vice-versa. This is also not required, but
fairly common.
2. Значение t, при котором низко(t) является максимальным - тоже значение t, при котором высоко(t) является минимальным, и напротив. Это также не требуется, но довольно общее.
3. The same membership functions are used for all variables. This isn't
required, and is also *not* common.
3. Те же самые функции принадлежности используются для всех переменных. Это не требуется, и также *не* общее.
In the fuzzification subprocess, the membership functions defined on the
input variables are applied to their actual values, to determine the
degree of truth for each rule premise. The degree of truth for a rule's
premise is sometimes referred to as its ALPHA. If a rule's premise has a
nonzero degree of truth (if the rule applies at all...) then the rule is
said to FIRE. For example,
В подпроцессе нечеткости, функции принадлежности, определенные на входных переменных применяются к их фактическим значениям, определяя степень правды для каждой предпосылки правила. Степень правды для предпосылки правила иногда упоминается как АЛЬФА. Если предпосылка правила имеет степень отличную от нуля правды (если правило применяется во всем ...) тогда правило говорят в ОГОНЕ(или ГОРИТ). Например,
x y low(x) high(x) low(y) high(y) alpha1 alpha2 alpha3 alpha4
------------------------------------------------------------------------------
0.0 0.0 1.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0
0.0 3.2 1.0 0.0 0.68 0.32 0.68 0.32 0.0 0.0
0.0 6.1 1.0 0.0 0.39 0.61 0.39 0.61 0.0 0.0
0.0 10.0 1.0 0.0 0.0 1.0 0.0 1.0 0.0 0.0
3.2 0.0 0.68 0.32 1.0 0.0 0.68 0.0 0.32 0.0
6.1 0.0 0.39 0.61 1.0 0.0 0.39 0.0 0.61 0.0
10.0 0.0 0.0 1.0 1.0 0.0 0.0 0.0 1.0 0.0
3.2 3.1 0.68 0.32 0.69 0.31 0.68 0.31 0.32 0.31
3.2 3.3 0.68 0.32 0.67 0.33 0.67 0.33 0.32 0.32
10.0 10.0 0.0 1.0 0.0 1.0 0.0 0.0 0.0 1.0
In the inference subprocess, the truth value for the premise of each rule is
computed, and applied to the conclusion part of each rule. This results in
one fuzzy subset to be assigned to each output variable for each rule.
В подпроцессе логического вывода, значение истинности для предпосылки каждого правила вычислено, и применяется к части заключения каждого правила. Это приводит к одному нечеткому подмножеству, которое будет назначено к каждой переменной вывода для каждого правила.
MIN and PRODUCT are two INFERENCE METHODS or INFERENCE RULES. In MIN
inferencing, the output membership function is clipped off at a height
corresponding to the rule premise's computed degree of truth. This
corresponds to the traditional interpretation of the fuzzy logic AND
operation. In PRODUCT inferencing, the output membership function is
scaled by the rule premise's computed degree of truth.
МИНИМУМ и УМНОЖЕНИЕ - два МЕТОДА ЛОГИЧЕСКОГО ВЫВОДА или ПРАВИЛ ЛОГИЧЕСКОГО ВЫВОДА. В логическом выводе МИНИМУМА, функция принадлежности вывода отсекается по высоте, соответствующей предпосылке правила вычисленной степени правды. Это соответствует к традиционной интерпретации нечеткой логической операции AND. В логическом выводе УМНОЖЕНИЯ, функция принадлежности вывода масштабируется предпосылкой правила вычисленной степень правды.
For example, let's look at rule 1 for x = 0.0 and y = 3.2. As shown in the
table above, the premise degree of truth works out to 0.68. For this rule,
MIN inferencing will assign z the fuzzy subset defined by the membership
function:
Например, давайте рассматривать правило 1 для x = 0.0 и y = 3.2. Как показано в таблице выше, степень предпосылки правды равна 0.68. Для этого правила, логический вывод МИНИМУМА назначит z нечеткое подмножество, определенное функцией принадлежности:
rule1(z) = { z / 10, if z <= 6.8
0.68, if z >= 6.8 }
правило 1(z) = { z / 10, если z <= 6.8
0.68, если z >= 6.8 }
фактически, получаем новую функцию принадлежности для определения степени низко от z. В обычной экспертной системе получили бы z низко со степенью 0.68. И судя по всему здесь ошибка.
Так как эта функция получается low(x) AND low(y) вырезается часть под графиком 1-(t/10) все значения степени больше 0.68 отбрасываются.
правило 1(z) = { 0.68, если z <= 6.8
1-(z / 10), если z >= 6.8 }
For the same conditions, PRODUCT inferencing will assign z the fuzzy subset
defined by the membership function:
Для тех же самых условий, логический вывод УМНОЖЕНИЯ назначит z нечеткое подмножество, определенное функцией принадлежности:
rule1(z) = 0.68 * high(z)
= 0.068 * z
Note: The terminology used here is slightly nonstandard. In most texts,
the term "inference method" is used to mean the combination of the things
referred to separately here as "inference" and "composition." Thus
you'll see such terms as "MAX-MIN inference" and "SUM-PRODUCT inference"
in the literature. They are the combination of MAX composition and MIN
inference, or SUM composition and PRODUCT inference, respectively.
You'll also see the reverse terms "MIN-MAX" and "PRODUCT-SUM" -- these
mean the same things as the reverse order. It seems clearer to describe
the two processes separately.
Отметим: терминология, используемая здесь немного нестандартна. В большинстве текстов, термин "метод заключения" используется, чтобы обозначить комбинацию вещей, упоминаемых отдельно здесь как "заключение" и "композиция". Таким образом вы будете видеть такие термины как "заключение с максимумом-минимумом" и "заключение суммы-произведения" в литературе. Они - комбинация композиции МАКСИМУМА и заключения МИНИМУМА, или композиции СУММЫ и заключение ПРОИЗВЕДЕНИЯ, соответственно. Вы будете также видеть обратные условия "МИНИМУМ-МАКСИМУМ", и "произведения- сумма" - они означают те же самые вещи как обратный порядок. Кажется более ясно описывать два процесса отдельно.
In the composition subprocess, all of the fuzzy subsets assigned to each
output variable are combined together to form a single fuzzy subset for each
output variable.
В подпроцессе композии, все нечеткие подмножества назначеные каждой переменной вывода, объединяются вместе, чтобы формировать единственное нечеткое подмножество для каждой переменной вывода.
MAX composition and SUM composition are two COMPOSITION RULES. In MAX
composition, the combined output fuzzy subset is constructed by taking
the pointwise maximum over all of the fuzzy subsets assigned to the
output variable by the inference rule. In SUM composition, the combined
output fuzzy subset is constructed by taking the pointwise sum over all
of the fuzzy subsets assigned to the output variable by the inference
rule. Note that this can result in truth values greater than one! For
this reason, SUM composition is only used when it will be followed by a
defuzzification method, such as the CENTROID method, that doesn't have a
problem with this odd case. Otherwise SUM composition can be combined
with normalization and is therefore a general purpose method again.
Композиция МАКСИМУМА и композиция СУММЫ - два КОМПОЗИЦИОННЫХ ПРАВИЛА. В композиции МАКСИМУМА, комбинированый вывод нечеткое подмножество создано, принимая поточечно максимум по всем нечетким подмножествами, назначая переменной вывода правила заключения. В композиции СУММЫ, комбинированный вывод нечеткое подмножество создано, принимая поточечную сумму над всеми нечеткими подмножествами, назначая переменной вывода правила заключения. Заметьте, что это может приводить к значениям истинности большее, чем один! По этой причине, композиция СУММЫ только используется, когда это будет сопровождаться привидением к четкости, типа ЦЕНТРАЛЬНОГО метода, который не имеет проблем с этим нечетным случаем. Иначе композиция СУММЫ может быть комбинирована с нормализацией и - следовательно универсальный метод снова.
For example, assume x = 0.0 and y = 3.2. MIN inferencing would assign the
following four fuzzy subsets to z:
Например, примем x = 0.0 и y = 3.2. Логический вывод МИНИМУМА назначил бы следовательно четыре нечетких подмножества z:
rule1(z) = { z / 10, if z <= 6.8
0.68, if z >= 6.8 }
rule2(z) = { 0.32, if z <= 6.8
1 - z / 10, if z >= 6.8 }
rule3(z) = 0.0
rule4(z) = 0.0
MAX composition would result in the fuzzy subset:
Композиция МАКСИМУМА привела бы к нечеткому подмножеству:
fuzzy(z) = { 0.32, if z <= 3.2
z / 10, if 3.2 <= z <= 6.8
0.68, if z >= 6.8 }
PRODUCT inferencing would assign the following four fuzzy subsets to z:
Логический вывод ПРОИЗВЕДЕНИЯ назначил бы следовательно четыре нечетких подмножества z:
rule1(z) = 0.068 * z
rule2(z) = 0.32 - 0.032 * z
rule3(z) = 0.0
rule4(z) = 0.0
SUM composition would result in the fuzzy subset:
Композиция СУММЫ привела бы к нечеткому подмножеству:
fuzzy(z) = 0.32 + 0.036 * z
Sometimes it is useful to just examine the fuzzy subsets that are the
result of the composition process, but more often, this FUZZY VALUE needs
to be converted to a single number -- a CRISP VALUE. This is what the
defuzzification subprocess does.
Иногда полезно только исследовать нечеткие подмножества, которые являются результатом процесса композиции, но более часто, это НЕЧЕТКОЕ ЗНАЧЕНИЕ должно быть преобразовано к единственному числу - ЧЕТКОЕ ЗНАЧЕНИЕ. Это - то, что подпроцесс приведения к четкости делает.
There are more defuzzification methods than you can shake a stick at. A
couple of years ago, Mizumoto did a short paper that compared about ten
defuzzification methods. Two of the more common techniques are the
CENTROID and MAXIMUM methods. In the CENTROID method, the crisp value of
Earlier on in the FAQ, we state that all variables (including z) take on
values in the range [0, 10]. To compute the centroid of the function f(x),
you divide the moment of the function by the area of the function. To compute
the moment of f(x), you compute the integral of x*f(x) dx, and to compute the
area of f(x), you compute the integral of f(x) dx. In this case, we would
compute the area as integral from 0 to 10 of (0.32+0.036*z) dz, which is
Раньше в FAQ, мы формулируем, что все переменные (включая z) берут значения в диапазоне [0, 10]. Чтобы вычислять центр функции f(x), Вы делите момент функции на область функции. Чтобы вычислять момент f(x), Вы вычисляете интеграл x*f(x)dx, и вычисляете область f(x), Вы вычисляете интеграл f(x) dx. В этом случае, мы вычислили бы область как интеграл от 0 до 10 для (0.32 + 0.036*z)dz, который
(0.32 * 10 + 0.018*100) =
(3.2 + 1.8) =
5.0
and the moment as the integral from 0 to 10 of (0.32*z+0.036*z*z) dz, which is
И момент как интеграл от 0 до 10 для (0. 32*z + 0.036*z*z)dz, который
(0.16 * 10 * 10 + 0.012 * 10 * 10 * 10) =
(16 + 12) =
28
Finally, the centroid is 28/5 or 5.6.
В заключение, центр - 28/5 или 5.6.
Note: Sometimes the composition and defuzzification processes are
combined, taking advantage of mathematical relationships that simplify
the process of computing the final output variable values.
Отметим: Иногда композиция и процессы приведения объединены, пользуясь преимуществом математических связей, которые упрощают процесс вычисления значений переменной окончательного результата.
The Mizumoto reference is probably "Improvement Methods of Fuzzy
Controls", in Proceedings of the 3rd IFSA Congress, pages 60-62, 1989.
Что такое нечеткая логика
Date: 15-APR-93
Fuzzy logic is a superset of conventional (Boolean) logic that has been extended to handle the concept of partial truth -- truth values between "completely true" and "completely false". It was introduced by Dr. Lotfi Zadeh of UC/Berkeley in the 1960's as a means to model the uncertainty of natural language. (Note: Lotfi, not Lofti, is the correct spelling of his name.)
Нечеткая логика - надмножество стандартной (Булевой) логики, которая была расширена до понятия частичной правды - значения истинности между "полностью истинный" и "полностью ложный". Это было представлено доктором Лотфи Заде из UC/Berkeley в 1960-ых как способ моделирования неопределенность естественного языка. (Примечание: Lotfi, не Lofti, является правильным правописанием его имени.)
Zadeh says that rather than regarding fuzzy theory as a single theory, we should regard the process of ``fuzzification'' as a methodology to generalize ANY specific theory from a crisp (discrete) to a continuous (fuzzy) form (see "extension principle" in [2]). Thus recently researchers have also introduced "fuzzy calculus", "fuzzy differential equations", and so on (see [7]).
Заде говорит, что не надо оценивать нечеткую теорию как одиночную теория. Мы должны расценить процесс "нечеткости" как методологию. Чтобы обобщить ЛЮБУЮ специфическую теорию из четкого(дискретного) к непрерывной (нечеткой) форме (см. " принцип расширения " в [2]). Таким образом недавно исследователи также представили "нечеткое вычисление", "нечеткие дифференциально-разностные уравнения", и так далее (см. [7]).
Fuzzy Subsets:
Just as there is a strong relationship between Boolean logic and the concept of a subset, there is a similar strong relationship between fuzzy logic and fuzzy subset theory.
Нечеткие Подмножества:
Точно как имеется сильная связь между Булевой логикой и понятием подмножества, имеется подобная сильная связь между нечеткой логикой и нечеткой теорией подмножеств.
In classical set theory, a subset U of a set S can be defined as amapping from the elements of S to the elements of the set {0, 1},
В классической теории множеств, подмножество U множества S может быть определено как отображение элементов S в элементы множества {0, 1},
U: S --> {0, 1}
This mapping may be represented as a set of ordered pairs, with exactly one ordered pair present for each element of S. The first element of the ordered pair is an element of the set S, and the second element is an element of the set {0, 1}. The value zero is used to represent non-membership, and the value one is used to represent membership. The truth or falsity of the statement
Это отображение может представляться как множество упорядоченных пар, где каждая упорядоченная пара, представленна для каждого элемента S. Первый элемент упорядоченной пары - элемент множества S, и второй элемент - элемент множества {0, 1}. Нулевое значение используется, чтобы представить не-принадлежность, и значение один используется, чтобы представить принадлежность. Правду или ложность утверждения
x is in U
is determined by finding the ordered pair whose first element is x. The statement is true if the second element of the ordered pair is 1, and the statement is false if it is 0.
определяется, находя упорядоченную пару, чьей первый элемент является x. Утверждение истинно, если второй элемент упорядоченной пары 1, и утверждение ложно, если он 0.
Similarly, a fuzzy subset F of a set S can be defined as a set of ordered pairs, each with the first element from S, and the second element from the interval [0,1], with exactly one ordered pair present for each element of S. This defines a mapping between elements of the set S and values in the interval [0,1]. The value zero is used to represent complete non-membership, the value one is used to represent complete membership, and values in between are used to represent intermediate DEGREES OF MEMBERSHIP. The set S is referred to as the UNIVERSE OF DISCOURSE for the fuzzy subset F. Frequently, the mapping is described as a function, the MEMBERSHIP FUNCTION of F.
The degree to which the statement
Точно так же, нечеткое подмножество F множества S может быть определено как набор упорядоченных пар, с первым элементом из S, и вторым элементом из интервала [0,1], и точно одна упорядоченная пара, представленна для каждого элемента S. Это определяет отображение между элементами множества S и оценивает в интервале [0,1]. Нуль значение используется, чтобы представить полную не-принадлежность, значение один используется, чтобы представить полную принадлежность, и значения между ними используются, чтобы представить промежуточные СТЕПЕНИ ПРИНАДЛЕЖНОСТИ. Множество S упоминается как ОБЛАСТЬ ИССЛЕДОВАНИЯ для нечеткого подмножества F. Часто, отображение описывается как функция, ФУНКЦИЯ ПРИНАДЛЕЖНОСТИ F. Степень, с которой утверждение
x is in F
is true is determined by finding the ordered pair whose first element is x. The DEGREE OF TRUTH of the statement is the second element of the ordered pair.
является истинным, определяется, находя упорядоченную пару, чьим первым элементом является x. СТЕПЕНЬ ПРАВДЫ утверждения - второй элемент упорядоченной пары.
In practice, the terms "membership function" and fuzzy subset get used interchangeably.
Практически, термины "функция принадлежности" и нечеткое подмножество становят взаимозаменяемы.
That's a lot of mathematical baggage, so here's an example. Let's talk about people and "tallness". In this case the set S (the universe of discourse) is the set of people. Let's define a fuzzy subset TALL, which will answer the question "to what degree is person x tall?" Zadeh describes TALL as a LINGUISTIC VARIABLE, which represents our cognitive category of "tallness". To each person in the universe of discourse, we have to assign a degree of membership in the fuzzy subset TALL. The easiest way to do this is with a membership function based on the person's height.
Достаточно математики, рассмотрим пример.
Поговорим относительно людей и из "роста". В этом случае множество S (область исследования) - множество людей. Давайте, определим нечеткое подмножество РОСТ (TALL), которое отвечает на вопрос "в какой степени персона x высока?" Заде описывает РОСТ как ЛИНГВИСТИЧЕСКУЮ ПЕРЕМЕННУЮ, которая представляет наш класс распознавания "роста". Каждому человеку в области исследования, мы должны назначить степень принадлежности в нечетком подмножестве РОСТА. Самый простой способ сделать это - функция принадлежности, основанная на росте человека.
рост(x) = { 0, если высота(x) < 150 см.,
(высота(x)-5ft.)/2ft., если 150 см <= высота (x) <= 210 см,
1, если высота(x) > 210 см. }
На диаграмме:
1.0 + +-------------------
| /
| /
0.5 + /
| /
| /
0.0 +-------------+-----+-------------------
| |
150 210
высота, см. ->
Для примера несколько значений:
Человек Высота степень роста
--------------------------------------
Billy 95 0.00 [Я думаю]
Yoke 163 0.21
Drew 173 0.38
Erik 175 0.42
Mark 182 0.54
Kareem 215 1.00 [зависит от того кого вы спрашивате]
Expressions like "A is X" can be interpreted as degrees of truth, e.g., "Drew is TALL" = 0.38.
Выражения подобно "А из X" может интерпретироваться как степень правды, например, "Drew, ВЫСОК" = 0.38.
Note: Membership functions used in most applications almost never have as simple a shape as tall(x). At minimum, they tend to be triangles pointing up, and they can be much more complex than that. Also, the discussion characterizes membership functions as if they always are based on a single criterion, but this isn't always the case, although it is quite common. One could, for example, want to have the membership function for TALL depend on both a person's height and their age (he's tall for his age). This is perfectly legitimate, and occasionally used in practice.
It's referred to as a two-dimensional membership function, or a "fuzzy relation". It' s also possible to have even more criteria, or to have the membership function depend on elements from two completely different universes of discourse.
Обратите внимание: функции принадлежности, используемые в большинстве приложений почти никогда не имеют такую простою форму, как рост(x). Минимум, они имеют тенденцию, чтобы быть треугольниками, и они могут быть намного более комплексными, чем в примере ( прим. перев. вообще-то и в примере не все верно, так понятие "высокости" человека зависит от множества факторов и точно не линейно, примером могут служить топ - модели). Также, обсуждение символических функций принадлежности, как будто они всегда основаны на одиночном критерии, но это не всегда имеет место, хотя это совершенно общее. Можно было, например, хотеть иметь функцию принадлежности для РОСТА, в зависимости, и от высоты человека, и от его возраста (он высок для его возраста). Это совершенно законно, и иногда использовано практически. Это упоминается как двумерная функция принадлежности, или "нечеткое соотношение". Также возможно иметь даже большее количество критериев, или иметь функцию принадлежности зависящую от элементов из двух полностью различных областей исследования.
Logic Operations:
Now that we know what a statement like "X is LOW" means in fuzzy logic, how do we interpret a statement like
Логические Операции:
Теперь, когда мы знаем то, что утверждение подобно "X - НИЗКИЙ" обозначает в нечеткой логике, как мы интерпретируем утверждение подобно
X is LOW and Y is HIGH or (not Z is MEDIUM)
X НИЗКИЙ, и Y ВЫСОКИЙ, или (не Z - СРЕДНИЙ)
The standard definitions in fuzzy logic are:
Стандартные определения в нечеткой логике:
truth (not x) = 1.0 - truth (x)
truth (x and y) = minimum (truth(x), truth(y))
truth (x or y) = maximum (truth(x), truth(y))
правда (не x) = 1.0 - правда(x)
правда (x и y) = minimum (правда(x), правда(y))
правда (x или y) = maximum (правда(x), правда(y))
Some researchers in fuzzy logic have explored the use of other interpretations of the AND and OR operations, but the definition for the NOT operation seems to be safe.
Некоторые исследователи по нечеткой логике ииследовали использование других интерпретаций операций AND и OR, но определение для операции NOT, кажется, безопасное.
Note that if you plug just the values zero and one into these definitions, you get the same truth tables as you would expect from conventional Boolean logic. This is known as the EXTENSION PRINCIPLE, which states that the classical results of Boolean logic are recovered from fuzzy logic operations when all fuzzy membership grades are restricted to the traditional set {0, 1}. This effectively establishes fuzzy subsets and logic as a true generalization of classical set theory and logic. In fact, by this reasoning all crisp (traditional) subsets ARE fuzzy subsets of this very special type; and there is no conflict between fuzzy and crisp methods.
Обратите внимание, что, если Вы используете только значения нуля и единицы в этих определениях, Вы получаете те же самые таблицы истинности, какие Вы ожидали бы от стандартной Булевой логики. Это известно как ПРИНЦИП РАСШИРЕНИЯ, который заявляет, что классические результаты Булевой логики повторяют нечеткие логические операции, когда все нечеткие степени принадлежности ограничены традиционным множеством {0, 1}. Это действительно устанавливает нечеткие подмножества и логику как истинное обобщение классической теории множеств и логики. Фактически, с этим рассуждением все четкие (традиционные) подмножества это нечеткие подмножества, но очень специального типа; и не имеется никакого конфликта между нечеткими и четкими методами.
Some examples -- assume the same definition of TALL as above, and in addition, assume that we have a fuzzy subset OLD defined by the membership function:
В некоторых примерах имеется то же самое определение РОСТА как выше, и кроме того, принимается, что имеется нечеткое подмножество СТАРОСТЬ определенное функцией принадлежности:
old (x) = { 0, if age(x) < 18 yr.
(age(x)-18 yr.)/42 yr., if 18 yr. <= age(x) <= 60 yr.
1, if age(x) > 60 yr. }
старость(x)={ 0, если возраст(x) < 18 лет
возраст(x)-18лет)/42 , если 18 <= возраст(x) <= 60
1, если возраст(x) > 60 }
And for compactness, let
И для компактности
a = X is TALL and X is OLD
b = X is TALL or X is OLD
c = not (X is TALL)
a = X - ВЫСОКИЙ и X - СТАРЫЙ
b = X - ВЫСОКИЙ или X - СТАРЫЙ
c = не (X - ВЫСОКИЙ)
Then we can compute the following values.
Затем мы можем вычислять следующие значения.
рост возраст X - ВЫСОКИЙ X - СТАРЫЙ a b c
------------------------------------------------------------------------
95 65 0.00 1.00 0.00 1.00 1.00
163 30 0.21 0.29 0.21 0.29 0.79
173 27 0.38 0.21 0.21 0.38 0.62
175 32 0.42 0.33 0.33 0.42 0.58
182 31 0.54 0.31 0.31 0.54 0.46
215 45 1.00 0.64 0.64 1.00 0.00
100 4 0.00 0.00 0.00 0.00 1.00
An excellent introductory article is:
Превосходная вводная статья:
Bezdek, James C, "Fuzzy Models --- What Are They, and Why?", IEEE
Transactions on Fuzzy Systems, 1:1, pp. 1-6, 1993.
For more information on fuzzy logic operators, see:
Для подробной информации относительно нечетких логических операторов, см.:
Bandler, W., and Kohout, L.J., "Fuzzy Power Sets and Fuzzy Implication
Operators", Fuzzy Sets and Systems 4:13-30, 1980.
Dubois, Didier, and Prade, H., "A Class of Fuzzy Measures Based on
Triangle Inequalities", Int. J. Gen. Sys. 8.
The original papers on fuzzy logic include:
Первоначальные статьи по нечеткой логике:
Zadeh, Lotfi, "Fuzzy Sets," Information and Control 8:338-353, 1965.
Zadeh, Lotfi, "Outline of a New Approach to the Analysis of Complex
Systems", IEEE Trans. on Sys., Man and Cyb. 3, 1973.
Zadeh, Lotfi, "The Calculus of Fuzzy Restrictions", in Fuzzy Sets and
Applications to Cognitive and Decision Making Processes, edited
by L. A. Zadeh et. al., Academic Press, New York, 1975, pages 1-39.
Что такое нечеткие числа и нечеткая арифметика ?
Date: 15-APR-93
Fuzzy numbers are fuzzy subsets of the real line. They have a peak or
plateau with membership grade 1, over which the members of the
universe are completely in the set. The membership function is
increasing towards the peak and decreasing away from it.
Нечеткие числа - нечеткие подмножества реальной линии. Они имеют пик, или плато со степенью 1, под которым элементы всей совокупности являются полностью в множестве. Функция принадлежности увеличивается до пику и уменьшается далее.
Fuzzy numbers are used very widely in fuzzy control applications. A typical
case is the triangular fuzzy number
Нечеткие числа используются очень широко в приложениях нечеткого управления. Типичный случай - треугольное нечеткое число
1.0 + +
| / \
| / \
0.5 + / \
| / \
| / \
0.0 +-------------+-----+-----+--------------
| | |
5.0 7.0 9.0
which is one form of the fuzzy number 7. Slope and trapezoidal functions
are also used, as are exponential curves similar to Gaussian probability
densities.
которое является одной формой нечеткого числа 7. Наклонные и трапецоидальные функции также используются, как - экспоненты, подобные Гауссовым плотностям вероятности.
For more information, see:
Dubois, Didier, and Prade, Henri, "Fuzzy Numbers: An Overview", in
Analysis of Fuzzy Information 1:3-39, CRC Press, Boca Raton, 1987.
Dubois, Didier, and Prade, Henri, "Mean Value of a Fuzzy Number",
Fuzzy Sets and Systems 24(3):279-300, 1987.
Kaufmann, A., and Gupta, M.M., "Introduction to Fuzzy Arithmetic",
Reinhold, New York, 1985.
Что такое нечеткое множество?
The very basic notion of fuzzy systems is a Fuzzy (sub)set.
In classical mathematics we are familiar with what we call crisp sets.
Главное базисное понятие нечеткихсистем - Нечеткое (под) множество.
В классической математике мы знакомы с тем, что мы вызываем четкие множество.
Для примера:
First we consider a set X of all real numbers between 0 and 10 which we call the universe of discourse. Now, let's define a subset A of X of all real-numbers in the range between 5 and 8.
Сначала мы рассматрим множество X всех вещественных чисел между 0 и 10, которые мы назовем областью исследования. Теперь, давайте определим подмножество X всех вещественных чисел в амплитуде между 5 и 8.
A = [5,8]
We now show the set A by its characteristic function, i.e. this function assigns a number 1 or 0 to each element in X, depending on whether the element is in the subset A or not. This results in the following figure:
Мы теперь покажем множество A символическая функция, то есть эта функция приписывает число 1 или 0 к каждому элементу в X, в зависимости от того, находится ли элемент в подмножестве А или нет. Это приводит к следующей диаграмме:
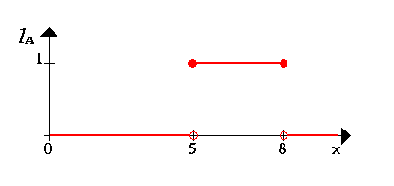
We can interpret the elements which have assigned the number 1 as The elements are in the set A and the elements which have assigned the number 0 as The elements are not in the set A.
Мы можем интерпретировать элементы, которым назначено число 1, как элементы которые находятся в множестве А и элементы, которым назанчено число 0, как элементы не в множестве A.
This concept is sufficient for many areas of applications. But we can easily find situations where it lacks in flexibility. In order to show this consider the following example on the next page:
Эта концепция достаточно для многих областей приложений. Но мы можем легко найти ситуации, где теряется гибкость. Чтобы показать это рассматрим следующий пример:
In this example we want to describe the set of young people. More formally we can denote
В этом примере мы хотим описать множество молодых людей. Более формально мы можем обозначить
B = {множество молодых людей}
Since - in general - age starts at 0 the lower range of this set ought to be clear. The upper range, on the other hand, is rather hard to define. As a first attempt we set the upper range to, say, 20 years. Therefore we get B as a crisp interval, namely:
Поскольку - вообще - возраст начинается с 0 нижняя граница этого множества должна быть нулевой. Верхнию границу, с другой стороны, надо определить. На первый разопределим верхнию границу множества, скажем, 20 лет. Следовательно мы получаем B как четкий интервал, а именно:
B = [0,20]
Now the question arises: why is somebody on his 20th birthday young and right on the next day not young? Obviously, this is a structural problem, for if we move the upper bound of the range from 20 to an arbitrary point we can pose the same question.
Теперь вопрос возникает: почему - кто-то на его 20-ом дне рождения, молодой, а на на следующий день не молодой? Очевидно, это - структурная проблема, поскольку, если мы перемещаем верхнюю границу от 20 до произвольной точки, мы можем излагать тот же самый вопрос.
A more natural way to construct the set B would be to relax the strict separation between young and not young. We will do this by allowing not only the (crisp) decision YES he/she is in the set of young people or NO he/she is not in the set of young people but more flexible phrases like Well, he/she belongs a little bit more to the set of young people or NO, he/she belongs nearly not to the set of young people.
Более естественный способ создать множество B состоит в том, чтобы ослабить строгое разделение между молодыми и не молодыми. Мы будем делать это, позволяя не только (четкое) решение ДА он/она находится в множестве молодых, или НЕТ он / она не в множестве молодых, но более гибких фраз подобно Хорошо, он/она принадлежит немного больше к множеству молодых или НЕТ, он/она почти не принадлежит к множеству молодых.
As stated in the introduction we want to use fuzzy sets to make computers smarter, we now have to code the above idea more formally. In our first example we coded all the elements of the Universe of Discourse with 0 or 1. A straight way to generalize this concept is to allow more values between 0 and 1. In fact, we even allow infinite many alternatives between 0 and 1, namely the unit interval I = [0, 1].
Как заявлено во введении мы хотим использовать нечеткие множества, чтобы делать компьютеры более интеллектуальными, мы теперь должны закодировать вышеупомянутую идею более формально. В нашем первом примере мы кодировали все элементы Области исследования 0 или 1. Прямой путь обобщить эту концепцию состоит в том, чтобы позволить большее количество значений между 0 и 1. Фактически, мы даже позволяем бесконечные многие варианты между 0 и 1, а именно единичный интервал I = [0, 1].
The interpretation of the numbers now assigned to all elements of the Universe of Discourse is much more difficult. Of course, again the number 1 assigned to an element means that the element is in the set B and 0 means that the element is definitely not in the set B. All other values mean a gradual membership to the set B.
Интерпретация чисел теперь назначеная всем элементам Области исследования, намного более трудная. Конечно, снова число 1 назначено элементу как способ определить элемент который находится в множестве B и 0 способ, при котором элемент не определен в множестве B. Все другие значения означают постепенную принадлежность к множеству B.
To be more concrete we now show the set of young people similar to our first example graphically by its characteristic function.
Чтобы быть более конкретным, мы теперь показываем множество молодых, подобно в нашем первом примере, графически при помощи символической функций.
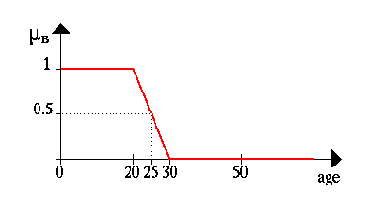
This way a 25 years old would still be young to a degree of 50 percent.
Этим способом люди с 25 летним возрастом были бы все еще молоды на 50 процентов.
Now you know what a fuzzy set is. But what can you do with it? Continue to the next page !
Что такое нечеткое управление ?
Date: 17-MAR-95
The purpose of control is to influence the behavior of a system by
changing an input or inputs to that system according to a rule or
set of rules that model how the system operates. The system being
controlled may be mechanical, electrical, chemical or any combination
of these.
Целью управления является влияние на поведение системы, изменяя вход или входы системы согласно правилу или множеству правил, согласно модели, по которой система функционирует. Управляемая система может быть механическая, электрическая, химическая или любая комбинация их.
Classic control theory uses a mathematical model to define a relationship
that transforms the desired state (requested) and observed state (measured)
of the system into an input or inputs that will alter the future state of
that system.
Классическая теория управления использует математическую модель, чтобы определить связь, которая преобразовывает желательное состояние (запрошенное) и наблюдаемое состояние (измеряемое) системы во вход или входы, которые изменят будущее состояние той системы.
reference----->0------->( SYSTEM ) -------+----------> output
^ |
| |
+--------( MODEL )<--------+feedback
ссылка ----->0------->( СИСТЕМА )-------+----------> выход
^ |
| |
+--------( МОДЕЛЬ)<--------+обратная связь
The most common example of a control model is the PID (proportional-integral-
derivative) controller. This takes the output of the system and compares
it with the desired state of the system. It adjusts the input value based
on the difference between the two values according to the following
equation.
Наиболее общий пример модели управления - PID контроллер. Он берет вывод системы и сравнивает его с желательным состоянием системы.
ОН корректирует значение входа, основанное на разности между двумя значениями согласно следующему уравнению.
output = A.e + B.INT(e)dt + C.de/dt
Where, A, B and C are constants, e is the error term, INT(e)dt is the
integral of the error over time and de/dt is the change in the error term.
Где, A, B и C - константы, e - погрешность, INT(e)dt - интеграл погрешности за какое-то время и de/dt - изменение в погрешности.
The major drawback of this system is that it usually assumes that the system
being modelled in linear or at least behaves in some fashion that is a
monotonic function. As the complexity of the system increases it becomes
more difficult to formulate that mathematical model.
Большой недостаток этой системы состоит в том, что она обычно принимает, что система, моделируется как линейная или по крайней мере ведет себя в некотором режиме, который является монотонной функцией. При увеличений сложности системы становится более трудным сформулировать эту математическую модель.
Fuzzy control replaces, in the picture above, the role of the mathematical
model and replaces it with another that is build from a number of smaller
rules that in general only describe a small section of the whole system. The
process of inference binding them together to produce the desired outputs.
Нечеткое управление заменяет, в диаграмме выше, роль математической модели и замяет это на другую, которая строиться на ряде меленьких правил, которые вообще только описывают малый раздел всей системы. Процесс заключения, связывает их вместе, чтобы произвести желательные выводы.
That is, a fuzzy model has replaced the mathematical one. The inputs and
outputs of the system have remained unchanged.
То есть нечеткая модель заменила математическую. Входы и выводы системы остались неизменяемыми.
The Sendai subway is the prototypical example application of fuzzy control.
Sendai подземка - примера нечткого управления.
References:
Yager, R.R., and Zadeh, L. A., "An Introduction to Fuzzy Logic
Applications in Intelligent Systems", Kluwer Academic Publishers, 1991.
Dimiter Driankov, Hans Hellendoorn, and Michael Reinfrank,
"An Introduction to Fuzzy Control", Springer-Verlag, New York, 1993.
316 pages, ISBN 0-387-56362-8. [Discusses fuzzy control from a
theoretical point of view as a form of nonlinear control.]
C.J. Harris, C.G. Moore, M. Brown, "Intelligent Control, Aspects of
Fuzzy Logic and Neural Nets", World Scientific. ISBN 981-02-1042-6.
T. Terano, K. Asai, M. Sugeno, editors, "Applied Fuzzy Systems",
translated by C. Ascchmann, AP Professional. ISBN 0-12-685242-1.
Как определить значения принадлежность?
Date: 15-APR-93
Determination methods break down broadly into the following categories:
1. Subjective evaluation and elicitation
As fuzzy sets are usually intended to model people's cognitive states,
they can be determined from either simple or sophisticated elicitation
procedures. At they very least, subjects simply draw or otherwise specify
different membership curves appropriate to a given problem. These
subjects are typcially experts in the problem area. Or they are given a
more constrained set of possible curves from which they choose. Under
more complex methods, users can be tested using psychological methods.
Множество методов определения разбиваются на следующие категории:
1. Субъективная оценка и извлечение
Поскольку нечеткие множества обычно имеются в виду, чтобы моделировать распознование человека, они могут быть определены или простой или сложной процедурой извлечения. Условия просто рисуются или иначе точно определяют различные кривые принадлежности, соответствующие данной задаче. Эти условия задаются экспертами в прикладной области. Или они дают более вынужденное множество возможных кривых из которых они выбирают. Ниже более комплексные методы, пользователи могут проверить, используя психологические методы
2. Ad-hoc forms
While there is a vast (hugely infinite) array of possible membership
function forms, most actual fuzzy control operations draw from a very
small set of different curves, for example simple forms of fuzzy numbers
(see [7]). This simplifies the problem, for example to choosing just the
central value and the slope on either side.
2. Формы для данного случая
В то время как имеется крупная (чрезвычайно бесконечная) таблица возможных форм функции принадлежности, наиболее актуальные операции нечеткого управления рисуются из очень малого множества различных кривых, например простые формы нечетких чисел (см. [7]).
Это упрощает задачу, например по выбору только центрального значения и наклона с обеих сторон.
3. Converted frequencies or probabilities
Sometimes information taken in the form of frequency histograms or other
probability curves are used as the basis to construct a membership
function. There are a variety of possible conversion methods, each with
its own mathematical and methodological strengths and weaknesses.
However, it should always be remembered that membership functions are NOT
(necessarily) probabilities. See [10] for more information.
3. Преобразованные частоты или вероятности
Иногда информация, берется в форме гистограмм частоты или других кривых вероятности используется как базис, чтобы создать функцию принадлежности. Имеется ряд возможных методов конверсии, каждый с собственными математическими и методологическими силами и слабостями. Однако, это нужно всегда помнить, что функции принадлежности - НЕ (обязательно) вероятности. См. [10] для подробной информации.
4. Physical measurement
Many applications of fuzzy logic use physical measurement, but almost
none measure the membership grade directly. Instead, a membership
function is provided by another method, and then the individual
membership grades of data are calculated from it (see FUZZIFICATION in [4]).
5. Learning and adaptation
For more information, see:
4. Физическое измерение
Много приложений нечеткой логики используют физическое измерение, но почти ни одно не измеряют степень принадлежности непосредственно. Вместо этого, функция принадлежности обеспечивается другим методом, и затем индивидуальные степени принадлежности данных вычислены из этого (см. НЕЧЕТКОСТЬ в [4]).
5. Изучение и адаптация
Для подробной информации, см.:
Roberts, D.W., "Analysis of Forest Succession with Fuzzy Graph Theory",
Ecological Modeling, 45:261-274, 1989.
Turksen, I.B., " Measurement of Fuzziness: Interpretiation of the Axioms
of Measure", in Proceeding of the Conference on Fuzzy Information and
Knowledge Representation for Decision Analysis, pages 97-102, IFAC,
Oxford, 1984.
[10] What is the relationship between fuzzy truth values and probabilities?
Каково соотношение между нечеткими значениями истинности и вероятностью ?
Date: 21-NOV-94
This question has to be answered in two ways: first, how does fuzzy
theory differ from probability theory mathematically, and second, how
does it differ in interpretation and application.
На этот вопрос можно отвечать двумя способами: первый, как нечеткая теория отличается из теории вероятности математически, и второй, как это отличается по интерпретации и приложению.
At the mathematical level, fuzzy values are commonly misunderstood to be
probabilities, or fuzzy logic is interpreted as some new way of handling
probabilities. But this is not the case. A minimum requirement of
probabilities is ADDITIVITY, that is that they must add together to one, or
the integral of their density curves must be one.
На математическом уровне, нечеткие значения обычно неправильно истолковываются, чтобы быть вероятностями, или размытая логика интерпретируется так некоторый новый способ обработки вероятностей. Но дело обстоит не так. Минимальное требование вероятностей - АДДИТИВНОСТЬ, которая является, что они должны добавиться вместе к одному, или интеграл их кривых плотности должен быть один.
But this does not hold in general with membership grades. And while
membership grades can be determined with probability densities in mind (see
[11]), there are other methods as well which have nothing to do with
frequencies or probabilities.
Но это не проходит вообще со степенями принадлежности. И в то время как степени принадлежности могут быть определены с плотностями вероятности в памяти (см. [11]), имеются другие методы также, которые не имеют никакого отношения к частотам или вероятностям.
Because of this, fuzzy researchers have gone to great pains to distance
themselves from probability. But in so doing, many of them have lost track
of another point, which is that the converse DOES hold: all probability
distributions are fuzzy sets! As fuzzy sets and logic generalize Boolean
sets and logic, they also generalize probability.
Из-за этого, нечеткие исследователи приложили большие усилия к расстоянию самостоятельно из вероятности. Но в так выполнении, многие из их потеряли след другой точки, которая является той обратной теоремой, проводит: все распространения вероятности - нечеткие множества! Поскольку нечеткие множества и логика обобщают Булевы наборы и логику, они также обобщают и вероятность.
In fact, from a mathematical perspective, fuzzy sets and probability exist
as parts of a greater Generalized Information Theory which includes many
formalisms for representing uncertainty (including random sets,
Demster-Shafer evidence theory, probability intervals, possibility theory,
general fuzzy measures, interval analysis, etc.). Furthermore, one can
also talk about random fuzzy events and fuzzy random events. This whole
issue is beyond the scope of this FAQ, so please refer to the following
articles, or the textbook by Klir and Folger (see [16]).
Фактически, из математической перспективы, нечеткие множества и вероятность существуют как части большей Обобщенной Теории информации, которая включает много формализма для представления неопределенности (включая произвольные наборы, Demster-Shafer теория доказательства, интервалы вероятности, теория возможности, общие нечеткие критерии, анализ интервала, и т.д.). Кроме того, можно также говорить относительно произвольных нечетких результатов и нечетких произвольных результатов. Этот целый выпуск - вне области действия этого FAQ, так пожалуйста обратитесь(отнеситесь) к следующим статьям(изделиям), или учебнику Klir и Folger (см. [16]).
Semantically, the distinction between fuzzy logic and probability theory
has to do with the difference between the notions of probability and a
degree of membership. Probability statements are about the likelihoods of
outcomes: an event either occurs or does not, and you can bet on it. But
with fuzziness, one cannot say unequivocally whether an event occured or
not, and instead you are trying to model the EXTENT to which an event
occured. This issue is treated well in the swamp water example used by
James Bezdek of the University of West Florida (Bezdek, James C, "Fuzzy
Models --- What Are They, and Why?", IEEE Transactions on Fuzzy Systems,
1:1, pp. 1-6).
Семантически, различие между нечеткой логикой и теорией вероятности должно делать с разностью между понятиями вероятности и степени принадлежности. Формулировка Вероятности - относительно вероятностей результатов: результат или происходит или не происходит, и Вы можете ставка на этом. Но с нечеткостью, не может говорить ясно, происходил ли результат или нет, и взамен Вы испытываете моделировать ОБЪЕМ, к которому результат происходил. Этот выпуск трактуется хорошо в примере воды болота, используемом Джеймсом Бездек Университета Запада Флорида (Bezdek, Джеймс К, " Нечеткие модели ---, что Является Ими, и Почему? ", Труды ИИЭРА на Размытых Системах,
1:1, pp. 1-6).
Delgado, M., and Moral, S., "On the Concept of Possibility-Probability
Consistency", Fuzzy Sets and Systems 21:311-318, 1987.
Dempster, A.P., "Upper and Lower Probabilities Induced by a Multivalued
Mapping", Annals of Math. Stat. 38:325-339, 1967.
Henkind, Steven J., and Harrison, Malcolm C., "Analysis of Four
Uncertainty Calculi", IEEE Trans. Man Sys. Cyb. 18(5)700-714, 1988.
Kamp`e de, F'eriet J., "Interpretation of Membership Functions of Fuzzy
Sets in Terms of Plausibility and Belief", in Fuzzy Information and
Decision Process, M.M. Gupta and E. Sanchez (editors), pages 93-98,
North-Holland, Amsterdam, 1982.
Klir, George, " Is There More to Uncertainty than Some Probability
Theorists Would Have Us Believe?", Int. J. Gen. Sys. 15(4):347-378, 1989.
Klir, George, "Generalized Information Theory", Fuzzy Sets and Systems
40:127-142, 1991.
Klir, George, "Probabilistic vs. Possibilistic Conceptualization of
Uncertainty", in Analysis and Management of Uncertainty, B.M. Ayyub et.
al. (editors), pages 13-25, Elsevier, 1992.
Klir, George, and Parviz, Behvad, "Probability-Possibility
Transformations: A Comparison", Int. J. Gen. Sys. 21(1):291-310, 1992.
Kosko, B., "Fuzziness vs. Probability", Int. J. Gen. Sys.
17(2-3):211-240, 1990.
Puri, M.L., and Ralescu, D.A., "Fuzzy Random Variables", J. Math.
Analysis and Applications, 114:409-422, 1986.
Shafer, Glen, "A Mathematical Theory of Evidence", Princeton University,
Princeton, 1976.
[11] Are there fuzzy state machines?
Существуют ли нечеткие автоматы ?
Date: 15-APR-93
Yes. FSMs are obtained by assigning membership grades as weights to the
states of a machine, weights on transitions between states, and then a
composition rule such as MAX/MIN or PLUS/TIMES (see [4]) to calculate new
grades of future states. Refer to the following article, or to Section
III of the Dubois and Prade's 1980 textbook (see [16]).
Да. FSMs можно получить, назначая степени принадлежности как веса к состояниям машины, веса на переходах между состояниями, и затем композиционное правило типа МАКСИМУМА-МИНИМУМА или ПЛЮСА/ВРЕМЕН (см. [4]) для того чтобы вычислять новые степени будущих состояний. Обратитесь к следующей статье), или к части III Dubois и учебника 1980 Прад (см. [16]).
Gaines, Brian R., and Kohout, Ladislav J., "Logic of Automata",
Int. J. Gen. Sys. 2(4):191-208, 1976.
Нечеткая логика - новая мощная технология
Fuzzy Logic has emerged as a a profitable tool for the controlling of subway systems and complex industrial processes, as well as for household and entertainment electronics, diagnosis systems and other expert systems. Although, Fuzzy Logic was invented in the United States the rapid growth of this technology has started from Japan and has now again reached the USA and Europe also.
Нечеткая логика применяется как выгодный инструмент для управления систем подземки и комплексных индустриальных процессов, также для домашнего хозяйства и электроники развлечения, систем обнаружения ошибок и других экспертных систем. Хотя, Нечеткая Логика была изобретена в Соединенных Штатах, быстрый рост этой технологии начался в Японии и теперь снова достиг США и Европы также.
Fuzzy Logic is still booming in Japan, the number of letters patent applied for increases exponentially. The main part deals with rather simple applications of Fuzzy Control.
Нечеткая Логика все еще быстро развивающаяся в Японии, количество патентов увеличивается по экспоненте. Основная часть имеет дело довольно с простыми приложениями Нечеткого Управления.
Fuzzy has become a key-word for marketing. Electronic articles without Fuzzy-component gradually turn out to be dead stock. As a gag, that shows the popularity of Fuzzy Logic, there even exists a toiletpaper with "Fuzzy Logic" printed on it.
Нечеткость стало ключевым словом для маркетинга. Электронные статьи без нечеткого компонента постепенно, окажется, мертвая акция. Пример, который показывает, популярность Нечеткой Логики, даже существует туалетная бумага с " Нечеткой Логикой " напечатанный на ней.
In Japan Fuzzy-research is widely supported with a huge budget. In Europe and the USA efforts are being made to catch up with the tremendous japanese success. For instance, the NASA space agency is engaged in applying Fuzzy Logic for complex docking-maneuvers.
В исследования Японии по нечеткой логике широко поддержаны с огромным бюджетом.
В Европе и усилиях США сделаны, чтобы догнать огромный японский успех. Например, агентство NASA занято применением Нечеткой Логики для комплексной стыковки - маневров.
Fuzzy Logic is basically a multivalued logic that allows intermediate values to be defined between conventional evaluations like yes/no, true/false, black/white,
etc. Notions like rather warm or pretty cold can be formulated mathematically and processed by computers. In this way an attempt is made to apply a more human-like way of thinking in the programming of computers.
Нечеткая Логика - в основном многозначная логика, которая позволяет промежуточным значениям быть определенным между стандартными оценками(вычислениями) подобно да/нет, истинно/ложь, черный / белый, и т.д. Понятия подобно скорее тепло или довольно холодно может быть сформулированы математически и обработаны компьютерами. Таким образом попытка сделана, чтобы применить более человеческий-подобное мышление в программировании компьютеров.
Fuzzy Logic was initiated in 1965 by Lotfi A. Zadeh, professor for computer science at the University of California in Berkeley.
Нечеткая Логика открыта в 1965 Лофти А.Заде ( Иран ), профессором информатики в Университете Калифорнии в Беркли.
Нечеткое управление
Fuzzy controllers are the most important applications of fuzzy theory. They work rather different than conventional controllers; expert knowledge is used instead of differential equations to describe a system. This knowledge can be expressed in a very natural way using linguistic variables, which are described by fuzzy sets.
Нечеткие контроллеры - наиболее важные приложения нечеткой теории. Они работают довольно отлично чем стандартные контроллеры; экспертное знание используется вместо дифференциально-разностных уравнений, чтобы описать систему. Это знание может быть выражено в очень естественном способе использовать лингвистические переменные, которые описаны размытыми множествами.
Операции с нечеткими множествами
Now that we have an idea of what fuzzy sets are, we can introduce basic operations on fuzzy sets. Similar to the operations on crisp sets we also want to intersect, unify and negate fuzzy sets. In his very first paper about fuzzy sets, L. A. Zadeh suggested the minimum operator for the intersection and the maximum operator for the union of two fuzzy sets. It is easy to see that these operators coincide with the crisp unification, and intersection if we only consider the membership degrees 0 and 1.
Теперь, когда мы имеем, идею что такое нечеткие множества, мы можем вводить основные операции на нечетких множествах. Подобно операциям на четких множествах мы также хотим определить пересечение, объединение и отрицание на нечетких множествах. В очень ранней статье относительно нечетких множеств, Заде предложил оператор минимума для пересечения и оператора максимума для объединения двух нечетких множеств. Просто видеть, что эти операторы совпадают с четким объединением, и пересечением, если мы только рассматриваем степень принадлежности к 0 и 1.
In order to clarify this, we give a few examples. Let A be a fuzzy interval between 5 and 8 and B be a fuzzy number about 4. The corresponding figures are shown below.
Чтобы разъяснять это, мы дадим несколько примеров. Допустим А есть нечеткий интервал между 5 и 8 и B нечеткое число приблизительно 4. Соответствующие диаграммы показаны ниже.
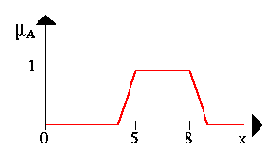
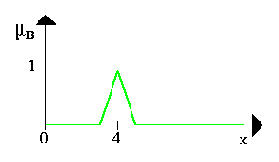
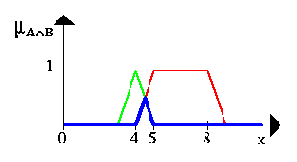
The following figure shows the fuzzy set between 5 and 8 AND about 4 (notice the blue line).
Следующая диаграмма показывает нечеткое множество между 5 и 8 И ( AND - пересечение ) приблизительно 4 ( синия линия).
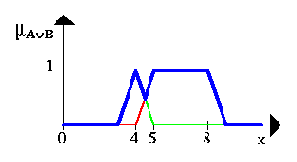
The Fuzzy set between 5 and 8 OR about 4 is shown in the next figure (again, it is the blue line).
Нечеткое множество между 5 и 8 ИЛИ (OR-объединение) приблизительно 4 показывается в следующей диаграмме (снова, синей линией).
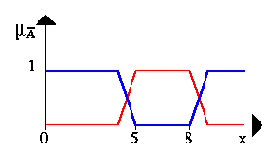
This figure gives an example for a negation. The blue line is the NEGATION of the fuzzy set A.
Эта диаграмма дает пример для отрицания. Синяя линия - ОТРИЦАНИЕ нечеткого множества A.
Определения
Def 2.1 Intersection of Sets
We call a new set generated from two given sets A and B intersection of A and B, if the new set contains exactly those elements that are contained in A and in B.
Def 2.1 Пересечение Множеств
Мы называем новое множество, сгенерированное из двух данных множеств А и B пересечением А и B, если новое множество содержит точно те элементы, которые содержатся в А и в B.
Def 2.2 Unification of Sets
We call a new set generated from two given sets A and B unification of A and B, if the new set contains all elements that are contained in A or in B or in both.
Def 2.2 Объединение Множеств
Мы называем новое множество, сгенерированное из двух данных наборов А и B объединение А и B, если новое множество содержит все элементы, которые содержатся в А или в B или в обоих.
Def 2.3 Negation of Sets
We call a new set containing all elements which are in the universe of discourse but not in the set A the negation of A.
Def 2.3 Отрицание Множеств
Мы называем новое множество, содержащее все элементы, которые находятся в области исследования, но не в множестве А отрицанием A.
Def 3.1 Linguistic Variable
A linguistic variable is a quintuple (X,T(X),U,G,M,), where X is the name of the variable, T(X) is the term set, i.e. the set of names of linguistic values of X, U is the universe of discourse, G is the grammer to generate the names and M is a set of semantic rules for associating each X with its meaning.
Def 3.1 Лингвистическая Переменная
Лингвистическая переменная - пятерка (X, T (X), U, G, М,), где X - имя переменной, T(X) - члены множества, то есть множество имен лингвистических значений X, U - область исследования, G - грамматика, чтобы генерировать имена, и М - множество семантических правил для соединения каждого X со значением.
FAQ Fuzzy Logic - FAQ по нечеткой логике
Перевод Анисимов С.Ю. 1998-07-30. Выдержки из FAQ.
Используйте newsgroup comp.ai.fuzzy для обсуждения вопросов связанных с фази-логикой.
Автоматически сгенерированная HTML версия Нечеткой Логики FAQ доступна WWW как часть AI-касающейся FAQs Мозаик страницы. URL для этого ресурса
http://www.cs.cmu.edu/Web/Groups/AI/html/faqs/top.html
Непосредственно на FAQ URL http://www.cs.cmu.edu/Web/Groups/AI/html/faqs/ai/fuzzy/part1/faq.html
Если Вы должны цитировать FAQ по некоторым причинам, используйте следующий формат:
Mark Kantrowitz, Erik Horstkotte, and Cliff Joslyn, "Answers to
Frequently Asked Questions about Fuzzy Logic and Fuzzy Expert Systems",
comp.ai.fuzzy, <month>, <year>,
ftp.cs.cmu.edu:/user/ai/pubs/faqs/fuzzy/fuzzy.faq,
mkant+fuzzy-faq@cs.cmu.edu.
*** Содержание:
[1] Какова цель этой newsgroup?
[2] Что является нечеткой логикой?
[3] Где нечеткая логика используется?
[4] Что такое - нечеткая экспертная система?
[5] Где нечеткие экспертные системы используются?
[6] Что является нечетким управлением?
[7] Каковы нечеткие числа и нечеткая арифметика?
[8] Не "нечеткая логика " свойственное противоречие?
Почему любой хотел бы нечеткости в логике?
[9] Как значения принадлежности определены?
[10] Какова связь между нечеткими значениями истинности и вероятностями?
[11] Имеются ли нечеткие конечные автоматы?
[12] Какова теория возможности?
[13] Как я могу получать копию трудов для <x>?
[14] Нечеткие BBS Системы, серверы почты и FTP Архивы
[15] Списки адресатов
[16] Библиография
[17] Журналы и Технические Информационные бюллетени
[18] Профессиональные Организации
[19] Компании, обеспечивающие Нечеткие Инструментальные средства
[20] Нечеткие Исследователи
[21] Статья Елкана " Парадоксальный Успех Нечеткой Логики "
[22] Глоссарий
[24] Где посылать запросы статьи (cfp) и запросы на участие
Инвертированный маятник
Пример: Инвертированный маятник
The problem is to balance a pole on a mobile platform that can move in only two directions, to the left or to the right.
Задача должна балансировать полюс на подвижной платформе, которая может перемещать в только в двух направлениях, налево или направо
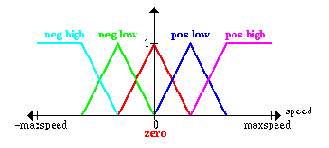
First of all, we have to define (subjectively) what high speed, low speed etc. of the platform is; this is done by specifying the membership functions for the fuzzy_sets
Прежде всего мы должны определить (субъективно) что такое высокая скорость, низкая скорость и т.д. платформы; это выполнено, при помощи определения функции принадлежности для нечеткого_множества
· negative high (cyan)
· negative low (green)
· zero (red)
· positive low (blue)
· positive high (magenta)
· отрицательно высокая скорость (голубым)
· отрицательно низкая (зеленым)
· Нулевая (красным)
· Положительно низкая (синим)
· Положительно высокая (сиреневым)
The same is done for the angle between the platform and the pendulum and the angular velocity of this angle:
Тот же самый выполнен для угла между платформой и маятником и угловым ускорением этого угла:
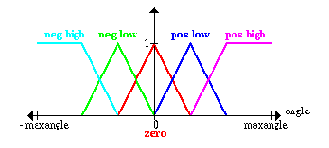
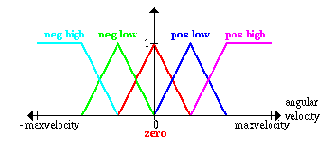
Please notice that, to make it easier, we assume that in the beginning the pole is in a nearly upright position so that an angle greater than, say, 45 degrees in any direction can - by definition - never occur.
Пожалуйста заметьте, что, чтобы делать это проще, мы принимаем, что в начале полюс находится в почти вертикальном положении так, чтобы угол большее чем, скажем, 45 градусов в любом направлении мог - по определению - никогда не мог быть.
On the next page we will set up some rules that we wish to apply in certain situations.
Далее мы установим некоторые правила, которые мы желаем применить в некоторых ситуациях.
Now we give several rules that say what to do in certain situations:
Теперь мы даем несколько правил, которые говорят, что делать в некоторых ситуациях:
Consider for example that the pole is in the upright position (angle is zero) and it does not move (angular velocity is zero). Obviously this is the desired situation, and therefore we don't have to do anything (speed is zero).
Предположим например, что полюс находится в вертикальном положении (угол - нуль) и он не двигается (угловое ускорение - нуль). Очевидно это - желательная ситуация, и следовательно мы не должны делать что - нибудь (скорость - нуль).
Let's consider another case: the pole is in upright position as before but is in motion at low velocity in positive direction. Naturally we would have to compensate the pole's movement by moving the platform in the same direction at low speed.
Давайте рассматривать другой случай: полюс находится в вертикальном положении как прежде, но находится в движении с низким ускорением в положительном направлении. Естественно мы были бы должны компенсировать перемещение полюса, перемещая платформу в том же самом направлении с низкой скоростью.
So far we've made up two rules that can be put into a more formalized form like this:
Пока мы составили два правила, которые могут быть помещены в более формализованную форму подобно этому:
· If angle is zero and angular velocity is zero then speed shall be zero.
· If angle is zero and angular velocity is pos. low then speed shall be pos. low.
· Если угол - нуль, и угловая скорость - нуль, тогда скорость, будет нуль.
· Если угол - нуль, и угловое ускорение - pos. Тогда низкая скорость должна быть pos.
Низко.
We can summarize all applicable rules in a table:
Мы можем суммировать все соответствующие правила в таблице:
| угол
|
скорость | NH NL Z PL PH
----------+------------------------------
у NH | NH
с NL | NL Z
к Z | NH NL Z PL PH
о PL | Z PL
р PH | PH
where NH is a (usual) abbreviation for negative high, NL for negative low etc.
Где NH - (обычное) сокращение для отрицательно высокой, NL для отрицательно низкой и т.д.
On the next pages we will show how these rules can be applied with concrete values for angle and angular velocity.
На следующих страницах мы покажем, как эти правила могут применяться с конкретными значениями для угла и углового ускорения.
We are going to define two explicit values for angle and angular velocity to calculate with. Consider the following situation:
Мы собираемся определить два явных значения для угла и углового ускорения, чтобы вычислять правила. Рассмотрим следующую ситуацию:
An actual value for angle:
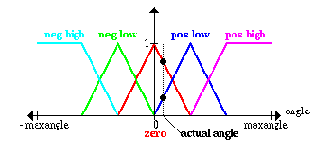
Фактическое значение для угла:
An actual value for angular velocity:
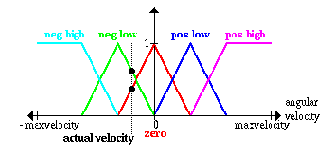
Фактическое значение для угловой скорости:
On the next page you will be able to watch how we apply our rules to this actual situation.
Далее Вы будете наблюдать, как мы применяем наши правила к этой фактической ситуации.
Let's apply the rule
Давайте применим правило
If angle is zero and angular velocity is zero then speed is zero
Если угол - нуль, и угловое ускорение - нуль, тогда скорость - нуль
to the values that we've selected on the previous page:
К значениям, которые мы выбрали на ранее:
Click on the symbol to see how the result develops:
Вот как результат разрабатывается:
1. Угол
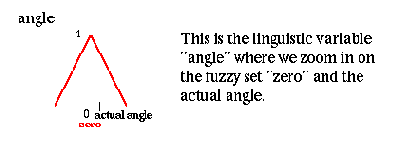
ноль; фактический угол.
Это - лингвистическая переменная "угол", здесь мы увеличиваем на нечетком множестве "нуль" и фактический угол.
2. Угол и угловое ускорение
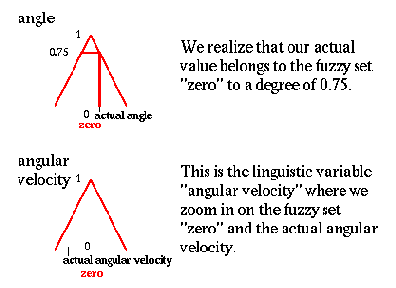
ноль; фактический угол.
Ноль; фактическое угловое ускорение
Мы реализуем, что наше фактическое значение принадлежит нечеткому множеству "нуль" со степенью 0.75
Это - лингвистическая переменная "уголовое ускорение", здесь мы увеличиваем на нечетком множестве "нуль" и фактическое уголовое ускорение.
3. Угол и угловое скорение
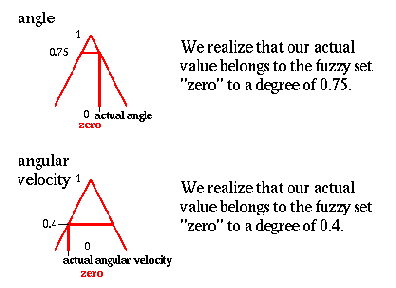
Мы реализуем, что наше фактическое значение принадлежит нечеткому множеству "нуль" со степенью 0.75
Мы реализуем, что наше фактическое значение принадлежит нечеткому множеству "нуль" со степенью 0.4
4. Угол и угловое ускорение
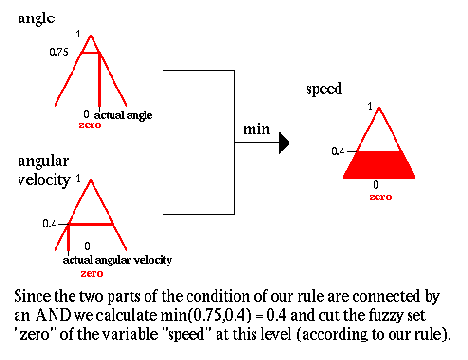
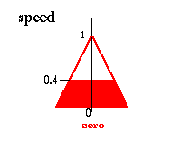
Так как две части условия нашего правила соединены, И мы вычисляем минимум (0.75,0.4) = 0.4 и обрезаем нечеткое множество "нуль" переменной "скорость" на этом уровне (согласно нашему правилу).
Only four rules yield a result (they fire), and we overlap them into one single result.
Только четыре правила производят результат (они огонь), и мы перекрываем их в один единственный результат.
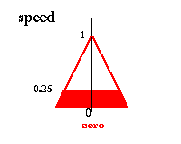
As shown on the previous page the result yielded by the rule
if angle is zero and angular velocity is zero then speed is zero
is:
Как показано выше результат, выданный правилом
Если угол - нуль, и угловое ускорение - нуль, тогда скорость - нуль:
The result yielded by the rule
if angle is zero and angular velocity is negative low then speed is negative low
is:
Результат, выданный правилом
Если угол - нуль, и угловое ускорение отрицательно низко, тогда скорость, отрицательна низка:
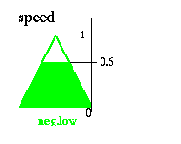
The result yielded by the rule
if angle is positive low and angular velocity is zero then speed is positive low
is:
Результат, выданный правилом
Если угол положителено низок, и угловое ускорение - нуль, тогда скорость, положительна низока:
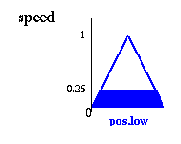
The result yielded by the rule
if angle is positive low and angular velocity is negative low then speed is zero
is:
Результат, выданный правилом
Если угол положительно низок, и угловое ускорение отрицательно низко, тогда скорость - нуль:
These four results overlapped yield the overall result:
Эти четыре результата, дают полный результат:
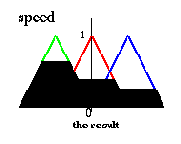
The result of the fuzzy controller so far is a fuzzy set (of speed), so we have to choose one representative value as the final output. There are several heuristic methods (defuzzification methods), one of them is e.g. to take the center of gravity of the fuzzy set:
Результат нечеткого контроллера пока - нечеткое множество (скорости), так что мы должны выбрать одно представляющее значение как окончательный результат. Имеются отдельные эвристические методы (defuzzification(не нечеткие) методы), по одному из которых должен например брать центр тяжести нечеткого множества:
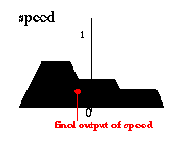
The whole procedure is called Mamdani controller.
Целая процедура называется Mamdani контроллером.
The next page deals with applications of Fuzzy Logic.
Далее имеем дело с приложениями Нечеткой Логики.
Приложения Нечеткой Логики
First, we shall look at the fitness of Fuzzy Control in general terms.
Сначала, мы рассмотрим пригодность Нечеткого Управления общим условиям.
The employment of Fuzzy Control is commendable...
· for very complex processes, when there is no simple mathematical model
· for highly nonlinear processes
· if the processing of (linguistically formulated) expert knowledge is to be performed
Использование Нечеткого Управления - похвально ...
· Для очень комплексных процессов, когда нет простой математической модели
· Для очень нелинейных процессов
· Если обработки (лингвистически сформулированно) экспертного знания должна выполниться
The employment of Fuzzy Control is no good idea if...
· conventional control theory yields a satisfying result
· an easily solvable and adequate mathematical model already exists
· the problem is not solvable
Использование Нечеткого Управления не имеет смысла если ...
· Стандартная теория управления производит удовлетворяющий результат
· Легко разрешимая и адекватная математическая модель уже существует
· Задача не разрешима
This concludes our brief course
This concludes our brief course in Fuzzy Logic and Fuzzy Control so far. We hope that you enjoyed it and that the explanations were of some help to you.
Здесь мы кончаем наш краткий курс по Нечеткой Логике и Нечеткому Управлению пока. Мы надеемся, что Вы наслаждались этим и что объяснения принесли некоторую помощь Вам.