Организация знаний в рабочей системе
Рабочая память (РП) экспертных систем предназначена для хранения данных. Данные в рабочей памяти могут быть однородны или разделяются на уровни по типам данных. В последнем случае на каждом уровне рабочей памяти хранятся данные соответствующего типа. Выделение уровней усложняет структуру экспертной системы, но делает систему более эффективной. Например, можно выделить уровень планов , уровень агенды (упорядоченного списка правил, готовых к выполнению) и уровень данных предметной области (уровень решений).
В современных экспертных системах данные в рабочей памяти рассматриваются как изолированные или как связанные. В первом случае рабочая память состоит из множества простых элементов , а во втором - из одного или нескольких (при нескольких уровнях в РП) сложных элементов (например, объектов). При этом сложный элемент соответствует множеству простых, объединенных в единую сущность. Теоретически оба подхода обеспечивают полноту, но использование изолированных элементов в сложных предметных областях приводит к потере эффективности.
Данные в РП в простейшем случае являются константами и (или) переменными. При этом переменные могут трактоваться как характеристики некоторого объекта, а константы - как значения соответствующих характеристик. Если в РП требуется анализировать одновременно несколько различных объектов, описывающих текущую проблемную ситуацию, то необходимо указывать, к каким объектам относятся рассматриваемые характеристики. Одним из способов решения этой задачи является явное указание того, к какому объекту относится характеристика.
Если РП состоит из сложных элементов, то связь между отдельными объектами указывается явно, например заданием семантических отношений. При этом каждый объект может иметь свою внутреннюю структуру. Необходимо отметить, что для ускорения поиска и сопоставления данные в РП могут быть связаны не только логически, но и ассоциативно.
Основной этап
"Накачка" поля знаний: а) в зависимости от предметной области выбор способа интервьюирования; б) протоколирование мыслей вслух или запись на магнитофон рассуждении эксперта (аналитик по возможности не должен пока вмешиваться в рассуждения). "Домашняя работа". Попытка аналитика выделить некоторые причинно-следственные связи в рассуждениях эксперта; построение словаря предметной области (возможно, на карточках) и подготовка вопросов к эксперту. "Подкачка" поля зрения. Обсуждение с экспертом прототипа поля знаний и домашней работы, а также ответы на вопросы аналитика. Формализация концептуальной модели. Построение поля знаний второго приближения.
Основные компоненты
Экспертная система реального времени состоит из базы знаний, машины вывода, подсистемы моделирования и планировщика.
Основные определения
Функционирование многих ИС носит целенаправленный характер . Типичным актом такого функционирования является решение задачи планирования пути достижения нужной цели из некоторой фиксированной начальной ситуации. Результатом решения задачи должен быть план действий - частично-упорядоченная совокупность действий. Такой план напоминает сценарий, в котором в качестве отношения между вершинами выступают отношения 'типа: "цель-подцель" "цель-действие", "действие-результат" и т. п.. Любой путь в этом сценарии, ведущий от вершины, соответствующей текущей ситуации, в любую из целевых вершин, определяет план действий.
Поиск плана действий возникает в ИС лишь тогда, когда она сталкивается с нестандартной ситуацией, для которой нет заранее известного набора действий, приводящих к нужной цели. Все задачи построения плана действий можно разбить на два типа, которым соответствуют различные модели: планирование в пространстве состояний (SS-проблема) и планирование в пространства задач (PR-проблема).
В первом случае считается заданным некоторое пространство ситуаций. Описание ситуаций включает состояние внешнего мира и состояние ИС, характеризуемые рядом параметров. Ситуации образуют некоторые обобщенные состояния, а действия ИС или изменения во внешней среде приводят к изменению актуализированных в данный момент состояний. Среди обобщенных состояний выделены начальные состояния (обычно одно) и конечные (целевые) состояния. SS-проблема состоит в поиске пути, ведущего из начального состояния в одно из конечных. Если, например, ИС предназначена для игры в шахматы, то обобщенными состояниями будут позиции, складывающиеся на шахматной доске. В качестве начального состояния может рассматриваться позиция, которая зафиксирована в данный момент игры, а в качестве целевых позиций - множество ничейных позиций. Отметим, что в случае шахмат прямое перечисление целевых позиций невозможно. Матовые и ничейные позиции описаны на языке, отличном от языка описания состояний, характеризуемых расположением фигур на полях доски.
Искусственный интеллект (ИИ) - это наука о концепциях, позволяющих ВМ
делать такие вещи, которые у людей выглядят разумными. Но что же
представляет собой интеллект человека? Есть ли эта способность размышлять?
Есть ли эта способность усваивать и использовать знания? Есть ли эта
способность оперировать и обмениваться идеями? Несомненно, все эти
способности представляют собой часть того, что является интеллектом. На
самом деле дать определение в обычном смысле этого слова, по-видимому,
невозможно, потому что интеллект - это сплав многих навыков в области
обработки и представления информации.
Центральные задачи ИИ состоят в том, что бы сделать ВМ более полезными и
чтобы понять принципы, лежащие в основе интеллекта.
Поскольку одна из задач состоит в том, чтобы сделать ВМ более полезными,
ученым и инженерам, специализирующимся в вычислительной технике,
необходимо знать, каким образом ИИ может помочь им в разрешение трудных
проблем.
В основе фонтанного преобразования лежит принцип целостности. В соответствии с ним любой воспринимаемый объект рассматривается как целое, состоящее из частей, связанных между собой определенными отношениями. Так, например, печатная страница состоит из статей, статья - из заголовка и колонок, колонка - из абзацев, абзацы - из строк, строки - из слов, слова - из букв. При этом все перечисленные элементы текста связаны между собой определенными пространствами и языковыми отношениями.
Для выделения целого требуется определить его части. Части же, в свою очередь, можно рассматривать только в составе целого. Поэтому целостный процесс восприятия может происходить только в рамках гипотезы о воспринимаемом объекте - целом. После того как выдвинуто предположение о воспринимаемом объекте, выделяются и интерпретируются его части. Затем предпринимается попытка "собрать" из них целое, чтобы проверить правильность исходной гипотезы. Разумеется, воспринимаемый объект может интерпретироваться в рамках более крупного целого.
Так, читая предложение, человек узнает буквы, воспринимает слова, связывает их в синтаксические конструкции и понимает смысл.
В технических системах любое решение при распознавании текста принимается неоднозначно, а путем последовательного выдвижения и проверки гипотез и привлечения как знаний о самом исследуемом объекте, так и общего контекста. Целостное описание класса объектов восприятия отвечает двум условиям: во - первых, все объекты данного класса удовлетворяют этому описанию, а во- вторых, ни один объект другого класса не удовлетворяют ему. Например, класс изображений буквы "К" должен быть описан так, чтобы любое изображение буквы "К" в него попадало, а изображение всех других букв - нет. Такое описание обладает свойством отображаемости, то есть обеспечивает воспроизведение описываемых объектов: эталон буквы для системы OCR позволяет визуально воспроизвести букву, эталон слова для распознавания речи позволяет произнести слово, а описание структуры предложения в синтаксическом анализаторе позволяет синтезировать правильное предложение.
Дальнейшее развитие теории планирования было связано с построением "человеческих" моделей целенаправленной деятельности. Если представить человеческие рассуждения, связанные с планированием, как некоторую целенаправленную деятельность по решению интеллектуальных задач, то в модели планирования прежде всего необходимо учесть основные особенности человеческих рассуждений. Пусть задан некоторый предметный мир, в котором действие ИС состоит в достижении целевых ситуаций sk из некоторых исходных ситуаций sn c помощью планов действий;V=bi1...bin,где bi-исполнительный модуль из данного набора В0. Задать ситуацию s в таком мире-это значит указать свойства сiО. С предметов аkО A0 и отношения между ними rpО R0, которые имели, имеют или будут иметь место в момент t. Модель предметного мира для такого действия ИС можно представить в виде Mо=<Aо, Во, Со, Ro>, а задачу планирования действий в мире Мо следующим образом: заданы исходная sn и целевая sk" ситуации, необходимо построить из исполнительных модулей biО Во план действий V, который, будучи примененным к Sn, позволяет достичь Sk. Перед человеком при решении этой задачи обычно возникают две проблемы. Во-первых, он, как правило, плохо представляет конкретную sk , удаленную в будущее. Поэтому его устраивает достижение не конкретной, а любой ситуации из класса sk , удовлетворяющей определенным требованиям. Во-вторых, если даже он представляет sk , то и тогда поиск плана действий затруднен из-за большой размерности пространства поиска. Итак, ИС необходимы более общие по отношению к Мо модели миров. Среди задач выделим класс элементарных. Остальные будем считать сложными, а их решения представлять в виде частично упорядоченной совокупности элементарных задач. Если решения различных сложных задач в каком-то смысле схожи, то они обобщаются. Так возникают обобщенные описания задач определенного типа. Из решений элементарных задач ИС выстраивает решения сложных исходных задач. Однако найти таким образом решение сразу ей обычно не удается.
Особенности знаний: Таблица 1.1
Именно это затрудняет поиск плана действий в шахматной игре.
При планировании в пространстве задач ситуация несколько иная. Пространство образуется в результате введения на множестве задач отношения типа: "часть - целое", "задача - подзадача", "общий случай - частный случай" и т. п. Другими словами, пространство задач отражает декомпозицию задач на подзадачи (цели на подцели). PR-проблема состоит в поиске декомпозиции исходной задачи на подзадачи, приводящей к задачам, решение которых системе известно. Например, ИС известно, как вычисляются значения sin x и cos x для любого значения аргумента и как производится операция деления. Если ИС необходимо вычислить tg x, то решением PR-проблемы будет представление этой задачи в виде декомпозиции tgx=a =sinx/cosx (кроме л:=л/2+k л).
Дадим классификацию методов, используемых при решении SS- и PR-проблем.
1. Планирование по состояниям. Представление задач в пространстве состояний предполагает задание ряда описаний: состояний, множества операторов и их воздействий на переходы между состояниями, целевых состояний. Описания состояний могут представлять собой строки символов, векторы, двухмерные массивы, деревья, списки и т. п. Операторы переводят одно состояние в другое. Иногда они представляются в виде продукций А=>В, означающих, что состояние А преобразуется в состояние В.
Пространство состояний можно представить как граф, вершины которого помечены состояниями, а дуги-операторами. Если некоторая дуга направлена от вершины ni, к вершине n,, то п, называется дочерней, а nj;-родительской вершинами
Последовательность вершин ni1, ni2, ... ,nik , в которой каждая ni-дочерняя вершина для вершины nij-1 , /=2,..., k, называется путем длиной k от вершины ni1, к вершине nik .
Таким образом, проблема поиска решения задачи <А,В> при планировании по состояниям представляется как проблема поиска на графе пути из A в B. Обычно графы не задаются, а генерируются по мере надобности.
Различаются слепые и направленные методы поиска пути. Слепой метод имеет два вида: поиск вглубь и поиск вширь. При поиске вглубь каждая альтернатива исследуется до конца, без учета остальных альтернатив.
Метод плох для "высоких" деревьев, так как легко можно проскользнуть мимо нужной ветви и затратить много усилий на исследование "пустых" альтернатив. При поиске вширь на фиксированном уровне исследуются все альтернативы и только после этого осуществляется переход на следующий уровень. Метод может оказаться хуже метода поиска влубь, если в графе все пути, ведущие к целевой вершине, расположены примерно на одной и той же глубине. Оба слепых метода требуют большой затраты времени и поэтому необходимы направленные методы поиска.
Метод ветвей и границ. Из формирующихся в процессе поиска неоконченных путей выбирается самый короткий и продлевается на один шаг. Полученные новые неоконченные пути (их столько, сколько ветвей в данной вершине) рассматриваются наряду со старыми, и вновь продлевается на один шаг кратчайший из них. Процесс повторяется до первого достижения целевой вершины, решение запоминается. Затем из оставшихся неоконченных путей исключаются более длинные, чем законченный путь, или равные ему, а оставшиеся продлеваются по такому же алгоритму до тех пор, пока их длина меньше законченного пути. В итоге либо все неоконченные пути исключаются, либо среди них формируется законченный путь, более короткий, чем ранее полученный. Последний путь начинает играть роль эталона и т. д.
Алгоритм кратчайших путей Мура. Исходная вершина x0 помечается числом 0. Пусть в ходе работы алгоритма на текущем шаге получено множество дочерних вершин Г(xi) вершины xi . Тогда из него вычеркиваются все ранее полученные вершины, оставшиеся помечаются меткой, увеличенной на единицу по сравнению с меткой вершины xi, и от них проводятся указатели к xi. Далее, на множестве помеченных вершин, еще не фигурирующих в качестве адресов указателей, выбирается вершина с наименьшей меткой и для нее строятся дочерние вершины. Разметка вершин повторяется до тех пор, пока не будет получена целевая вершина.
Алгоритм Дейкстры определения путей с минимальной стоимостью является обобщением алгоритма Мура за счет введения дуг переменной длины.
Алгоритм Дорана и Мичи поиска с низкой стоимостью. Используется, когда стоимость поиска велика по сравнению со стоимостью оптимального решения. В этом случае вместо выбора вершин, наименее удаленных от начала, как в алгоритмах Мура и Дейкстры, выбирается вершина, для которой эвристическая оценка расстояния до цели наименьшая. При хорошей оценке можно быстро получить решение, но нет гарантии, что путь будем минимальным.
Алгоритм Харта, Нильсона и Рафаэля. В алгоритме объединены оба критерия: стоимость пути до вершины g(x) и стоимость пути от вершины h(x) - в аддитивной оценочной функции f (x) = g (x) + h (x). При условии h(x)<hp(x), где hp(x)- действительное расстояние до цели, алгоритм гарантирует нахождение оптимального пути.
Алгоритмы поиска пути на графе различаются также направлением поиска. Существуют прямые, обратные и двунаправленные методы поиска. Прямой поиск идет от исходного состояния и, как правило, используется тогда, когда целевое состояние задано неявно. Обратный поиск идет от целевого состояния и используется тогда, когда исходное состояние задано неявно, а целевое явно. Двунаправленный поиск требует удовлетворительного решения двух проблем: смены направления поиска и оптимизации "точки встречи". Одним из критериев для решения первой проблемы является сравнение "ширины" поиска в обоих направлениях-выбирается то направление, которое сужает поиск. Вторая проблема вызвана тем, что прямой и обратный пути могут разойтись и чем уже поиск, тем это более вероятно.
2. Планирование по задачам. Этот метод приводит к хорошим результатам потому, что часто решение задач имеет иерархическую структуру. Однако не обязательно требовать, чтобы основная задача и все ее подзадачи решались одинаковыми методами. Редукция полезна для представления глобальных аспектов задачи, а при решении более специфичных задач предпочтителен метод планирования по состояниям. Метод планирования по состояниям можно рассматривать как частный случай метода планирования с помощью редукций, ибо каждое применение оператора в пространстве состояний означает сведение исходной задачи к двум более простым, из которых одна является элементарной.
В общем случае редукция исходной задачи не сводится к формированию таких двух подзадач, из которых хотя бы одна была элементарной.
Поиск планирования в пространстве задач заключается в последовательном сведении исходной задачи к все более простым до тех пор, пока не будут получены только элементарные задачи. Частично упорядоченная совокупность таких задач составит решение исходной задачи. Расчленение задачи на альтернативные множества подзадач удобно представлять в виде И/ИЛИ-графа. В таком графе всякая вершина, кроме концевой, имеет либо конъюнктивно связанные дочерние вершины (И-вершина), либо дизъюнктивно связанные (ИЛИ-вершина). В частном случае, при отсутствии И-вершин, имеет место граф пространства состояний. Концевые вершины являются либо заключительными (им соответствуют элементарные задачи), либо тупиковыми. Начальная вершина (корень И/ИЛИ-графа) представляет исходную задачу. Цель поиска на И/ИЛИ-графе - показать, что начальная вершина разрешима. Разрешимыми являются заключительные вершины (И-вершины), у которых разрешимы все дочерние вершины, и ИЛИ-вершины, у которых разрешима хотя бы одна дочерняя вершина. Разрешающий граф состоит из разрешимых вершин и указывает способ разрешимости начальной вершины. Наличие тупиковых вершин приводит к неразрешимым вершинам. Неразрешимыми являются тупиковые вершины, И-вершины, у которых неразрешима хотя бы одна дочерняя вершина, и ИЛИ-вершины, у которых неразрешима каждая дочерняя вершина.
Алгоритм Ченга и Слейгла. Основан на преобразовании произвольного И/ИЛИ-графа в специальный ИЛИ-граф, каждая ИЛИ-ветвь которого имеет И-вершины только в конце. Преобразование использует представление произвольного И/ИЛИ-графа как произвольной формулы логики высказываний с дальнейшим преобразованием этой произвольной формулы в дизъюнктивную нормальную форму. Подобное преобразование позволяет далее использовать алгоритм Харта, Нильсона и Рафаэля.
Метод ключевых операторов. Пусть задана задача <А, В> и известно, что оператор f обязательно должен входить в решение этой задачи.
Такой оператор называется ключевым. Пусть для применения f необходимо состояние С, а результат его применения есть f(с). Тогда И-вершина <A,В> порождает три дочерние вершины: <A, С>, <С, f(c}> и <f(с), В>, из которых средняя является элементарной задачей. К задачам <A, С> и <f(с), В> также подбираются ключевые операторы, и указанная процедура редуцирования повторяется до тех пор, пока это возможно. В итоге исходная задача <A, В> разбивается на упорядоченную совокупность подзадач, каждая из которых решается методом планирования в пространстве состояний.
Возможны альтернативы по выбору ключевых операторов, так что в общем случае будет иметь место И/ИЛИ-граф. В большинстве задач удается не выделить ключевой оператор, а только указать множество, его содержащее. В этом случае для задачи <А, В> вычисляется различие между A и В, которому ставится в соответствие оператор, устраняющий это различие. Последний и является ключевым.
Метод планирования общего решателя задач (ОРЗ). ОРЗ явился первой наиболее известной моделью планировщика. Он использовался для решения задач интегрального исчисления, логического вывода, грамматического разбора и др. ОРЗ объединяет два основных принципа поиска:
анализ целей и средств и рекурсивное решение задач. В каждом цикле поиска ОРЗ решает в жесткой последовательности три типа стандартных задач: преобразовать объект A в объект В, уменьшить различие D между A и В, применить оператор f к объекту A. Решение первой задачи определяет различие D второй - подходящий оператор f, третьей - требуемое условие применения С. Если С не отличается от A, то оператор f применяется, иначе С представляется как очередная цель и цикл повторяется, начиная с задачи "преобразовать A в С". В целом стратегия ОРЗ осуществляет обратный поиск - от заданной цели В к требуемому средству ее достижения С, используя редукцию исходной задачи <A, В> к задачам <A, С> и <С, В>.
Заметим, что в ОРЗ молчаливо предполагается независимость различий друг от друга, откуда следует гарантия, что уменьшение одних различий не приведет к увеличению других.
3. Планирование с помощью логического вывода. Такое планирование предполагает: описание состояний в виде правильно построенных формул (ППФ) некоторого логического исчисления, описание операторов в виде либо ППФ, либо правил перевода одних ППФ в другие. Представление операторов в виде ППФ позволяет создавать дедуктивные методы планирования, представление операторов в виде правил перевода - методы планирования с элементами дедуктивного вывода.
Дедуктивный метод планирования системы QA3 , ОРЗ не оправдал возлагавшихся на него надежд в основном из-за неудовлетворительного представления задач. Попытка исправить положение привела к созданию вопросно-ответной системы QA3. Система рассчитана на произвольную предметную область и способна путем логического вывода ответить на вопрос: возможно ли достижение состояния В из A? В качестве метода автоматического вывода используется принцип резолюций. Для направления логического вывода QA3 применяет различные стратегии, в основном синтаксического характера, учитывающие особенности формализма принципа резолюций. Эксплуатация QA3 показала, что вывод в такой системе получается медленным, детальным, что несвойственно рассуждениям человека.
Метод продукций системы STRIPS . В этом методе оператор представляет продукцию Р, А=>В, где Р, А и В-множества ППФ исчисления предикатов первого порядка, Р выражает условия применения ядра продукции А=>В, где В содержит список добавляемых ППФ и список исключаемых ППФ, т. е. постусловия. Метод повторяет метод ОРЗ с тем отличием, что стандартные задачи определения различий и применения подходящих операторов решаются на основе принципа резолюций. Подходя-. щий оператор выбирается так же, как в ОРЗ, на основе принципа "анализ средств и целей". Наличие комбинированного метода планирования позволило ограничить процесс логического вывода описанием состояния мира, а процесс порождения новых таких описаний оставить за эвристикой "от цели к средству ее достижения".
Метод продукций, использующий макрооператоры .
Макрооператоры- это обобщенные решения задач, получаемые методом STRIPS. Применение макрооператоров позволяет сократить поиск решения, однако при этом возникает проблема упрощения применяемого макрооператора, суть которой заключается в выделении по заданному различию его требуемой части и исключении из последней ненужных операторов.
Метод иерархической системы продукций решателя ABSTRIPS . В этом методе разбиение пространства поиска на уровни иерархии осуществляется с помощью детализации продукций, используемых в методе STRIPS. Для этого каждой литере ППФ, входящей в множество Р условий применения продукции, присваивается вес j, j=0, k, и на i-м уровне планирования, осуществляемом методом системы STRIPS, учитываются лишь литеры веса j. Таким образом, на k-ом уровне продукции описываются наименее детально, на нулевом-наиболее детально как в методе системы STRIPS. Подобное разбиение позволяет для планирования на j-м уровне использовать решение (j+1)-го уровня как скелет решения j-го уровня, что повышает эффективность поиска в целом.
Усовершенствованный метод планирования Ньюэлла и Саймона. В основу метода положена следующая идея дальнейшего совершенствования метода ОРЗ: задача решается сначала в упрощенной (за счет ранжировки различий) области планирования, а затем делается попытка уточнить решение применительно к более детальной, исходной проблемной области.
Основные понятия и определения.
Основные принципы или целостность восприятия
С практической точки зрения отображаемость играет огромную роль, поскольку позволяет эффективно контролировать качество описаний.
Существует два вида целостного описания: шаблонное и структурное.
В первом случае описание представляет собой изображение в растровом или векторном представлении, и задан класс преобразований (например, повтор, масштабирование и пр.).
Во втором случае описание представляется в виде графа, узлами которого являются составляющие элементы входного объекта, а дугами - пространственные отношения между ними . В свою очередь элементы могут оказаться сложными (то есть иметь свое описание).
Конечно, шаблонное описание проще в реализации, чем структурное. Однако оно не может использоваться для описания объектов с высокой степенью изменчивости. Шаблонное описание, к примеру, может приниматься для распознавания только печатных символов, а структурное - еще и для рукописных.
Целостность восприятия предлагает два важных архитектурных решения. Во первых, все источники знания должны работать по возможности одновременно. Нельзя, например, сначала распознать страницу, а затем подвергнуть ее словарной и контекстной обработке, поскольку в этом случае невозможно будет осуществить обратную связь от контекстной обработки к распознаванию. Во вторых, исследуемый объект должен представляться и обрабатываться по возможности целиком.
Первый шаг восприятие - это формирование гипотезы о воспринимаемом объекте. Гипотеза может формироваться как на основе априорной модели объекта, контекста и результатов проверки предыдущих гипотез (процесс "сверху - вниз"), так и на основе предварительного анализа объекта ("снизу - вверх"). Второй шаг - уточнение восприятия (проверка гипотезы), при котором производится дополнительный анализ объекта в рамках выдвинутой гипотезы и в полную силу привлекается контекст.
Для удобства восприятия необходимо провести предварительную обработку объекта, не потеряв при этом существенной информации о нем. Обычно предварительная обработка сводится к преобразованию входного объекта в представление, удобное для дальнейшей работы (например, векторизация изображения), или получение всевозможных вариантов сегментации входного объекта, из которого путем выдвижения и проверки гипотез выбирается правильный.
Процесс выдвижения и проверки гипотез должен быть явно отражен в архитектуре программы. Каждая гипотеза должна быть объектом, который можно было бы оценить или сравнить с другими. Поэтому обычно гипотезы выдвигаются последовательно, а затем объединяются в список и сортируются на основе предварительной оценке. Для окончательного же выбора гипотезы активно используется контекст и другие дополнительные источники знаний.
Ныне одним из лидеров в области генетического программирования является группа исследователей из Стэндфордского университета (Stanford University), работающая под руководством профессора Джона Коза. Генетическое программирование вдохнуло новую жизнь в хорошенько уже подзабытый язык LISP (List Processing), который создавался группой Джона Маккарти (того самого, кто в 60-е годы ввел в наш обиход термин "искусственный интеллект") как раз для обработки списков и функционального программирования. Кстати, именно этот язык в США был и остается одним из наиболее распространенных языков программирования для задач искусственного интеллекта.
Основные производители
Инструментарий для создания экспертных систем реального времени впервые выпустила фирма Lisp Machine Inc в 1985 году. Этот продукт предназначался для символьных ЭВМ Symbolics и носил название Picon. Его успех привел к тому, что группа ведущих его разработчиков образовала фирму Gensym, которая, значительно развив идеи, заложенные в Picon, выпустила в 1988 году инструментальное средство под названием G2. В настоящий момент работает его третья версия и подготовлена четвертая [1,7].
С отставанием от Gensym на два-три года ряд других фирм начал создавать (или пытаться создавать) свои инструментальные средства. Назовем ряд из них: RT Works (фирма Talarian, США), COMDALE/C (Comdale Techn., Канада), COGSYS (SC, США), ILOG Rules (ILOG, Франция). Сравнение двух наиболее продвинутых систем, G2 и RT Works, которое проводилось путем разработки одного и того же приложения двумя организациями, NASA (США) и Storm Integration (США) [10], показало значительное превосходство первой.
Особенности планирования целенаправленных действий
Поэтому для перехода от исходных задач к элементарным используются типовые задачи. Вначале для заданной исходной задачи определяется смысловая структура ее исходных данных, т. е. ставится стратегическая задача и формируется ее гипотеза решения. Далее каждая типовая задача гипотезы декомпозируется, что приводит к постановке и решению тактических задач и, следовательно, к решению исходной задачи.
Наличие в базе знаний типовых и элементарных задач свидетельствует об иерархической структуре не только базы знаний, но и процедур поиска, при этом типовые задачи могут быть условно отнесены к стратегическому, а элементарные - к тактическому уровню поиска. Смысловые структуры требуемых результатов и исходных данных типовых задач обычно выявляются в результате осмысливания требуемых результатов или исходных данных тактических задач и недоступны непосредственному чувственному восприятию. Таким образом, на стратегическом уровне каждая тактическая ситуация (исходные данные или требуемый результат) оценивается по наличию в ней знакомых смысловых структур. Например, в шахматной игре смысловые структуры выражаются понятием "развитая позиция", "открытая позиция" и т. д. На тактическом уровне решаются спроецированные со стратегического уровня путем декомпозиции типовых задач тактические задачи, например образование проходной пешки в шахматной игре.
Итак, основу рассуждений ИС по планированию действий составляют структурированные знания и направленный эвристический поиск.
Пусть C1 - множество, получаемое огрублением свойств сО С0 , В1 - множество элементарных задач, получаемое переименованием исполнительных модулей biО B0, A1 ? A и R1? Ro. Тогда модель мира тактических задач можно представить в виде Mo=<A1, B1, C1, R1>, постановку тактической задачи р-
в виде пары <sn, sk >, а ее решение-в виде совокупности V = Ь1 , ..., Ьin. Очевидно, благодаря указанному огрублению в мире M1 становятся неразличимыми отдельные состояния предметов и исполнительных модулей.
Однако подобное упрощение, вызываемое "грубостью" органов чувств ИС, еще не позволяет значительно снизить размерность пространства поиска решений V, поэтому необходимо дальнейшее обобщение M1 уже на понятийном уровне.
В мире M1 тактические ситуации s описываются, как и ситуации s в мире M0, через свойства объектов и отношения между ними. Однако такие описания не носят целостного характера, так как не содержат в явном виде смысловых структур. Выявление таких обобщенных структур, а также формирование соответствующих им тактических ситуаций s осуществляются на основе понятий, которыми располагает ИС, и означают осмысливание ею сложившихся или целевых ситуаций s с точки зрения этих понятий, используемых в этом случае как программы-тесты. Таким образом, в мире M2 указанные ситуации s представляются в виде укрупненных предметов ak О A2, свойства которых ci О C2 и отношения r2 О R2 между которыми, как и сами укрупненные предметы, определяются понятиями-тестами. Аналогично обстоят дела и с решениями V в мире M1. Целостное описание V означает описание этих решений именно как типовых задач. Таким образом, в мире M2 имеют место типовые задачи bi О B2.
Особенности знаний. Переход от Базы Данных к Базе Знаний.
| Фамилия | Год рождения | Специальность | Стаж, число лет |
| Попов | 1965 | Слесарь | 5 |
| Сидоров | 1946 | Токарь | 20 |
| Иванов | 1925 | Токарь | 30 |
| Петров | 1937 | Сантехник | 25 |
Если, например, в память ЭВМ нужно было записать сведения о сотрудниках учреждения, представленные в табл. 1.1, то без внутренней интерпретации в память ЭВМ была бы занесена совокупность из четырех машинных слов, соответствующих строкам этой таблицы. При этом информация о том, какими группами двоичных разрядов в этих машинных словах закодированы сведения о специалистах, у системы отсутствуют. Они известны лишь программисту, который использует данные табл. 1.1 для решения возникающих у него задач. Система не в состоянии ответить на вопросы типа "Что тебе известно о Петрове?" или "Есть ли среди специалистов сантехник?".
При переходе к знаниям в память ЭВМ вводится информация о некоторой протоструктуре информационных единиц. В рассматриваемом примере она представляет собой специальное машинное слово, в котором указано, в каких разрядах хранятся сведения о фамилиях, годах рождения, специальностях и стажах. При этом должны быть заданы специальные словари, в которых перечислены имеющиеся в памяти системы фамилии, года рождения, специальности и продолжительности стажа. Все эти атрибуты могут играть роль имен для тех машинных слов, которые соответствуют строкам таблицы. По ним можно осуществлять поиск нужной информации. Каждая строка таблицы будет экземпляром протоструктуры.
Как бы то ни было, продолжатся поиски такого интерфейса, который устроил бы всех. На эту роль сейчас претендует интерфейс речевой. Собственно говоря, это как раз то, к чему человечество всегда стремилось в общении с компьютером. Еще в эпоху перфокарт в научно-фантастических романах человек с компьютером именно разговаривал, как с равным себе. Тогда же, в эпоху перфокарт, или даже ранее, были предприняты первые шаги по реализации речевого интерфейса. Работы в этом направлении велись еще в то время, когда о графическом интерфейсе никто даже и не помышлял. За сравнительно короткий период был выработан исчерпывающий теоретический базис, и практические достижения обуславливались только производительностью компьютерной техники.Исследователи недалеко продвинулись за прошедшие десятки лет, что заставляет некоторых специалистов крайне скептически относиться к самой возможности реализации речевого интерфейса в ближайшем будущем. Другие считают, что задача уже практически решена. Впрочем, все зависит от того, что следует считать решением этой задачи.Построение речевого интерфейса распадается на три составляющие. Первая задача состоит в том, чтобы компьютер мог "понять"то, что ему говорит человек, то есть он доложен уметь извлекать из речи человека полезную информацию. Пока что, на нынешнем этапе, эта задача сводится к тому, чтобы извлечь из речи смысловую ее часть, текст (понимание таких составляющих, как скажем, интонация, пока вообще не рассматривается). То есть эта задача сводится к замене клавиатуры микрофон.Вторая задача состоит в том, чтобы компьютер воспринял смысл сказанного. Пока речевое сообщение состоит из некоего стандартного набора понятных компьютеру команд (скажем, дублирующих пункты меню), ничего сложного в ее реализации нет. Однако вряд ли такой подход будет удобнее, чем ввод этих же команд с клавиатуры или при помощи мыши. Пожалуй, даже удобнее просто щелкнуть мышкой по иконке приложения, чем четко выговаривать (к тому же мешая окружающим): "Старт! Главное меню! Ворд!" .В идеале компьютер должен четко "осмысливать" естественную речь человека и понимать, что, к примеру, слова "Хватит!" и "Кончай работу!" означают в одной ситуации разные понятия, а в другой - одно и то же .
Мало кто знает, как человек общался с первыми вычислительными машинами. Происходило это так: оператор, используя провода с разъемами на концах, соединял между собой триггеры (из которых, собственно, и состояла машина) таким образом, чтобы при запуске выполнялась нужная последовательность команд. Внешне это очень напоминало манипуляции телефонных АТС начала века, а по сути - было очень квалифицированной работой. Можно сказать, программирование тогда осуществлялось даже не в машинных командах, а на аппаратном уровне.Потом задача упростилась:последовательность нужных команд стали записывать непосредственно в память машины. Для ввода информации стали применяться более производительные устройства. Сначала это были группы тумблеров, переключая которые, оператор (или программист - тогда эти понятия означали одно и то же) мог набрать нужную команду и ввести ее в память машины. Затем появились перфокарты. Следом - перфоленты. Скорость общения с машиной возросла, число ошибок, возникающих при вводе, резко уменьшилось. Но сущность этого общения, его характер - не изменились. Возможность впервые пообщаться напрямую появилась на так называемых малых машинах. Неизгладимы впечатления от знакомства с диалоговым интерфейсом. Это было чудовищное порождение советской промышленности под поэтическим названием "Наири". Тогда диковинная возможность отстучать на клавиатуре адресованную непосредственно машине команду и получить осмысленный отклик казалась чудом. Особенно если до тех пор весь процесс общения с машиной заключался в передаче в руки лаборанта колоды перфокарт. С тем чтобы через пару дней получить назад эту колоду с комментарием: "У вас тут ошибка, программа не пошла".Измученным такого рода пользователям скудный диалоговый режим командной строки казался верхом совершенства. Именно ему сначала малые ЭВМ, а потом и персоналки во многом обязаны своим триумфальным шествием. Любой потребитель компьютерных услуг мог, не вдаваясь в технические трудности и выучив всего пару десятков команд операционной системы, общаться с компьютером без посредников. Тогда впервые возникло такое понятие, как "юзер", и именно появлению диалогового режима история приписывает взлет и расцвет многих компьютерных компаний, таких, например, как DEC.А потом появился его величество интерфейс графический: отпала нужда в знании вообще каких-либо команд, и юзер стал общаться со своим железным другом на интуитивно понятном языке жестов. На горизонте замаячил призрак звукового интерфейса... Первый и основной вопрос, который надо решить при представлении знаний, - это вопрос определения состава знаний, т.е. определение того, "ЧТО ПРЕДСТАВЛЯТЬ" в экспертной системе. Второй вопрос касается того, "КАК ПРЕДСТАВЛЯТЬ" знания. Необходимо отметить, что эти две проблемы не являются независимыми. Действительно, выбранный способ представления может оказаться непригодным в принципе либо неэффективным для выражения некоторых знаний. По нашему мнению, вопрос "КАК ПРЕДСТАВЛЯТЬ" можно разделить на две в значительной степени независимые задачи: как организовать (структурировать) знания и как представить знания в выбранном формализме. Стремление выделить организацию знаний в самостоятельную задачу вызвано, в частности, тем, что эта задача возникает для любого языка представления и способы решения этой задачи являются одинаковыми (либо сходными) вне зависимости от используемого формализма. Итак, в круг вопросов, решаемых при представлении знаний, будем включать следующие:
определение состава представляемых знаний; организацию знаний; представление знаний, т.е. определение модели представления.
Состав знаний ЭС определяется следующими факторами:
проблемной средой; архитектурой экспертной системы; потребностями и целями пользователей; языком общения.
В соответствии с общей схемой статической экспертной системы (см. рис. 1.1) для ее функционирования требуются следующие знания:
В настоящее время СУБД обеспечивают реализацию внутренней интерпретируемости всех информационных единиц, хранящихся в базе данных.
Структурированность. Информационные единицы должны обладать гибкой структурой. Для них должен выполняться "принцип матрешки", т.е. рекурсивная вложимость одних информационных единиц в другие. Каждая информационная единица может быть включена в состав любой другой, и из каждой информационной единицы можно выделить некоторые составляющие ее информационные единицы. Другими словами, должна существовать возможность произвольного установления между отдельными информационными единицами отношений типа "часть - целое", "род - вид" или "элемент - класс".
Связность. В информационной базе между информационными единицами должна быть предусмотрена возможность установления связей различного типа. Прежде всего эти связи могут характеризовать отношения между информационными единицами. Семантика отношений может носить декларативный или процедурный характер. Например, две или более информационные единицы могут быть связаны отношением "одновременно", две информационные единицы - отношением "причина - следствие" или отношением "быть рядом". Приведенные отношения характеризуют декларативные знания. Если между двумя информационными единицами установлено отношение "аргумент - функция", то оно характеризует процедурное знание, связанное с вычислением определенных функций. Далее будем различать отношения структуризации, функциональные отношения, каузальные отношения и семантические отношения. С помощью первых задаются иерархии информационных единиц, вторые несут процедурную информацию, позволяющую находить (вычислять) одни информационные единицы через другие, третьи задают причинно - следственные связи, четвертые соответствуют всем остальным отношениям.
Между информационными единицами могут устанавливаться и иные связи, например, определяющие порядок выбора информационных единиц из памяти или указывающие на то, что две информационные единицы несовместимы друг с другом в одном описании.
Перечисленные три особенности знаний позволяют ввести общую модель представления знаний, которую можно назвать семантической сетью, представляющей собой иерархическую сеть, в вершинах которой находятся информационные единицы. Эти единицы снабжены индивидуальными именами. Дуги семантической сети соответствуют различным связям между информационными единицами. При этом иерархические связи определяются отношениями структуризации, а неиерархические связи - отношениями иных типов.
Семантическая метрика. На множестве информационных единиц в некоторых случаях полезно задавать отношение, характеризующее ситуационную близость информационных единиц, т.е. силу ассоциативной связи между информационными единицами. Его можно было бы назвать отношением релевантности для информационных единиц. Такое отношение дает возможность выделять в информационной базе некоторые типовые ситуации (например, "покупка", "регулирование движения на перекрестке"). Отношение релевантности при работе с информационными единицами позволяет находить знания, близкие к уже найденным.
Активность. С момента появления ЭВМ и разделения используемых в ней информационных единиц на данные и команды создалась ситуация, при которой данные пассивны, а команды активны. Все процессы, протекающие в ЭВМ, инициируются командами, а данные используются этими командами лишь в случае необходимости. Для ИС эта ситуация не приемлема. Как и у человека, в ИС актуализации тех или иных действий способствуют знания, имеющиеся в системе. Таким образом, выполнение программ в ИС должно инициироваться текущим состоянием информационной базы. Появление в базе фактов или описаний событий, установление связей может стать источником активности системы.
Перечисленные пять особенностей информационных единиц определяют ту грань, за которой данные превращаются в знания, а базы данных перерастают в базы знаний (БЗ). Совокупность средств, обеспечивающих работу с знаниями, образует систему управления базой знаний (СУБЗ).В настоящее время не существует баз знаний, в которых в полной мере были бы реализованы внутренняя интерпретируемость, структуризация, связность, введена семантическая мера и обеспечена активность знаний.
Подготовительный этап
Четкое определение задач проектируемой системы (сужение поля знаний): определение, что на входе и выходе; определение режима работ, консультации, обучение и др. Выбор экспертов: определение количества экспертов; выбор уровня компетентности (не всегда хорошо выбирать самый высокий уровень сразу); определение способов и возможности заинтересовать экспертов в работе; тестирование экспертов. Знакомство аналитика со специальной литературой в предметной области. Знакомство аналитика и экспертов (в дальнейшем для простоты будем считать, что эксперт один). Знакомство эксперта с популярной литературой по искусственному интеллекту (желательно, но необязательно). Попытка аналитика создать поле знаний первого приближения априорным знаниям из литературы (прототип поля знаний).
Понимание в диалоге
Третья задача состоит в том, чтобы компьютер мог преобразовать информацию, с которой он оперирует, в речевое сообщение, понятное человеку. Пока окончательное решение существует только для третьей.По сути, синтез речи - это чисто математическая задача, которая в настоящее время решена на довольно хорошем уровне. И в ближайшее время, скорее всего, будет совершенствоваться только ее техническая реализация. Уже есть разного рода программы для чтения вслух текстовых файлов, озвучкой диалоговых окон. пунктов меню и могу засвидетельствовать, что с генерацией разборчивых текстовых сообщений они справляются без проблем.Препятствием для окончательного решения первой задачи служит то, что никто до сих пор толком не знает, каким образом можно расчленить нашу речь, чтобы извлечь из нее составляющие, в которых содержится смысл. В том звуковом потоке, который мы выдаем при разговоре, нельзя различить ни отдельных букв, ни слогов: даже, казалось бы, одинаковые буквы и слоги в разных словах на спектрограммах выглядят по-разному. Тем не менее многие фирмы уже имеют свои методики (увы, тщательно скрываемые), позволяющие худо-бедно решить эту задачу. Во всяком случае, после предварительной тренировки современные системы распознавания речи работают довольно сносно и делают ошибок не больше, чем делали оптические системы распознавания печатных символов лет пять-семь назад.Что касается второй задачи, то она, по мнению большинства специалистов, не может быть решена без помощи систем искусственного интеллекта. Большие надежды есть на появление так называемых квантовых компьютеров. Если же подобные устройства появятся, это будет означать качественный переворот в вычислительных технологиях.Поэтому пока удел речевого интерфейса - всего лишь дублирование голосом команд, которые могут быть введены с клавиатуры или при помощи мыши. А здесь его преимущества сомнительны.Впрочем, есть одна область, которая дли многих может оказаться очень привлекательной.Это речевой ввод текстов в компьютер. Действительно, чем стучать по клавиатуре, гораздо удобнее продиктовать все компьютеру, чтобы он записал услышанное в текстовый файл.
Здесь вовсе не требуется, чтобы компьютер осмысливал услышанное, а задача перевода речи в текст более или менее решена. Недаром большинство выпускаемых ныне программ "речевого интерфейса" ориентированы именно на ввод речи. Хотя и здесь есть место для скепсиса. Если читать вслух, четко выговаривая слова, с паузами, монотонно, как это требуется для системы распознавания речи, то на машинописную страничку у меня уйдет пять минут. Писать о речевом интерфейсе сложно. С одной стороны, тема абсолютно не нова, с другой - активное развитие и применение этой технологии только начинается (в который раз). С одной стороны, успели сформироваться устойчивые стереотипы и предубеждения, с другой - несмотря на почти полвека настойчивых усилий не нашли разрешения концептуальные вопросы, стоявшие еще перед родоначальниками речевого ввода. Первый - и, пожалуй, основной - вопрос касается области применения. Поиск приложений. где распознавание речи могло бы продемонстрировать все свои достоинства, вопреки устоявшемуся мнению, является задачей далеко не тривиальной. Сложившаяся практика применения компьютеров вовсе не способствует широкому внедрению речевого интерфейса. Становление современной компьютерной индустрии проходило под флагом графического интерфейса, альтернативы которому в круге задач, решаемых сегодня компьютерами, не существует. Массовые приложения: САПР, офисные и издательские пакеты, СУБД составляют основной объем интеллектуальной начинки компьютеров, оставляя в их нынешнем виде очень мало места для применения альтернативных моделей пользовательского интерфейса, в том числе и речевого. Для подачи команд, связанных с позиционированием в пространстве, человек всегда пользовался и будет пользоваться жестами, то есть системой "руки- глаза". На этом принципе построен современный графический интерфейс, Перспектива замены клавиатуры и мыши блоком распознавания речи абсолютно отпадает. При этом выигрыш от возложения на него части функций управления настолько мал, что не смог предоставить достаточных оснований даже для пробного внедрения в массовых компьютерах на протяжении уже более тридцати лет.
Именно таким сроком оценивается существование коммерчески применимых систем распознавания речи. Сегодня среди ведущих производителей систем распознавания речи не принято отдавать должное достижениям исследователей прошлых лет. Причина понятна: это не только в значительной степени снизит видимые показатели достигнутого ими прогресса, но и поспособствует возникновению вполне обоснованных сомнений в перспективности осуществляемых подходов вообще. Для объективной оценки прогресса технологии распознавания речи сравните характеристики систем, реализованных в рамках проекта к 1976 году и систем, продвигаемых на рынок в настоящее время. Возникает два вопроса. Почему не нашли достойного применения разработки двадцатилетней давности и почему за такой продолжительный период не произошло видимого качественного сдвига в характеристиках конкретных систем? Ответ на I первый вопрос частично изложен выше: основная проблема-в области применения. Можно добавить. что вопреки настойчиво навязываемому сегодня в маркетинговых целях (в частности, для про- ' движения процессоров ММХ) мнению, высокие требования данной технологии к вычислительным ресурсам не являлись основным препятствиям к ее широкому внедрению. Возникновение схожих проблем у разработчиков графических систем привело к созданию и массовому применению графических аппаратных ускорителей,а не отказу от оконного интерфейса .При этом разрабатываемые peчевые адаптеры не превосходят по себестоимости графических.Ответ на второй вопрос напрямую связан с первым. Технология, не находящая применения, не может себя прокормить и обеспечить свой рост. Кроме того, вполне возможно, что ориентация большинства исследовательских центров на увеличение распознаваемого словаря является ошибочной как с точки зрения применимости, так и с точки зрения научной перспективности. Еще в 1969 году в своем знаменитом письме редактору журнала Акустического общества Америки Дж. Пиес, сотрудник фирмы Bell Laboratories,указал на отсутствие явного прогресса в то время и возможности такого прогресса технологии распознавания речи в ближайшем будущем в связи с неспособностью компьютеров анализировать синтаксическую, семантическую и прагматическую информацию, содержащуюся в высказывании.
Имеющийся барьер может быть преодолен только с развитием систем искусственного интеллекта- направлением, натолкнувшимся в 70-х на барьер сложности и находящемся в настоящее время практически в полном забвении. Трудно надеяться на дальнейшее улучшение характеристик устройств речевого ввода, учитывая, что уже в 70-х годах их способность распознавать звуки речи превосходила человеческую. Данный факт был подтвержден серией экспериментов по сравнению уверенности распознавания человеком и компьютером слов иностранного языка и бессмысленных цепочек звуков. При отсутствии возможности подключения прагматических (смысловых), семантических и других анализаторов человек явно проигрывает. Для иллюстрации приведенных выше, возможно, несколько спорных утверждений рассмотрим перспективу и основные проблемы применения систем речевого ввода текстов, особенно активно продвигаемых в последнее время.Для сравнения: спонтанная речь произносится со средней скоростью 2,5 слов в секунду, профессиональная машинопись - 2 слова в секунду, непрофессиональная -0,4. Таким образом, на первый взгляд, речевой ввод имеет значительное превосходство по производительности. Однако оценка средней скорости диктовки в реальных условиях снижается до 0,слова в секунду в связи с необходимостью четкого произнесения слов при речевом вводе и достаточно высоким процентом ошибок распознавания, нуждающихся в корректировке.Речевой интерфейс естественен для человека и обеспечивает дополнительное удобство при наборе текстов. Однако даже профессионального диктора может не обрадовать перспектива в течение нескольких часов диктовать малопонятливому и немому (к этому еще вернемся) компьютеру. Кроме того, имеющийся опыт эксплуатации подобных систем свидетельствуете высокой вероятности заболевания голосовых связок операторов, что связано с неизбежной при диктовке компьютеру монотонностью речи. Часто к достоинствам речевого ввода текста относят отсутствие необходимости в предварительном обучении. Однако одно из самых слабых мест современных систем распознавания речи - чувствительность к четкости произношения - приводит к потере этого, казалось бы, очевидного преимущества, Печатать на клавиатуре оператор учится в среднем 1-2 месяца.
Постановка правильного произношения может занять несколько лет. Кроме того, дополнительное напряжение -следствие сознательных и подсознательных усилий по достижению более высокой распознаваемости - совсем не способствует сохранению нормального режима работы речевого аппа-рата оператора и значительно увеличивает риск появления специфических заболеваний.Существует и еще одно неприятное ограничение применимости, сознательно не упоминаемое, на мой взгляд, создателями систем речевого ввода. Оператор, взаимодействующий с компьютером через речевой интерфейс, вынужден работать в звукоизолированном отдельном помещении либо пользоваться звукоизолирующим шлемом. Иначе он будет мешать работе своих соседей по офису, которые, в свою очередь, создавая дополнительный шумовой фон будут значительно затруднять работу речевого распознавателя, Таким образом, речевой интерфейс вступает в явное противоречие с современной организационной структурой предприятий, ориентированных на коллективный труд. Ситуация несколько смягчается с развитием удаленных форм трудовой деятельности, однако еще достаточно долго самая естественная для человека производительная и потенциально массовая форма пользовательского интерфейса обречена на узкий круг применения. Ограничения применимости систем распознавания речи в рамках наиболее популярных традиционных приложений заставляют сделать вывод о необходимости поиска потенциально перспективных для внедрения речевого интерфейса приложений за пределами традиционной офисной сферы, что подтверждается коммерческими успехами узкоспециализированных речевых систем.
в исследованиях по искусственному интеллекту
В настоящее время в исследованиях по искусственному интеллекту (ИИ) выделились шесть направлений:
Представление знаний.
Манипулирование знаниями.
Общение.
Восприятие.
Обучение.
Поведение.
В рамках направления "Представление знаний" решаются задачи, связанные с формализацией и представлением знаний в памяти интеллектуальной системы (ИС). Для этого разрабатываются специальные модели представления знаний и языки для описания знаний, выделяются различные типы знаний. Изучаются источники, из которых ИС может черпать знания, и создаются процедуры и приемы, с помощью которых возможно приобретение знаний для ИС. Проблема представления знаний для ИС чрезвычайно актуальна, т.к. ИС - это система, функционирование которой опирается на знания о проблемной области, которые хранятся в ее памяти.
Предпосылки возникновения систем понимания естественного языка
Представление знаний в экспертных системах
Для динамической ЭС, кроме того, необходимы следующие знания:
знания о методах взаимодействия с внешним окружением; знания о модели внешнего мира.Поддерживающие знания имеют описательный характер.
Интерпретируемые знания можно разделить на предметные знания, управляющие знания и знания о представлении. Знания о представлении содержат информацию о том, каким образом (в каких структурах) в системе представлены интерпретируемые знания.
Предметные знания содержат данные о предметной области и способах преобразования этих данных при решении поставленных задач. Отметим, что по отношению к предметным знаниям знания о представлении и знания об управлении являются метазнаниями. В предметных знаниях можно выделить описатели и собственно предметные знания. Описатели содержат определенную информацию о предметных знаниях, такую, как коэффициент определенности правил и данных, меры важности и сложности. Собственно предметные знания разбиваются на факты и исполняемые утверждения. Факты определяют возможные значения сущностей и характеристик предметной области. Исполняемые утверждения содержат информацию о том, как можно изменять описание предметной области в ходе решения задач. Говоря другими словами, исполняемые утверждения - это знания, задающие процедуры обработки. Однако мы избегаем использовать термин "процедурные знания", так как хотим подчеркнуть, что эти знания могут быть заданы не только в процедурной, но и в декларативной форме.
Управляющие знания можно разделить на фокусирующие и решающие. Фокусирующие знания описывают, какие знания следует использовать в той или иной ситуации. Обычно фокусирующие знания содержат сведения о наиболее перспективных объектах или правилах, которые целесообразно использовать при проверке соответствующих гипотез (см. п. 9.2). В первом случае внимание фокусируется на элементах рабочей памяти, во втором - на правилах базы знаний. Решающие знания содержат информацию, используемую для выбора способа интерпретации знаний, подходящего к текущей ситуации. Эти знания применяются для выбора стратегий или эвристик, наиболее эффективных для решения данной задачи.
Качественные и количественные показатели экспертной системы могут быть значительно улучшены за счет использования метазнании, т.е.
знаний о знаниях. Метазнания не представляют некоторую единую сущность, они могут применяться для достижения различных целей. Перечислим возможные назначения метазнаний :
метазнания в виде стратегических метаправил используются для выбора релевантных правил ;
метазнания используются для обоснования целесообразности применения правил из области экспертизы;
метаправила используются для обнаружения синтаксических и семантических ошибок в предметных правилах;
метаправила позволяют системе адаптироваться к окружению путем перестройки предметных правил и функций;
метаправила позволяют явно указать возможности и ограничения системы, т.е. определить, что система знает, а что не знает.
Вопросы организации знаний необходимо рассматривать в любом представлении, и их решение в значительной степени не зависит от выбранного способа (модели) представления. Выделим следующие аспекты проблемы организации знаний :
организация знаний по уровням представления и по уровням детальности;
организация знаний в рабочей памяти;
организация знаний в базе знаний.
формализации качественных знаний
При анализе ситуации эксперт рассуждает в семантическом пространстве (пространстве шкал), в котором ситуации соответствует оцененный образ. Семантическое пространство аналогично субъективному пространству ощущений в котором формируется внутренний образ внешних сигналов и возникают субъективные связи между свойствами (признаками, параметрами), В зависимости от индивидуального восприятия одно и то же значение признака может быть оценено по-разному. Однако для конкретного индивидуума оцененная ситуация является инвариантом относительно определенного класса ситуаций. Следовательно при отождествлении реальных значений признаков с семантическим образом существенной является форма нечеткого отображения пространства признаков в семантическое пространство.

Отображение любой ситуации на единичный интервал происходит таким образом, что точка интервала характеризует степень проявления некоторого свойства (0 соответствует отсутствию свойства, 1-интересующему нас максимальному проявлению свойства). При построений функции принадлежности используется модель измерений, которая определяется двумя параметрами: типом шкалы принадлежности, на которую отображается информация от эксперта" и типом измерения (прямой или косвенный). Шкала называется фундаментальной, если она допускает прямое взаимодействие множества U и того нечеткого свойства, которое нас интересует. Такая шкала дает возможность прямого измерения субъективного восприятия нечетких множеств на U со свойствами понятия а [Yager, 1982; Norwich et aL, 1984]. В табл. 2.1 приведены наиболее часто встречающиеся типы шкал и связанные с ними аксиомы.
Процесс формализации знаний, полученных у эксперта, состоит из следующих шагов: выбор метода измерения нечеткости, получение исходных данных посредством опроса эксперта, реализация алгоритма построения функции принадлежности. Известные методы формализации нечеткости систематизированы в табл. 2.2. В процессе реализации метода используются следующие характеристики: тип метода измерения (П - прямой, К - косвенный); интерпретация принадлежности (ВЧ-вероятность частотная, ВС-вероятность субъективная, В - возможность, Д - детерминированная); процедура получения исходных данных (ОФ - определение функции принадлежности в виде формул, 03-назначение значений принадлежности" ОДН-оценивание типа "да-нет"; ОПО- оценивание пар объектов; Р-ранжирование, РП-ранжирование пар объектов, ПС-попарное сравнение); измерений (Ф-фундаментальное, П-производное)'. тип шкалы (Н-номинальная" П-порядковая, И-интервальная, О- отношений, А - абсолютная),
Приведем пример измерения нечеткости. Множество оценок сходства приведено в табл. 2.3. В [Горячев и др., 1984] предполагается, что при оценке сходства используются числовые значения из табл. 2.3. Процедура формирования значений функции принадлежности следующая: I) фиксация понятия "Сходство";
2) ранжирование пар оценок сходства из табл. 2.3 по сходству в парах (чем больше сходство, тем меньше ранг); матрица сравнения пар оценок сходства приводится в табл. 2.4, 2 5 соответственно в строчной и матричной форме.
Примеры применения логики для представления знаний.
Проиллюстрируем синтаксис логики предикатов, сопоставляя нескольким русским фразам их перевод на язык логического формализма.
По русски: Жак посылает книгу Мари,Логически: Посылка (Жак_2, Мари_4, Книга_22). По русски: Каждый человек прогуливается,
Логически: " x ( Человек(x) E Прогуливается(x)). По русски: Некоторые люди прогуливаются,
Логически: $ x (Человек(x) U Прогуливается(x)).
(Сравнивая два последних примера, видим, что замена прилагательного "каждый" на "некоторые" влечет при переводе не только замену квантора " на $, но изамену связки E на U. Это иллюстрирует тот факт, что перевод фразы естественного языка на логический, вообще говоря, не является трафаретной операцией.)
По русски: Ни один человек не прогуливается,Логически: O ($ x (Человек(x) U Прогуливается(x))).
Примеры системы обработки естественного языка
Самый успешный на сегодня проект коммерческого применения распознавания речи - телефонная сеть фирмы AT&. Клиент может запросить одну из пяти категорий услуг, используя любые слова. Он говорит до тех пор, пока в его высказывании встретится одно из пяти ключевых слов. Эта система в настоящее время обслуживает около миллиарда звонков в год.Данный вывод находится в противоречии с устоявшимися широко распространенными стереотипами и ожиданиями.Несмотря на то, что одним из наиболее перспективных направлений для внедрения систем распознавания речи может стать сфера компьютерных игр, узкоспециализированных реабилитационных программ для инвалидов, тепефонных и информационных систем, ведущие разработчики речевого распознавания наращивают усилия по достижению универсализации и увеличения объемов словаря даже в ущерб сокращению процедуры предварительной настройки на диктора. А между тем именно эти приложения представляют очень низкие требования к объему распознаваемого словаря наряду с жесткими ограничения, налагаемыми на предварительную настройку.Более того распознавание спонтанной слитной речи практически топчется на месте с ^ 70-х годовв силу неспособности компьютера эффективно анализировать неакустические характеристики речи.Даже Билл Гейтс, являющий собой смысле идеал прагматизма, оказался не свободен от исторически сложившихся стереотипов. Начав в 95-96 году с разработки собственной универсальной системы распознавания речи провозгласил очередную эру повсеместного внедрения речевого интерфейса. Средства речевого планируется включить в стандартную поставку новой версии - чисто офисной операционной системы. При этом руководитель Microsoft упорно повторяет фразу о том, что скоро можно будет забыть о клавиатуре и мыши. Вероятно, он планирует продавать вместе с коробкой Windows NT акустические шлемы вроде тех, которые используют военные летчики и пилоты "Формулы 1". Кроме того, неужели Microsoft в ближайшем будущем npeкратит выпycк Word, Excel и т. д.? Управлять графическими объектами экрана голосом, не имея возможности помочь руками, более чем затруднительно.
Говоря о речевом интерфейсе, часто делают упор на распознавание речи, забывая о другой его стороне- речевом синтезе.
Заглавную роль в этом перекосе сыграло бурное развитие в последнее время систем, ориентированных на события ,в значительной степени подавляющих отношение к компьютеру как активной стороне диалога.Еще относительно недавно (лет тридцать назад) подсистемы распознавания и синтеза речи рассматривались как части единого комплекса речевого интерфейса. Однако интерес к синтезу пропал достаточно быстро. Во-первых, разработчики не встретили даже десятой доли сложностей, с которыми они столкнулись при создании систем распознавания. Во-вторых, в отличие от распознавания синтез речи не демонстрирует значительных преимуществ перед другими средствами вывода информации из компьютера. Практически вся его ценность заключается в дополнении речевого ввода.Для человека естественным и привычным является именно диалог, а не монолог. Как следствие недооценки необходимости речевого ответа появляется повышенная утомляемость операторов, монотонность речи и ограниченность применимости речевого интерфейса. Чем может помочь слепому компьютер, оснащенный распознавателем речи, если он лишен устройства обратной не визуальной связи? Широко известен факт непроизвольной подстройки голоса под голос собеседника. Почему не использовать эту способность человека для увеличения безошибочности распознавания речи компьютером за счет корректировки произношения оператора с помощью двустороннего диалога? Кроме того, вполне возможно, что правильно организованный и модулированный синтез может в значительной степени снизить риск появления у оператора заболеваний, связанных с монотонностью речи и дополнительным напряжением. Повсеместное проникновение графического пользовательского интерфейса было обеспечено за счет совместного применения графического монитора, средства вывода графической информации, и мыши- для ее ввода, а также, не в последнюю очередь, благодаря гениальным концептуальным находкам в области оконного интерфейса фирмы Xerox. Будущее речевого интерфейса в не меньшей степени зависит от умения современных разработчиков не только создать технологическую основу речевого ввода, но и гармонично слить технологические находки в единую логически завершенную систему взаимодействия "человек-компьютер".
Признаковые системы
В них усредненное изображение каждого символа представляется как объект в n-мерном пространстве признаков. Здесь выбирается алфавит признаков, значения которых вычисляются при распознавании входного изображения. Полученный n-мерный вектор сравнивается с эталонными, и изображение относится к наиболее подходящему из них. Признаковые системы не отвечают принципу целостности. Необходимое, но недостаточное условие целостности описания класса объектов (в нашем случае это класс изображений, представляющих один символ)состоит в том, что описанию должны удовлетворять все объекты данного класса и ни один из объектов других классов. Но поскольку при вычислении признаков теряется существенная часть информации, трудно гарантировать, что к данному классу удастся отнести только объекты.
Продукционные модели.
Продукции наряду с фреймами являются наиболее популярными средствами представления знаний в ИС. Продукции, с одной стороны, близки к логическим моделям, что позволяет организовывать на них эффективные процедуры вывода, а с другой стороны, более наглядно отражают знания, чем классические логические модели. В них отсутствуют жесткие ограничения, характерные для логических исчислений, что дает возможность изменять интерпретацию элементов продукции.
В общем виде под продукцией понимается выражение следующего вида:
(i); Q; Р; А=>В; N.
Здесь i-имя продукции, с помощью которого данная продукция выделяется из всего множества продукций. В качестве имени может выступать некоторая лексема, отражающая суть данной продукции (например, "покупка книги" или "набор кода замка"), или порядковый номер продукции в их множестве, хранящемся в памяти системы.
Элемент Q характеризует сферу применения продукции. Такие сферы легко выделяются в когнитивных структурах человека. Наши знания как бы "разложены по полочкам". На одной "полочке" хранятся знания о том, как надо готовить пищу, на другой-как добраться до работы и т. п. Разделение знаний на отдельные сферы позволяет экономить время на поиск нужных знаний. Такое же разделение на сферы в базе знаний ИС целесообразно и при использовании для представления знаний продукционных моделей.
Основным элементом продукции является ее ядро: А=>В. Интерпретация ядра продукции может быть различной и зависит от того, что стоит слева и справа от знака секвенции =>. Обычное прочтение ядра продукции выглядит так: ЕСЛИ A, ТО B, более сложные конструкции ядра допускают в правой части альтернативный выбор, например, ЕСЛИ А, ТО B1, ИНАЧЕ B2. Секвенция может истолковываться в обычном логическом смысле как знак логического следования В из истинного А (если А не является истинным выражением, то о В ничего сказать нельзя). Возможны и другие интерпретации ядра продукции, например A описывает некоторое условие, необходимое для того, чтобы можно было совершить действие В.
Элемент Р есть условие применимости ядра продукции. Обычно Р представляет собой логическое выражение (как правило, предикат). Когда Р принимает значение "истина", ядро продукции активизируется. Если Р ложно, то ядро продукции не может быть использовано. Например, если в продукции "НАЛИЧИЕ ДЕНЕГ; ЕСЛИ ХОЧЕШЬ КУПИТЬ ВЕЩЬ X, ТО ЗАПЛАТИ В КАССУ ЕЕ СТОИМОСТЬ И ОТДАЙ ЧЕК ПРОДАВЦУ" условие применимости ядра продукции ложно, т. е. денег нет, то применить ядро продукции невозможно.
Элемент N описывает постусловия продукции. Они актуализируются только в том случае, если ядро продукции реализовалось. Постусловия продукции описывают действия и процедуры, которые необходимо выполнить после реализации В. Например, после покупки некоторой вещи в магазине необходимо в описи товаров, имеющихся в этом магазине, уменьшить количество вещей такого типа на единицу. Выполнение N может происходить не сразу после реализации ядра продукции.
Если в памяти системы хранится некоторый набор продукций, то они образуют систему продукций. В системе продукций должны быть заданы специальные процедуры управления продукциями, с помощью которых происходит актуализация продукций и выбор для выполнения той или иной продукции из числа актуализированных.
В ряде ИС используются комбинации сетевых и продукционных моделей представления знаний. В таких моделях декларативные знания описываются в сетевом компоненте модели, а процедурные знания - в продукционном. В этом случае говорят о работе продукционной системы над семантической сетью.
Продукционные системы
Продукции наряду с фреймами являются наиболее популярными средствами представления знаний в ИИ. Продукции, с одной стороны, близки к логическим моделям, что позволяет организовывать на них эффективные процедуры вывода, а с другой стороны, более наглядно отражают знания, чем классические логические модели. В них отсутствуют жесткие ограничения, характерные для логических исчислений, что дает возможность изменять интерпретацию элементов продукции.
Распознавание рукописных текстов
Очевидно, проблема распознавания рукописного текста значительно сложнее, чем в случае с текстом печатным. Если в последнем случае мы имеем дело с ограниченным числом вариаций изображений шрифтов (шаблонов), то в случае рукописного текста число шаблонов неизмеримо больше. Дополнительные сложности вносят также иные соотношения линейных размеров элементов изображений и т. п.
И все же сегодня мы можем признать, что основные этапы разработки технологии распознавания рукописных (отдельные символы, написанные от руки) символов уже пройдены. В арсенале Cognitive Technologies имеются технологии распознавания всех основных типов текстов: стилизованных цифр, печатных символов и символов. Но технологии ввода символов потребуется еще пройти стадию адаптации, после чего можно будет заявить, что инструментарий для потокового ввода документов в архивы действительно реализован полностью.
Распознавание символов
Сегодня известно три подхода к распознаванию символов - шаблонный, структурный и признаковый. Но принципу целостности отвечает лишь первые два.
Шаблонное описание проще в реализации, однако, в отличие от структурного, оно не позволяет описывать сложные объекты с большим разнообразием форм. Именно поэтому шаблонное описание применяется для распознавания лишь печатных символов, в то время как структурное - для рукописных, имеющих, естественно, гораздо больше вариантов начертания.
Расширение прототипа до приложения
Конечный пользователь предлагает этапность проведения работ, направления развития базы знаний, указывает пропуски в ней. Разработчик может расширять и модифицировать базу знаний в присутствии пользователя даже в тот момент, когда приложение исполняется. В ходе этой работы прототип развивается до такого состояния, что начинает удовлетворять представлениям конечного пользователя. В крупных приложениях команда разработчиков может разбить приложение на отдельные модули, которые интегрируются в единую базу знаний.
Возможен и альтернативный подход к созданию приложения. При этом подходе каждый разработчик имеет доступ к базе знаний, находящейся на сервере, при помощи средства, называемого Telewindows, обычно расположенного на компьютереклиенте. В этом случае разработчики могут иметь различные авторизованные уровни доступа к приложению. Приложение может быть реализовано не только на различных ЭВМ, но и с использованием нескольких взаимодействующих оболочек G2.
Разработка прототипа приложения
Разработчиком обычно является специалист в конкретной области знаний. Он в ходе обсуждений с конечным пользователем определяет функции, выполняемые прототипом. При разработке прототипа не используется традиционное программирование. Создание прототипа обычно занимает от одной до двух недель (при наличии у разработчика опыта по созданию приложений в данной среде. Прототип, как и приложение, создается на структурированном естественном языке, с использованием объектной графики, иерархии классов объектов, правил, динамических моделей внешнего мира. Многословность языка сведена к минимуму путем введения операции клонирования, позволяющей размножить любую сущность базы знаний.
Речевой вывод информации
Речевой вывод информации из компьютера - проблема не менее важная, чем речевой ввод. Это вторая часть речевого интерфейса, без которой разговор с компьютером не может состояться. Мы имеем в виду прочтение вслух текстовой информации, а не проигрывание заранее записанных звуковых файлов. То есть выдачу в речевой форме заранее не известной информации. Фактически, благодаря синтезу речи по тексту открывается еще один канал передачи данных от компьютера к человеку, аналогичный тому, какой мы имеем благодаря монитору. Конечно,трудновато было бы передать рисунок голосом. Но вот услышать электронную почту или результат поиска в базе данных в ряде случаев было бы довольно удобно, особенно если в это время взгляд занят чем-либо другим.
С точки зрения пользователя, наиболее разумное решение проблемы синтеза речи - это включение речевых функций (в перспективе - многоязычных, с возможностями перевода) в состав операционной системы. Точно так же, как мы пользуемся командой РRINT, мы будем применять команду ТАLК или SРЕАК. Такие команды появятся в меню общеупотребительных компьютерных приложений и в языках программирования. Компьютеры будут озвучивать навигацию по меню, читать (дублировать голосом) экранные сообщения, каталоги файлов, и т. д. Важное замечание: пользователь должен иметь достаточные возможности по настройке голоса компьютера, в частности, при желании, суметь выключить голос совсем.
Вышеупомянутые функции и сейчас были бы не лишними для лиц, имеющих проблемы со зрением. Для всех остальных они создадут новое измерение удобства пользования компьютером и значительно снизят нагрузку на нервную систему и на зрение. По нашему мнению, сейчас не стоит вопрос, нужны синтезаторы речи в персональных компьютерах или нет. Вопрос в другом - когда они будут установлены на каждом компьютере. Осталось ждать, может быть, год или два.
Решение задач дедуктивного выбора
В дедуктивных моделях представления и обработки знании решаемая проблема записывается в виде утверждении формальной системы, цель-в виде утверждения, справедливость которого следует установить или опровергнуть на основании аксиом (общих законов) и правил вывода формальной системы. В качестве формальной системы используют исчисление предикатов первого порядка.
В соответствии с правилами, установленными в формальной системе, заключительному утверждению-теореме, полученной из начальной системы утверждений (аксиом, посылок), приписывается значение ИСТИНА, если каждой посылке, аксиоме также приписано значение ИСТИНА.
Процедура вывода представляет собой процедуру , которая из заданной группы выражений выводит отличное от заданных выражение.
Обычно в логике предикатов используется формальный метод доказательства теорем, допускающий возможность его машинной реализации, но существует также возможность доказательства неаксиоматическим путем : прямым выводом, обратным выводом.
Метод резолюции используется в качестве полноценного (формального) метода доказательства теорем.
Для применения этого метода исходную группу заданных логических формул требуется преаобразовать в некоторую нормальную форму. Это преобразование проводится в несколько стадий, составляющих машину вывода.
Решение задач, использующие немонотонные логики, вероятностные логики.
Данные и знания, с которыми приходится иметь дело в ИС, редко бывают абсолютно точными и достоверными. Присущая знаниям неопределенность может иметь разнообразный характер, и для ее описания используется широкий спектр формализмов. Рассмотрим один из типов неопределенности в данных и знаниях - их неточность. Будем называть высказывание неточным, если его истинность (или ложность) не может быть установлена с определенностью. Основополагающим понятием при построении моделей неточного вывода является понятие вероятности, поэтому все описываемые далее методы связаны с вероятностной концепцией.
Модель оперирования с неточными данными и знаниями включает две составляющие: язык представления неточности и механизм вывода на неточных знаниях. Для построения языка необходимо выбрать форму представления неточности (например, скаляр, интервал, распределение, лингвистическое выражение, множество) и предусмотреть возможность приписывания меры неточности всем высказываниям.
Механизмы оперирования с неточными высказываниями можно разделить на два типа. К первому относятся механизмы, носящие "присоединенный" характер: пересчет мер неточности как бы сопровождает процесс вывода, ведущийся на точных высказываниях. Для разработки присоединенной модели неточного вывода в основанной на правилах вывода системе необходимо задать функции пересчета, позволяющие вычислять: а) меру неточности антецедента правила (его левой части) по мерам неточности составляющих его высказываний; б) меру неточности консеквента правила (его правой части) по мерам неточности правила и посылки правила; в) объединенную меру неточности высказывания по мерам, полученным из правил.
Введение меры неточности позволит привнести в процесс вывода нечто принципиально новое - возможность объединения силы нескольких свидетельств, подтверждающих или опровергающих одну и ту же гипотезу. Другими словами, при использовании мер неточности целесообразно выводить одно и то же утверждение различными путями (с последующим объединением значений неточности), что совершенно бессмысленно в традиционной дедуктивной логике.
Для объединения свидетельств требуется функция пересчета, занимающая центральное место в пересчете. Заметим, что, несмотря на "присоединенность" механизмов вывода этого типа, их реализация в базах знаний оказывает влияние на общую стратегию вывода: с одной стороны, необходимо выводить гипотезу всеми возможными путями для того, чтобы учесть все релевантные этой гипотезе свидетельства, с другой-предотвратить многократное влияние силы одних и тех же свидетельств.
Для механизмов оперирования с неточными высказываниями второго типа характерно наличие схем вывода, специально ориентированных на используемый язык представления неточности. Как правило, каждому шагу вывода соответствует пересчет мер неточности, обусловленный соотношением на множестве высказываний (соотношением может быть элементарная логическая связь, безотносительно к тому, является ли это отношение фрагментом какого-либо правила). Таким образом, механизмы второго типа применимы не только к знаниям, выраженным в форме правил. Вместе с тем для них, как и для механизмов "присоединенного" типа, одной из главных является проблема объединения свидетельств.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Решение задач методом поиска в пространстве состояний.
Представление задач в пространстве состояний предполагает задание ряда описаний: состояний, множества операторов и их воздействий на переходы между состояниями, целевых состояний. Описания состояний могут представлять собой строки символов, векторы, двухмерные массивы, деревья, списки и т. п. Операторы переводят одно состояние в другое. Иногда они представляются в виде продукций A=>B, означающих, что состояние А преобразуется в состояние В.
Пространство состояний можно представить как граф, вершины которого помечены состояниями, а дуги - операторами.
Таким образом, проблема поиска решения задачи <А,В> при планировании по состояниям представляется как проблема поиска на графе пути из А в В. Обычно графы не задаются, а генерируются по мере надобности.
Различаются слепые и направленные методы поиска пути. Слепой метод имеет два вида: поиск вглубь и поиск вширь. При поиске вглубь каждая альтернатива исследуется до конца, без учета остальных альтернатив. Метод плох для "высоких" деревьев, так как легко можно проскользнуть мимо нужной ветви и затратить много усилий на исследование "пустых" альтернатив. При поиске вширь на фиксированном уровне исследуются все альтернативы и только после этого осуществляется переход на следующий уровень. Метод может оказаться хуже метода поиска вглубь, если в графе все пути, ведущие к целевой вершине, расположены примерно на одной и той же глубине. Оба слепых метода требуют большой затраты времени и поэтому необходимы направленные методы поиска.
Метод ветвей и границ. Из формирующихся в процессе поиска неоконченных путей выбирается самый короткий и продлевается на один шаг. Полученные новые неоконченные пути (их столько, сколько ветвей в данной вершине) рассматриваются наряду со старыми, и вновь продлевается на один шаг кратчайший из них. Процесс повторяется до первого достижения целевой вершины, решение запоминается. Затем из оставшихся неоконченных путей исключаются более длинные, чем законченный путь, или равные ему, а оставшиеся продлеваются по такому же алгоритму до тех пор, пока их длина меньше законченного пути.
Этот метод приводит к хорошим результатам потому, что часто решение задач имеет иерархическую структуру. Однако не обязательно требовать, чтобы основная задача и все ее подзадачи решались одинаковыми методами. Редукция полезна для представления глобальных аспектов задачи, а при решении более специфичных задач предпочтителен метод планирования по состояниям. Метод планирования по состояниям можно рассматривать как частный случай метода планирования с помощью редукций, ибо каждое применение оператора в пространстве состояний означает сведение исходной задачи к двум более простым, из которых одна является элементарной. В общем случае редукция исходной задачи не сводится к формированию таких двух подзадач, из которых хотя бы одна была элементарной. Поиск планирования в пространстве задач заключается в последовательном сведении исходной задачи к все более простым до тех пор, пока не будут получены только элементарные задачи. Частично упорядоченная совокупность таких задач составит решение исходной задачи. Расчленение задачи на альтернативные множества подзадач удобно представлять в виде И/ИЛИ-графа. В таком графе всякая вершина, кроме концевой, имеет либо конъюнктивно связанные дочерние вершины (И-вершина), либо дизъюнктивно связанные (ИЛИ-вершина). В частном случае, при отсутствии И-вершин, имеет место граф пространства состояний. Концевые вершины являются либо заключительными (им соответствуют элементарные задачи), либо тупиковыми. Начальная вершина (корень И/ИЛИ-графа) представляет исходную задачу. Цель поиска на И/ИЛИ-графе-показать, что начальная вершина разрешима. Разрешимыми являются заключительные вершины (И-вершины), у которых разрешимы все дочерние вершины, и ИЛИ-вершины, у которых разрешима хотя бы одна дочерняя вершина. Разрешающий граф состоит из разрешимых вершин и указывает способ разрешимости начальной вершины. Наличие тупиковых вершин приводит к неразрешимым вершинам. Неразрешимыми являются тупиковые вершины, И-вершины, у которых неразрешима хотя бы одна дочерняя вершина, и ИЛИ-вершины, у которых неразрешима каждая дочерняя вершина.
В итоге либо все неоконченные пути исключаются, либо среди них формируется законченный путь, более короткий, чем ранее полученный. Последний путь начинает играть роль эталона и т. д.
Алгоритм кратчайших путей Мура. Исходная вершина X0 помечается числом 0. Пусть в ходе работы алгоритма на текущем шаге получено множество дочерних вершин X(xi) вершины xi. Тогда из него вычеркиваются все ранее полученные вершины, оставшиеся помечаются меткой, увеличенной на единицу по сравнению с меткой вершины xi, и от них проводятся указатели к Xi. Далее на множестве помеченных вершин, еще не фигурирующих в качестве адресов указателей, выбирается вершина с наименьшей меткой и для нее строятся дочерние вершины. Разметка вершин повторяется до тех пор, пока не будет получена целевая вершина.
Алгоритм Дейкстры определения путей с минимальной стоимостью является обобщением алгоритма Мура за счет введения дуг переменной длины.
Алгоритм Дорана и Мичи поиска с низкой стоимостью. Используется, когда стоимость поиска велика по сравнению со стоимостью оптимального решения. В этом случае вместо выбора вершин, наименее удаленных от начала, как в алгоритмах Мура и Дийкстры, выбирается вершина, для которой эвристическая оценка расстояния до цели наименьшая. При хорошей оценке можно быстро получить решение, но нет гарантии, что путь будем минимальным.
Алгоритм Харта, Нильсона и Рафаэля. В алгоритме объединены оба критерия: стоимость пути до вершины g[x) и стоимость пути от вершины h(x) - в аддитивной оценочной функции f{x) =g(x}-h(x). При условии h(x)<hp(x), где hp(x)-действительное расстояние до цели, алгоритм гарантирует нахождение оптимального пути.
Алгоритмы поиска пути на графе различаются также направлением поиска. Существуют прямые, обратные и двунаправленные методы поиска. Прямой поиск идет от исходного состояния и, как правило, используется тогда, когда целевое состояние задано неявно. Обратный поиск идет от целевого состояния и используется тогда, когда исходное состояние задано неявно, а целевое явно.Двунаправленный поиск требует удовлетворительного решения двух проблем: смены направления поиска и оптимизации "точки встречи". Одним из критериев для решения первой проблемы является сравнение "ширины" поиска в обоих направлениях - выбирается то направление, которое сужает поиск. Вторая проблема вызвана тем, что прямой и обратный пути могут разойтись и чем уже поиск, тем это более вероятно.
Решение задач методом редукции.
Алгоритм Ченга и Слейгла. Основан на преобразовании произвольного И/ИЛИ-графа в специальный ИЛИ-граф, каждая ИЛИ-ветвь которого имеет И-вершины только в конце. Преобразование использует представление произвольного И/ИЛИ-графа как произвольной формулы логики высказываний с дальнейшим преобразованием этой произвольной формулы в дизъюнктивную нормальную форму. Подобное преобразование позволяет далее использовать алгоритм Харта, Нильсона и Рафаэля.
Метод ключевых операторов. Пусть задана задача <A, B> и известно, что оператор f обязательно должен входить в решение этой задачи. Такой оператор называется ключевым. Пусть для применения f необходимо состояние C, а результат его применения есть I(c). Тогда И-вершина <A,В> порождает три дочерние вершины: <A, C>, <C, f{c)> и <f(c), B>, из которых средняя является элементарной задачей. К задачам <A, С> и <f(c), B> также подбираются ключевые операторы, и указанная процедура редуцирования повторяется до тех пор, пока это возможно. В итоге исходная задача <A, B> разбивается на упорядоченную совокупность подзадач, каждая из которых решается методом планирования в пространстве состояний.
Возможны альтернативы по выбору ключевых операторов, так что в общем случае будет иметь место И/ИЛИ-граф. В большинстве задач удается не выделить ключевой оператор, а только указать множество, его содержащее. В этом случае для задачи <A, B> вычисляется различие между A и B, которому ставится в соответствие оператор, устраняющий это различие. Последний и является ключевым.
Метод планирования общего решателя задач (ОРЗ). ОРЗ явился первой наиболее известной моделью планировщика. Он использовался для решения задач интегрального исчисления, логического вывода, грамматического разбора и др. ОРЗ объединяет два основных принципа поиска:
анализ целей и средств и рекурсивное решение задач. В каждом цикле поиска ОРЗ решает в жесткой последовательности три типа стандартных задач: преобразовать объект А в объект В, уменьшить различие D между А и В, применить оператор f к объекту А. Решение первой задачи определяет различие D второй - подходящий оператор f, третьей - требуемое условие применения С. Если С не отличается от A, то оператор f применяется, иначе С представляется как очередная цель и цикл повторяется, начиная с задачи "преобразовать A в С".
В целом стратегия ОРЗ осуществляет обратный поиск-от заданной цели В к требуемому средству ее достижения С, используя редукцию исходной задачи <A, В> к задачам <A, C> и <С, В>.
Заметим, что в ОРЗ молчаливо предполагается независимость различий Друг от друга, откуда следует гарантия, что уменьшение одних различий не приведет к увеличению других.
3. Планирование с помощью логического вывода. Такое планирование предполагает: описание состояний в виде правильно построенных формул (ППФ) некоторого логического исчисления, описание операторов в виде либо ППФ, либо правил перевода одних ППФ в другие. Представление операторов в виде ППФ позволяет создавать дедуктивные методы планирования, представление операторов в виде правил перевода - методы планирования с элементами дедуктивного вывода.
Дедуктивный метод планирования системы QA3, ОРЗ не оправдал возлагавшихся на него надежд в основном из-за неудовлетворительного представления задач. Попытка исправить положение привела к созданию вопросно-ответной системы QA3. Система рассчитана на произвольную предметную область и способна путем логического вывода ответить на вопрос: возможно ли достижение состояния В из A? В качестве метода автоматического вывода используется принцип резолюций. Для направления логического вывода QA3 применяет различные стратегии, в основном синтаксического характера, учитывающие особенности формализма принципа резолюций. Эксплуатация QA3 показала, что вывод в такой системе получается медленным, детальным, что несвойственно рассуждениям человека.
Метод продукций системы STRIPS. В этом методе оператор представляет продукцию Р, А=>В, где Р, А и В - множества ППФ исчисления предикатов первого порядка, Р выражает условия применения ядра продукции А=>В, где В содержит список добавляемых ППФ и список исключаемых ППФ, т. е. постусловия. Метод повторяет метод ОРЗ с тем отличием, что стандартные задачи определения различий и применения подходящих операторов решаются на основе принципа резолюций.Подходящий оператор выбирается так же, как в ОРЗ, на основе принципа "анализ средств и целей". Наличие комбинированного метода планирования позволило ограничить процесс логического вывода описанием состояния мира, а процесс порождения новых таких описаний оставить за эвристикой "от цели к средству ее достижения".
Метод продукций, использующий макрооператоры [Файкс и др., 1973]. Макрооператоры-это обобщенные решения задач, получаемые методом STRIPS. Применение макрооператоров позволяет сократить поиск решения, однако при этом возникает проблема упрощения применяемого макрооператора, суть которой заключается в выделении по заданному различию его требуемой части и исключении из последней ненужных операторов.
Динамичное развитие новых компьютерных технологий
Динамичное развитие новых компьютерных технологий (сетевые технологии, технологии , и т. д.) нашли свое отражение и в состоянии сектора электронного документооборота. Если раньше в продвижении технологий бесклавиатурного ввода делался упор на преимущества их персонального использования, то сегодня на первый план выходят преимущества коллективного и рационального использования технологий ввода и обработки документов. Иметь одну, обособленную систему распознавания сегодня уже явно недостаточно. С распознанными текстовыми файлами (как бы хорошо они распознаны ни были) нужно что-то делать: хранить в базе данных, осуществлять их поиск, передавать по локальной сети, и т. д. Словом, требуется взаимодействие с архивной или иной системой работы с документами. Таким образом, система распознавания превращается в утилиту для архивных и иных систем работы с документами.
С появлением сетевых версий систем сканирования (режим потокового сканирования OCR CuneiForm) и распознавания (сервер распознавания CuneiForm OCR Server) документов нашей компании уже удалось реализовать некоторые преимущества коллективного использования таких технологий в организациях разного масштаба. По этой причине, с нашей точки зрения, актуальным был бы разговор о комплексном решении компаниями проблемы автоматизации работы с документами в организациях самого различного ранга. Что касается Cognitive Technologies, то представляемый ею электронный архив (система включает в себя возможность ввода документов с помощью OCR CuneiForm), новые утилиты, встроенные в OCR CuneiForm'96, и технологии, используемые при реализации крупных проектов, продолжают линию компании, направленную на расширение применения систем ввода информации и разработку технологий автоматизации работы с документами.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Сценарии.
Особую роль в системах представления знаний играют стереотипные знания, описывающие известные стандартные ситуации реального мира. Такие знания позволяют восстанавливать информацию, пропущенную в описании ситуации, предсказывать появление новых фактов, которых можно ожидать в данной ситуации, устанавливать смысл происхождения ситуации с точки зрения более общего ситуативного контекста.
Для описания стереотипного знания используются различные модели. Среди них наиболее распространенными являются сценарии. Сценарием называется формализованное описание стандартной последовательности взаимосвязанных фактов, определяющих типичную ситуацию предметной области. Это могут быть последовательности действий или процедур, описывающие способы достижения целей действующих лиц сценария (например, обед в ресторане, командировка, полет самолета, поступление в вуз). В ИС сценарии используются в процедурах понимания естественно-языковых текстов, планирования поведения, обучения, принятия решений, управления изменениями среды и др.
Сетевые модели
Введем ряд определений. Под сущностью будем понимать объект произвольной природы. Этот объект может существовать в реальном мире. В этом случае он будет называться П-сущностью. В базе знаний ему соответствует некоторое описание, полнота которого определяется той информацией, которую имеет о П-сущности ИС. Такое представление в базе знаний называется М-сущностью. Отметим, что могут существовать М-сущности, для которых в окружающем ИС мире нет соответствующих П-сущностей. Такие М-сущности представляют собой абстрактные объекты, полученные в результате операций типа обобщения внутри базы знаний.
Разделение на два типа сущностей позволяет использовать в сетевых моделях идеи, впервые сформулированные в теории семиотических моделей и основанном на них ситуационном управлении. Под семиотическими моделями проблемных областей будет пониматься комплекс процедур, позволяющих отображать в базе знаний П-сущности и их связи, фиксируемые в проблемной области инженером по знаниям, в совокупность связанных между собой М-сущностей. Способ интерпретации взаимосвязанных П-сущностей будет называться денотативной семантикой, а способ интерпретации взаимосвязанных М-сущностей - коннотативной семантикой.
П-сущность по отношению к соответствующей ей в базе знаний М-сущности называется денотатом или референтом этой М-сущности, а М-сущность по отношению к исходной П-сущности - ее десигнатом, именем, меткой, идентификатором и т. п. Десигнат-это простейший элемент в сетевой модели. Он входит в класс терминальных объектов сетевой модели. Терминальным объектом называется М-сущность, которая не может быть разложена на более простые сущности. Остальные М-сущности называются производными объектами или производными М-сущностями.
Перечень терминальных объектов, которые могут образовывать классы или типы, задается при проектировании ИС. Ими могут быть целые вещественные числа, идентификаторы, строки, списки и т. п. Семантика терминальных объектов определяется набором допустимых процедур, оперирующих с ними, например: арифметические действия над числами, сравнение между собой строк или идентификаторов, операции ввода-вывода, включающие необходимые трансформации представлений, и т. д.
Шаблонные системы
Такие системы преобразуют изображение отдельного символа в растровое, сравнивают его со всеми шаблонами, имеющимися в базе и выбирают шаблон с наименьшим количеством точек, отличных от входного изображения. Шаблонные системы довольно устойчивы к дефектам изображения и имеют высокую скорость обработки входных донных, но надежно распознают только те шрифты, шаблоны которых им "известны". И если распознаваемый шрифт хоть немного отличается от эталонного, шаблонные системы могут делать ошибки даже при обработке очень качественных изображений!
Системы приобретения знаний от экспертов
Одно из первых рассмотрении интервью как метода инженерии знаний проведено в [Newel 1972], Проблемы, возникающие при извлечении экспертных знаний, некоторые психологи связывают с так называемой когнитивной защитой. В [Kelly, 1985] была развита теория человеческого познания, основанная на понятии "персональных конструктов", которые человек создает и пытается приспособить к реалиям мира. В [Bose, 1984] теория персональных конструктов использована для создания системы извлечения экспертных знаний и показала свою способность успешно преодолевать когнитивную защиту, т. е. нежелание экспертов достичь четкого и осознанного ими истолкования основных понятий, отношений между понятиями и приемов решения задач в интересующей инженера по знаниям проблемной области.
Методы интервьюирования эксперта предметной области знаний с использованием нескольких различных стратегий применены при создании системы TEIRESIAS [Davis, 1982]. В [Kahn et aL, 1984] выделено восемь различных стратегий интервью, в [Kahn et aL, 1985] на основе этих стратегий исследуется возможность автоматического интервьюирования. Автоматизации метода протокольного анализа посвящены работы [Waterman, 1971, 1973; Krippendorf, 1980].
В [Kahn et al. 1985] на примере диагностической системы MORE; описана техника интервьюирования, направленная на выяснение следующих сущностей, гипотез, симптомов, условий, связей и путей. Гипотеза - событие идентификация которого имеет своим результатом диагноз. Симптом-событие, являющееся следствием существования гипотезы, наблюдение которого приближает последующее принятие гипотезы. Условие - событие или некоторое множество событий, которое не является непосредственно симптоматическим для какой-либо гипотезы, но которое может иметь диагностическое значение для некоторых других событий. Связи-соединения сущностей (в том числе, других связей). Путь- выделенный тип связи, который соединяет гипотезы с симптомами. В соответствии с этим используются следующие стратегии интервью: дифференциация гипотез, различение симптомов, симптомная обусловленность, деление пути и др.
Дифференциация гипотез направлена на поиск симптомов, которые обеспечивают более точное различение гипотез. Наиболее мощными в этом смысле являются те симптомы, которые происходят из одного диагностируемого события, Различение симптомов выявляет специфические характеристики симптома, которые, с одной стороны, идентифицируют его как следствие некоторой гипотезы, с другой-противопоставляют другим. Симптомная обусловленность направлена на выявление негативных симптомов, т. е. симптомов, отсутствие которых имеет больший диагностический вес, чем их присутствие. Деление пути обеспечивает нахождение симптоматических событий, которые лежат на пути к уже найденному симптому. Если такой симптом существует, то он имеет большое диагностическое значение, чем уже найденный.
Аналогичные стратегии интервьюирования эксперта использованы при создании инструментальной диагностической системы ИДИС [Голубев и др., 1987].
В системе KRITON [Diederich et aL, 1987] для приобретения знаний используются два источника: эксперт с его знаниями, полученными на практике (эти знания, как правило, неполны, отрывочны, плохо структурированы); книжные знания, документы, описания инструкции (эти знания хорошо структурированы и фиксированы традиционными средствами). Для извлечения знаний из первого источника в KRITON применена техника интервью, использующая стратегии репертуарной решетки и разбиения на ступени. При этом применяется прием переключения стратегий: если при предъявлении тройки семантически связанных понятий эксперт не в состоянии назвать признак, отличающий два из них от третьего, система запускает стратегию разбиения на ступени и предпринимает попытку выяснения таксономической структуры этих понятий с целью выявления признаков, их различающих.
Для выявления процедурных знаний эксперта в KRITON применен метод протокольного анализа. Он осуществляется в пять шагов. На первом шаге протокол делится на сегменты на основании пауз, которые делает эксперт в процессе записи. Второй шаг-семантический анализ сегментов, формирование высказываний для каждого сегмента.
На третьем шаге из текста выделяются операторы и аргументы. Далее делается попытка поиска по образцу в базе знаний для обнаружения переменных в высказываниях (переменная вставляется в высказывание, если соответствующая ссылка в тексте не обнаружена). На последнем шаге утверждения упорядочиваются в соответствии с их появлением в протоколе.
Анализ текста используется в KRITON для выявления хорошо структурированных знаний из книг, документов, описаний, инструкций.
В [Morik, 1987] описан метод выявления модели предметной области. Первая фаза-формирование инженером знаний грубой модели предметной области путем определения предикатов и сортов их возможных аргументов и сообщения системе фактов об области, выразимых этими предикатами. Система выявляет свойства предикатов и устанавливает отношения между ними, структурируя таким образом предметную область. На второй фазе с помощью метазнаний (общих структур), отражающих особенности человеческого мышления, осуществляется проверка соответствия фактов предикатам, индуктивный вывод правил из фактов, вывод правил из других правил.
В системах SIMER и ДИАПС [Осипов. 1987; Osipov et aL, 1987] основным методом приобретения знаний является автоматизированное интервьюирование эксперта, которое управляется знаниями, приобретенными системой. В системах SIMER и ДИАПС не выявляется предварительная модель области. Все объекты (события) и их атрибуты определяются в режиме прямого интервьюирования эксперта. Предполагается только, что на множестве объектов могут быть заданы ряд отношений из известного (конечного) множества: "элемент-множество", "часть - целое", "пример - прототип", отношения структурного сходства объектов, структурной иерархии и некоторые другие. Все отношения попарно различаются формальными свойствами. Так, отношений структурного сходства не обладает транзитивностью, но симметрично. Отношение структурной иерархии. напротив, не обладает симметричностью, однако транзитивно. На выяснение этих и ряда других свойств отношений и объектов направлено интервью.
В частности, для установления структурного сходства на первой фазе интервью для каждого вновь вводимого понятия эксперту предлагается указать (с помощью меню) те понятия предметной области, с которыми может быть связано данное (без спецификации отношения). Затем в процессе интервью для каждой пары понятий (из выделенных на первой фазе) связь специфицируется, устанавливаются свойства и тип отношения, в число элементов которого включается исследуемая пара. Так, для включения некоторой пары понятий Х и У. о которых эксперт сообщил, что Х влияет на У (например Х увеличивает возможность У), в число элементов некоторого отношения Я, обладающего среди прочих свойств симметричностью, необходимо задать эксперту вопрос: "Увеличивает ли У возможность ?". При положительном ответе на этот вопрос (и если прочие свойства уже установлены и удовлетворяют определению отношения Я) пара (X, У) включается в R,. Для установления структурного сходства и структурной иерархии понятий используются стратегии подтверждения сходства и разбиения на ступени.
В модели имеются метапроцедуры и метаправила, которые проверяют корректность модели, используют формальные свойства отношений для пополнения модели и генерируют правила.
Сформулируем основные этапы реализации системы приобретения знаний.
Интервью для определения актуальной области, в которой происходит процесс решения интересующей проблемы, и расчленение ее на автономные области. Автоматизированное интервью для выявления и формирования декларативной модели предметной области. Протокольный анализ к выявленным на предыдущем этапе понятиям и отношениям предметной области для пополнения модели процедурными знаниями.
(этапы 2 и 3 можно использовать попеременно до тех пор, пока модель не достигнет нужной полноты). Протокольный анализ для попонения декларативных знаний модели. б. Проверка полноты модели. Обычно протокольный анализ выявляет пустоты в модели. Имеется в виду случай, когда понятия, использованные в "мыслях вслух", недостаточно описаны.В этом случае интервью и протокольный анализ повторяются.
Сопровождение приложения
Не только сам разработчик данного приложения, но и любой пользователь может легко его понять и сопровождать, так как все объекты/классы, правила, процедуры, функции, формулы, модели хранятся в базе знаний в виде структурированного естественного языка и в виде графических объектов. Для ее просмотра используется возможность "Inspect". Сопровождение упрощается за счет того, что различным группам пользователей выдается не вся информация, а только ее часть, соответствующая их потребностям.
Состояние и тенденции развития искусственного интеллекта
Программные средства, базирующиеся на технологии и методах искусственного интеллекта, получили значительное распространение в мире. Их важность, и, в первую очередь, экспертных систем и нейронных сетей, состоит в том, что данные технологии существенно расширяют круг практически значимых задач, которые можно решать на компьютерах, и их решение приносит значительный экономический эффект. В то же время, технология экспертных систем является важнейшим средством в решении глобальных проблем традиционного программирования: длительность и, следовательно, высокая стоимость разработки приложений; высокая стоимость сопровождения сложных систем; повторная используемость программ и т.п. Кроме того, объединение технологий экспертных систем и нейронных сетей с технологией традиционного программирования добавляет новые качества к коммерческим продуктам за счет обеспечения динамической модификации приложений пользователем, а не программистом, большей "прозрачности" приложения (например, знания хранятся на ограниченном естественном языке, что не требует комментариев к ним, упрощает обучение и сопровождение), лучших графических средств, пользовательского интерфейса и взаимодействия. По мнению специалистов [1], в недалекой перспективе экспертные системы будут играть ведущую роль во всех фазах проектирования, разработки, производства, распределения, продажи, поддержки и оказания услуг. Их технология, получив коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей. Коммерческий рынок продуктов искусственного интеллекта в мире в 1993 году оценивался примерно в 0,9 млрд. долларов; из них 600 млн. приходится на долю США [2]. Выделяют несколько основных направлений этого рынка: 1) экспертные системы; теперь их часто обозначают еще одним термином - "системы, основанные на знаниях"; 2) нейронные сети и "размытые" (fuzzy) логики; 3) естественно-языковые системы. В США в 1993 году рынок между этими направлениями распределился так [2]: экспертные системы - 62%, нейронные сети - 26%, естественно-языковые системы - 12%.
Рынок этот можно разделить и иначе: на системы искусственного интеллекта (приложения) и инструментальные средства, предназначенные для автоматизации всех этапов существования приложения. В 1993 году в общем объеме рынка США доля приложений составила примерно две, а доля инструментария - примерно одну треть [2]. Одно из наиболее популярных направлений последних пяти лет связано с понятием автономных агентов. Их нельзя рассматривать как "подпрограммы", - это скорее прислуга, даже компаньон, поскольку одной из важнейших их отличительных черт является автономность, независимость от пользователя. Идея агентов опирается на понятие делегирования своих функций. Другими словами, пользователь должен довериться агенту в выполнении определенной задачи или класса задач. Всегда существует риск, что агент может что-то перепутать, сделать что-то не так. Следовательно, доверие и риск должны быть сбалансированными. Автономные агенты позволяют существенно повысить производительность работы при решении тех задач, в которых на человека возлагается основная нагрузка по координации различных действий.
В том, что касается автономных (интеллектуальных) агентов, хотелось бы отметить один весьма прагматический проект, который сейчас ведется под руководством профессора Генри Либермана в Media-лаборатории MIT (MIT Media Lab). Речь идет об агентах, отвечающих за автоматическое генерирование технической документации. Для решения этой задачи немало сделал в свое время академик Андрей Петрович Ершов, сформулировавший понятие деловой прозы как четко определенного подмножества естественного языка, которое может быть использовано, в частности, для синтеза технической документации (это одно из самых узких мест в любом производстве). Группа под руководством профессора Либермана исследует возможности нового подхода к решению этой проблемы, теперь уже на основе автономных агентов.
Следующее направление в области искусственной жизни - генетическое программирование (genetic programming) - является попыткой использовать метафору генной инженерии для описания различных алгоритмов.
Строки (string) искусственной "генетической" системы аналогичны хромосомам в биологических системах. Законченный набор строк называется структурой (structure). Структуры декодируются в набор параметров, альтернативы решений или точку в пространстве решений. Строки состоят из характеристик, или детекторов, которые могут принимать различные значения. Детекторы могут размещаться на разных позициях в строке. Все это сделано по аналогии с реальным миром. В природных системах полный генетический пакет называется генотипом. Организм, который образуется при взаимодействии генотипа с окружающей средой, носит название фенотипа. Хромосомы состоят из генов, которые могут принимать разные значения. (Например, ген цвета для глаза животного может иметь значение "зеленый" и позицию 10).
В генетических алгоритмах роль основных строительных блоков играют строки фиксированной длины, тогда как в генетическом программировании эти строки разворачиваются в деревья, столь знакомые специалистам в области трансляции. Например, выражение a+b*c выглядит так:
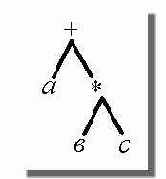
Средства представления знаний и стратегии управления
Комплекс ЭКО включает три компонента.
Ядром комплекса является интегрированная оболочка экспертных систем ЭКО, которая обеспечивает быстрое создание эффективных приложений для решения задач анализа в статических проблемных средах типа 1 и 2.
При разработке средств представления знаний оболочки преследовались две основные цели: эффективное решение достаточно широкого и практически значимого класса задач средствами персональных компьютеров; гибкие возможности по описанию пользовательского интерфейса и проведению консультации в конкретных приложениях. При представлении знаний в оболочке используются специализированные (частные) -утверждения типа "атрибут - значение" и частные правила, что позволяет исключить ресурсоемкую операцию сопоставления по образцу и добиться эффективности разрабатываемых приложений. Выразительные возможности оболочки удалось существенно расширить за счет интегрированности, обеспечиваемой путем вызова внешних программ через сценарий консультации и стыковки с базами данных (ПИРС и dBase IV) и внешними программами. В оболочке ЭКО обеспечивается слабая структуризация БЗ за счет ее разделения на отдельные компоненты - для решения отдельных подзадач в проблемной среде - модели (понятию "модель" ЭКО соответствует понятие "модуль" базы знаний системы G2).
С точки зрения технологии разработки ЭС оболочка поддерживает подходы, основанные на поверхностных знаниях и структурировании процесса решения.
Оболочка функционирует в двух режимах: в режиме приобретения знаний и в режиме консультации (решения задач). В первом режиме разработчик ЭС средствами диалогового редактора вводит в БЗ описание конкретного приложения в терминах языка представления знаний оболочки. Это описание компилируется в сеть вывода с прямыми адресными ссылками на конкретные утверждения и правила. Во втором режиме оболочка решает конкретные задачи пользователя в диалоговом или пакетном режиме. При этом решения выводятся от целей к данным (обратное рассуждение).
Для расширения возможностей оболочки по работе с глубинными знаниями комплекс ЭКО может быть дополнен компонентом К-ЭКО (конкретизатором знаний), который позволяет описывать закономерности в проблемных средах в терминах общих (абстрактных) объектов и правил. К-ЭКО используется на этапе приобретения знаний вместо диалогового редактора оболочки для преобразования общих описаний в конкретные сети вывода, допускающие эффективный вывод решений средствами оболочки ЭКО. Таким образом, использование конкретизатора обеспечивает возможность работы с проблемными средами типа 2 (см. гл.З).
Третий компонент комплекса - система ИЛИС, позволяющая создавать ЭС в статических проблемных средах за счет индуктивного обобщения данных (примеров) и предназначенная для использования в тех приложениях, где отсутствие правил, отражающих закономерности в проблемной среде, возмещается обширным экспериментальным материалом. Система ИЛИС обеспечивает автоматическое формирование простейших конкретных правил и автономное решение задач на их основе; при этом используется жесткая схема диалога с пользователем. Поскольку при создании реальных приложений эксперты представляют, как правило, и знания о закономерностях в проблемной среде, и экспериментальный материал (для решения частных подзадач), возникает необходимость в использовании правил, сформированных системой ИЛИС, в рамках более сложных средств представления знаний. Комплекс ЭКО обеспечивает автоматический перевод таких правил в формат оболочки ЭКО. В результате удается получить полное (адекватное) представление реальной проблемной среды, кроме того, задать гибкое описание организации взаимодействия ЭС с конечным пользователем.
Стратегии решений организации поиска
Для иллюстрации поиска предположим, что в базе знаний для представления знаний используется семантическая сеть (рис.2а) и продукция (рис.2б). Поиск А в базе знаний организуется различными способами. Можно, например, сначала искать вершину а. Если в базе знаний такой вершины нет, то поиск заканчивается неудачей. Если вершина а найдена, то ищутся все выходящие из нее дуги, помеченные отношением R3, так как в образце справа от этой дуги стоит вершина x, на месте которой в базе знаний может находиться любая вершина. Если из а не выходит ни одной дуги, помеченной отношением R3, то поиск заканчивается неудачей. Но если такие дуги есть, то происходит переход во все вершины, с которыми вершину а связывает отношение R3, т.е. возникает параллельный процесс поиска. В примере произойдет переход от вершины а к вершинам b и f, из которых начинается поиск выходящих из них дуг, помеченные отношением R1, ведущих в любую вершину, так как в образце далее стоит вершина, которой соответствует свободная переменная y. Далее процесс продолжается аналогичным образом. В примере поиск оказывается успешным. После нахождения А в семантической сети происходит замена, которая определяется правой частью образца. В результате возникает трансформированная сеть (рис. 2в).
Продукция АДЮВЗ может соответствовать процедуре нахождения закономерностей по эмпирическим данным. Логический блок на основании просмотра и анализа данных выдвигает гипотезы и наличии закономерностей и, убедившись в их приемлемости и достаточной обоснованности, записывает их в базу знаний. Аналогично можно интерпретировать и иные типы продукций из таблицы 1.
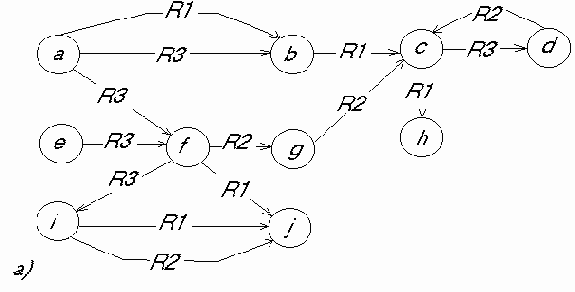
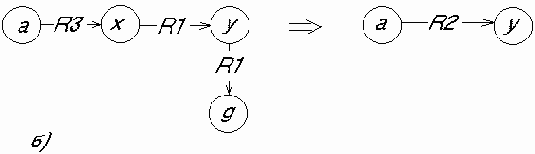
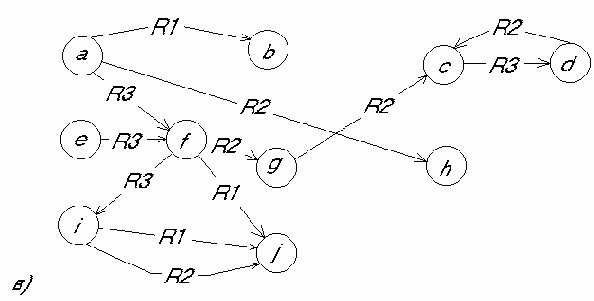
Структура экспертных систем
Типичная статическая ЭС состоит из следующих основных компонентов (рис. 1.): решателя (интерпретатора); рабочей памяти (РП), называемой также базой данных (БД); базы знаний (БЗ); компонентов приобретения знаний; объяснительного компонента; диалогового компонента.
База данных (рабочая память) предназначена для хранения исходных и промежуточных данных решаемой в текущий момент задачи. Этот термин совпадает по названию, но не по смыслу с термином, используемым в информационно-поисковых системах (ИПС) и системах управления базами данных (СУБД) для обозначения всех данных (в первую очередь долгосрочных), хранимых в системе.
База знаний (БЗ) в ЭС предназначена для хранения долгосрочных данных, описывающих рассматриваемую область (а не текущих данных), и правил, описывающих целесообразные преобразования данных этой области.
Решатель, используя исходные данные из рабочей памяти и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к исходным данным, приводят к решению задачи.
Компонент приобретения знаний автоматизирует процесс наполнения ЭС знаниями, осуществляемый пользователем-экспертом.
Объяснительный компонент объясняет, как система получила решение задачи (или почему она не получила решение) и какие знания она при этом использовала, что облегчает эксперту тестирование системы и повышает доверие пользователя к полученному результату.
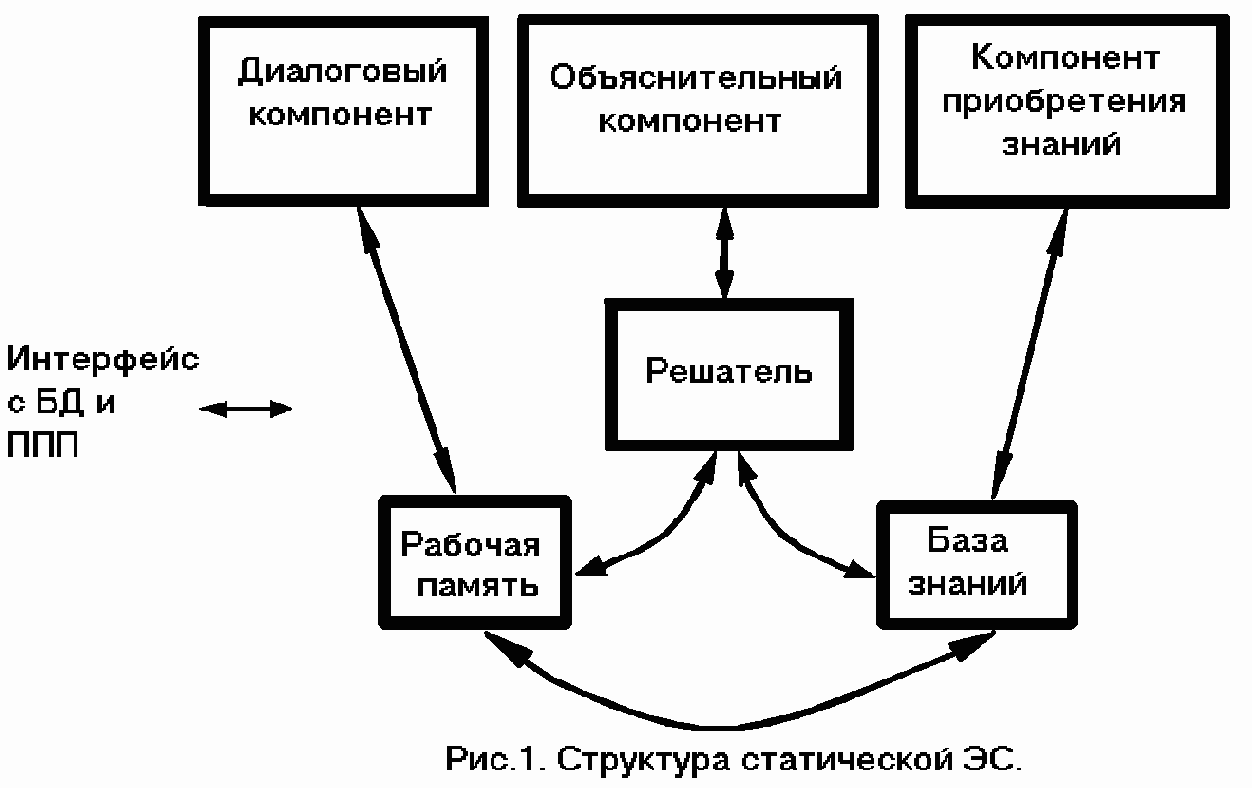
Диалоговый компонент ориентирован на организацию дружественного общения с пользователем как в ходе решения задач, так и в процессе приобретения знаний и объяснения результатов работы.
В разработке ЭС участвуют представители следующих специальностей:
эксперт в проблемной области, задачи которой будет решать ЭС;
инженер по знаниям - специалист по разработке ЭС (используемые им технологию, методы называют технологией (методами) инженерии знаний);
программист по разработке инструментальных средств (ИС), предназначенных для ускорения разработки ЭС.
Необходимо отметить, что отсутствие среди участников разработки инженеров по знаниям (т.
е. их замена программистами) либо приводит к неудаче процесс создания ЭС, либо значительно удлиняет его.
Эксперт определяет знания (данные и правила), характеризующие проблемную область, обеспечивает полноту и правильность введенных в ЭС знаний.
Инженер по знаниям помогает эксперту выявить и структурировать знания, необходимые для работы ЭС; осуществляет выбор того ИС, которое наиболее подходит для данной проблемной области, и определяет способ представления знаний в этом ИС; выделяет и программирует (традиционными средствами) стандартные функции (типичные для данной проблемной области), которые будут использоваться в правилах, вводимых экспертом.
Программист разрабатывает ИС (если ИС разрабатывается заново), содержащее в пределе все основные компоненты ЭС, и осуществляет его сопряжение с той средой, в которой оно будет использовано.
Экспертная система работает в двух режимах: режиме приобретения знаний и в режиме решения задачи (называемом также режимом консультации или режимом использования ЭС).
В режиме приобретения знаний общение с ЭС осуществляет (через посредничество инженера по знаниям) эксперт. В этом режиме эксперт, используя компонент приобретения знаний, наполняет систему знаниями, которые позволяют ЭС в режиме решения самостоятельно (без эксперта) решать задачи из проблемной области. Эксперт описывает проблемную область в виде совокупности данных и правил. Данные определяют объекты, их характеристики и значения, существующие в области экспертизы. Правила определяют способы манипулирования с данными, характерные для рассматриваемой области.
Отметим, что режиму приобретения знаний в традиционном подходе к разработке программ соответствуют этапы алгоритмизации, программирования и отладки, выполняемые программистом. Таким образом, в отличие от традиционного подхода в случае ЭС разработку программ осуществляет не программист, а эксперт (с помощью ЭС), не владеющий программированием.
В режиме консультации общение с ЭС осуществляет конечный пользователь, которого интересует результат и (или) способ его получения.
Необходимо отметить, что в зависимости от назначения ЭС пользователь может не быть специалистом в данной проблемной области (в этом случае он обращается к ЭС за результатом, не умея получить его сам), или быть специалистом (в этом случае пользователь может сам получить результат, но он обращается к ЭС с целью либо ускорить процесс получения результата, либо возложить на ЭС рутинную работу). В режиме консультации данные о задаче пользователя после обработки их диалоговым компонентом поступают в рабочую память. Решатель на основе входных данных из рабочей памяти, общих данных о проблемной области и правил из БЗ формирует решение задачи. ЭС при решении задачи не только исполняет предписанную последовательность операции, но и предварительно формирует ее. Если реакция системы не понятна пользователю, то он может потребовать объяснения:
"Почему система задает тот или иной вопрос?", "как ответ, собираемый системой, получен?".
Структуру, приведенную на рис. 1.1, называют структурой статической ЭС. ЭС данного типа используются в тех приложениях, где можно не учитывать изменения окружающего мира, происходящие за время решения задачи. Первые ЭС, получившие практическое использование, были статическими.
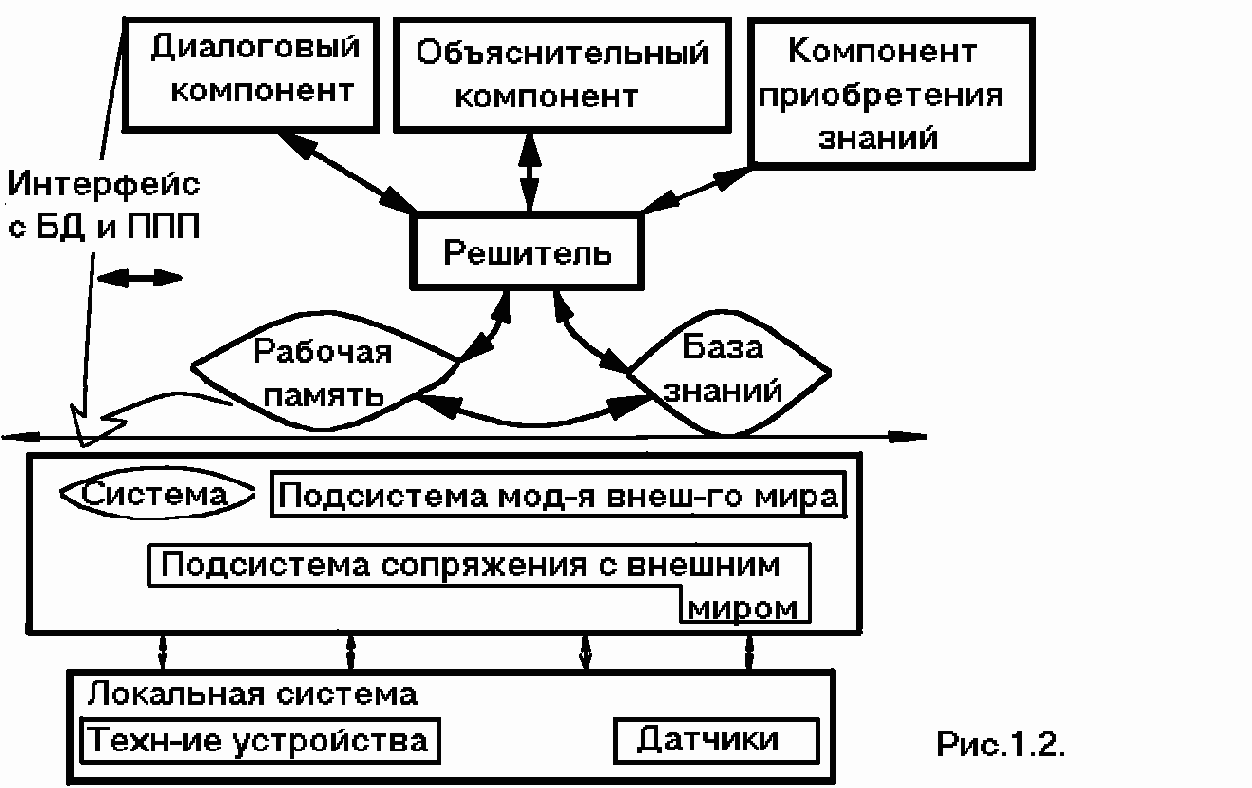
На рис. 1.2 показано, что в архитектуру динамической ЭС по сравнению со статической ЭС вводятся два компонента: подсистема моделирования внешнего мира и подсистема связи с внешним окружением. Последняя осуществляет связи с внешним миром через систему датчиков и контроллеров. Кроме того, традиционные компоненты статической ЭС (база знаний и машина вывода) претерпевают существенные изменения, чтобы отразить временную логику происходящих в реальном мире событий.
Подчеркнем, что структура ЭС, представленная на рис. 1.1 и 1.2, отражает только компоненты (функции), и многое остается "за кадром". На рис. 1.3 приведена обобщенная структура современного ИС для создания динамических ЭС, содержащая кроме основных компонентов те возможности, которые позволяют создавать интегрированные приложение в соответствии с современной технологией программирования.
Структурно-пятенный эталон
Фонтанное преобразование совмещает в себе достоинства шаблонной и структурной систем и, по нашему мнению, позволяет избежать недостатков, присущих каждой из них по отдельности. В основе этой технологии лежит использование структурно-пятенного эталона. Он позволяет представить изображения в виде набора пятен, связанных между собой n-арными отношениями, задающими структуру символа. Эти отношения (то есть расположение пятен друг относительно друга) образуют структурные элементы, составляющие символ. Так, например, отрезок - это один тип n-арных отношений между пятнами, эллипс - другой, дуга - третий. Другие отношения задают пространственное расположение образующих символ элементов.
В эталоне задаются: имя; обязательные, запрещающие и необязательные структурные элементы; отношения между структурными элементами; отношения, связывающие структурные элементы с описывающим прямоугольником символа; атрибуты, используемые для выделения структурных элементов; атрибуты, используемые для проверки отношений между элементами; атрибуты, используемые для оценки качества элементов и отношений; позиция, с которой начинается выделение элемента (отношения локализации элементов).
Структурные элементы, выделяемые для класса изображений, могут быть исходными и составными. Исходные структурные элементы - это пятна, составные - отрезок, дуга, кольцо, точка. В качестве составных структурных элементов, в принципе, могут быть взяты любые объекты, описанные в эталоне. Кроме того, они могут быть описаны как через исходные, так и через другие составные структурные элементы.
Например, для распознавания корейских иероглифов (слоговое письмо) составными элементами для описания слога являются описания отдельных букв (но не отдельные элементы букв). В итоге, использование составных структурных элементов позволяет строить иерархические описания классов распознаваемых объектов.
В качестве отношений используются связи между структурными элементами, которые определяются либо метрическими характеристиками этих элементов (например, ), либо их взаимным расположением на изображении (например, ,).
При задании структурных элементов и отношений используются конкретизирующие параметры, позволяющие доопределить структурный элемент или отношение при использовании этого элемента в эталоне конкретного класса.
Для структурных элементов конкретизирующими могут являться, например, параметры, задающие диапазон допустимой ориентации отрезка, а для отношений - параметры, задающие предельное допустимое расстояние между характерными точками структурных элементов в отношении .
Конкретизирующие параметры используются также для вычисления конкретного структурного элемента изображения и выполнения данного отношения.
Построение и тестирование структурно-пятенных эталонов для классов распознаваемых объектов - процесс сложный и трудоемкий. База изображений, которая используется для отладки описаний, должна содержать примеры хороших и плохих (предельно допустимых) изображений для каждой графемы, а изображения базы разделяются на обучающее и контрольное множества.
Разработчик описания предварительно задает набор структурных элементов (разбиение на пятна) и отношения между ними. Система обучения по базе изображений автоматически вычисляет параметры элементов и отношений. Полученный эталон проверяется и корректируется по контрольной выборке изображений данной графемы. По контрольной же выборке проверяется результат распознавания, то есть оценивается качество подтверждения гипотез.
Распознавание с использованием структурно-пятенного эталона происходит следующим образом. Эталон накладывается на изображение, и отношения между выделенными на изображении пятнами сравниваются с отношениями пятен в эталоне. Если выделенные на изображении пятна и отношения между ними удовлетворяют эталону некоторого символа, то данный символ добавляется в список гипотез о результате распознавания входного изображения.
Структурные системы
В таких системах объект описывается как граф, узлами которого являются элементы входного объекта, а дугами - пространственные отношения между ними . Система реализующие подобный подход, обычно работают с векторными изображениями. Структурными элементами являются составляющие символ линии. Так, для буквы "р" - это вертикальный отрезок и дуга.
К недостаткам структурных систем следует отнести их высокую чувствительность к дефектам изображения, нарушающим составляющие элементы. Также векторизация может добавить дополнительные дефекты. Кроме того, для этих систем, в отличие от шаблонных и признаковых, до сих пор не созданы эффективные автоматизированные процедуры обучения. Поэтому для Fine Reader структурные описания пришлось создать в ручную.
Сущности и иерархия классов
Класс, базовое понятие объектно-ориентированной технологии, - основа представления знаний в G2. Данный подход составляет основную тенденцию в программировании вообще, поскольку он уменьшает избыточность и упрощает определение классов (определяется не весь класс, а только его отличия от суперкласса), позволяет использовать общие правила, процедуры, формулы, уменьшает их число, да и является естественным для человека способом описания сущностей. При таком подходе структуры данных представляются в виде классов объектов (или определений объектов), имеющих определенные атрибуты. Классы наследуют атрибуты от суперклассов и передают свои атрибуты подклассам. Каждый класс (исключая корневой) может иметь конкретные экземпляры класса.
Все, что хранится в базе знаний и с чем оперирует система, является экземпляром того или иного класса. Более того, все синтаксические конструкции G2 являются классами. Для сохранения общности даже базовые типы данных - символьные, числовые, булевы и истинностные значения нечеткой логики - представлены соответствующими классами. Описание класса включает ссылку на суперкласс и содержит перечень атрибутов, специфичных для класса.
Бр3ЮИерархия модулей и рабочих пространствДля структуризации G2-приложений используются "модули" и "рабочие пространства". Несмотря на то, что функции этих конструкций схожи, между ними есть существенные различия.
Приложение может быть организовано в виде одной или нескольких баз знаний, называемых модулями. В последнем случае говорят, что приложение представлено структурой (иерархией) модулей. На верхнем уровне - один модуль верхнего уровня. Модули следующего уровня состоят из тех модулей, без которых не может работать модуль предыдущего уровня. Структурирование приложений позволяет разрабатывать приложение одновременно нескольким группам разработчиков, упрощает разработку, отладку и тестирование, позволяет изменять модули независимо друг от друга, упрощает повторное использование знаний.
Рабочие пространства являются контейнерным классом, в котором размещаются другие классы и их экземпляры, например, объекты, связи, правила, процедуры и т.д.
Каждый модуль ( база знаний) может содержать любое число рабочих пространств. Рабочие пространства образуют одну или несколько древовидных иерархий с отношением "is-а-part-of" ("является частью"). С каждым модулем ассоциируется одно или несколько рабочих пространств верхнего (нулевого) уровня; каждое из них - корень соответствующей иерархии. В свою очередь, с каждым объектом (определением объекта или связи), расположенным в нулевом уровне, может ассоциироваться рабочее пространство первого уровня, "являющееся его частью" и т.д.
Различие между "модулями" и "рабочими пространствами" состоит в следующем. Модули разделяют приложение на отдельные базы знаний, совместно используемые в различных приложениях. Они полезны в процессе разработки приложения, а не его исполнения. Рабочие пространства, наоборот, выполняют свою роль при исполнении приложения. Они содержат в себе различные сущности и обеспечивают разбиение приложения на небольшие части, которые легче понять и обрабатывать.
Рабочие пространства можно устанавливать (вручную или действием в правиле/процедуре) в активное или неактивное состояние (при этом сущности, находящиеся в этом пространстве и в его подпространствах, становятся невидимыми для механизма вывода). Данный механизм используется, например, при наличии альтернативных групп правил, когда активной должна быть только одна из них.
Кроме того, рабочие пространства используются для определения пользовательских ограничений, определяющих разное поведение приложения для различных категорий пользователей.
Бр3ЮСтруктуры данных
Сущности в базе знаний с точки зрения их использования можно разделить на структуры данных и выполняемые утверждения. Примерами первых являются объекты и их классы, связи (connection), отношения (relation), переменные, параметры, списки, массивы, рабочие пространства. Примерами вторых - правила, процедуры, формулы, функции.
Выделяют объекты (и классы), встроенные в систему и вводимые пользователем.При разработке приложения, как правило, создаются подклассы, отражающие специфику данного приложения. Среди встроенных подклассов объектов наибольший интерес представляет подкласс данных, включающий подклассы переменных, параметров, списков и массивов.
Особая роль отводится переменным. В отличие от статических систем переменные делятся на три вида: собственно переменные, параметры и простые атрибуты. Параметры получают значения в результате работы машины вывода или выполнения какой-либо процедуры. Переменные представляют измеряемые характеристики объектов реального мира и поэтому имеют специфические черты: время жизни значения и источник данных. Время жизни значения переменной определяет промежуток времени, в течение которого это значение актуально, по истечении этого промежутка переменная считается не имеющей значения.
Тестирование логики приложения и ограничений (по времени и памяти)
Блок динамического моделирования позволяет при тестировании воссоздать различные ситуации, адекватные внешнему миру. Таким образом, логика приложения будет проверяться в тех условиях, для которых она создавалась. Конечный пользователь может принять непосредственное участие в тестировании благодаря управлению цветом (т.е. изменение цвета при наступлении заданного состояния или выполнения условия) и анимации (т.е. перемещение/вращение сущности при наступлении состояния/условия). Благодаря этому он сможет понять и оценить логику работы приложения, не анализируя правила и процедуры, а рассматривая графическое изображение управляемого процесса, технического сооружения и т.п.
Для проверки выполнения ограничений используется возможность "Meters", вычисляющая статистику по производительности и используемой памяти.
Полученное приложение полностью переносимо на различные платформы в среду UNIX (SUN, DEC, HP, IBM и т.д.), VMS (DEC VAX) и Windows NT (Intel, DEC Alpha). База знаний сохраняется в обычном ASCII-файле, который однозначно интерпретируется на любой из поддерживаемых платформ. Перенос приложения не требует его перекомпиляции и заключается в простом перемещении файлов. Функциональные возможности и внешний вид приложения не претерпевают при этом никаких изменений. Приложение может работать как в "полной" (т.е. предназначенной для разработки) среде, так и под runtime, которая не позволяет модифицировать базу знаний.
Тестирование приложения на наличие ошибок
В G2 ошибки в синтаксисе показываются непосредственно при вводе конструкций (структур данных и исполняемых утверждений) в базу данных; эти конструкции анализируются инкрементно. Могут быть введены только конструкции, не содержащие синтаксических ошибок. Таким образом, отпадает целая фаза отладки приложения (свойственная традиционному программированию), что ускоряет разработку приложений.
Разработчик освобожден и от необходимости знать детальный синтаксис языка G2, так как при вводе в базу знаний некоторой конструкции ему в виде подсказки сообщается перечень всех возможных синтаксически правильных продолжений.
Для выявления ошибок и неопределенностей реализована возможность "Inspect", позволяющая просматривать различные аспекты базы знаний, например, "показать все утверждения со ссылками на неопределенные сущности (объекты, связи, атрибуты)", "показать графически иерархию заданного класса объектов", "показать все сущности, у которых значение атрибута Notes не ОК". (Данный атрибут есть у всех сущностей, представимых в языке G2; его значение - либо ОК, когда нет претензий к сущности, либо описание реальных или потенциальных проблем, например, ссылка на несуществующий объект, несколько объектов с одним именем и т.п.)
Уроки машинного чтения от Cognitive Technologies
Работает система по принципу . Это означает, что при нажатии кнопки запускается весь процесс обработки документа: сканирование, фрагментация страницы на текстовые и графические блоки, распознавание текста, проверка орфографии и формирование выходного файла. Но что за всем этим стоит? Интеллектуальный алгоритм позволяет автоматически подобрать оптимальный уровень яркости сканера (адаптивное сканирование) в зависимости от фона документа, сохранить иллюстрации (или, в зависимости от решаемой задачи, удалить ненужные графические элементы для максимального сокращения последующего редактирования).
В CuneiForm используется несколько методов подобного сопоставления. Во-первых, образ каждого символа раскладывается на отдельные элементы - события. К примеру, событием является фрагмент от одной линии пересечения до другой. Совокупность событий представляет собой компактное описание символа.
Другие методы основаны на соотношении отдельных элементов символов и описании их характерных признаков(закругления, прямые, углы и т. д.). По каждому из этих описаний существуют базы данных, в которых находятся соответствующие эталоны. Поступающий на обработку элемент изображения сравнивается с эталоном. А затем на основании этого сравнения решающая функция выносит вердикт о соответствии изображения конкретному символу. Кроме того, существуют алгоритмы, которые позволяют работать с текстами низкого качества. Так, для разрезания символов существует метод оценки оптимальных разбиений. И наоборот, для соединения "рассыпаных" элементов разработан механизм их соединения.
В CuneiForm'96 мы впервые применили алгоритмы самообучения (или адаптивного распознавания). Принцип их работы состоит в следующем. В каждом тексте присутствуют четко и нечетко пропечатанные символы. Если после того как система распознала текст (как это делает обычная система, например предыдущая версия OCR CuneiForm 2.95), выясняется, что точность оказалась ниже пороговой, производится дораспознавание текста на основе шрифта, который генерируется системой по хорошо пропечатанным символам.
Здесь разработчики соединили достоинства двух типов систем распознавания: омнии мультишрифтовые. Напомним, что первые позволяют распознавать любые шрифты без дополнительного обучения, вторые же более устойчивы при распознавании низкокачественных текстов. Результаты применения Cunei-Form'96 показали, что использование самообучающихся алгоритмов позволяет поднять точность распознавания низкокачественных текстов в четыре-пять раз! Но главное, пожалуй, в том, что самообучающиеся системы обладают гораздо большим потенциалом повышения точности распознавания.
Важную роль играют методы словарного и синтаксического распознавания и, по сути, служат мощным средством поддержки геометрического распознавания. Но для их эффективного использования необходимо было решить две важные задачи. Во-первых, реализовать быстрый доступ к большому (порядка 100000 слов) словарю. В результате удалось построить систему хранения слов, где на хранение каждого слова уходило не более одного байта, а доступ осуществлялся за минимальное время. С другой стороны, потребовалось построить систему коррекции результатов распознавания, ориентированную на альтернативность событий (подобно системе проверки орфографии). Сама по себе альтернативность результатов распознавания очевидна и обусловлена хранением коллекций букв вместе с . А словарный контроль позволял изменять эти оценки, используя словарную базу. В итоге применение словаря позволило реализовать схему дораспознавания символов.
Сегодня наряду с задачами повышения точности распознавания на передний план выходят вопросы расширения сфер применения OCR-технологий, соединения технологий распознавания с архивными системами. Иными словами, мы переходим от монопрограммы, выполняющей функции ввода текста, к автоматизированным комплексам, решающим задачи клиента в области документооборота. Вот уже около полугода CuneiForm поставляется в комплекте с сервером распознавания CuneiForm OCR Server, предназначенным для коллективного ввода данных в организациях, а электронный архив , включающий модуль распознавания, за короткое время приобрел большую популярность.
С таким прицелом создавался и комплект CuneiForm'96i Professional, существенно изменивший представления о системах распознавания в целом.
Уровни представления и уровни детальности
Для того чтобы экспертная система могла управлять процессом поиска решения, была способна приобретать новые знания и объяснять свои действия, она должна уметь не только использовать свои знания, но и обладать способностью понимать и исследовать их, т.е. экспертная система должна иметь знания о том, как представлены ее знания о проблемной среде. Если знания о проблемной среде назвать знаниями нулевого уровня представления, то первый уровень представления содержит метазнания, т.е. знания о том, как представлены во внутреннем мире системы знания нулевого уровня. Первый уровень содержит знания о том, какие средства используются для представления знаний нулевого уровня. Знания первого уровня играют существенную роль при управлении процессом решения, при приобретении и объяснении действий системы. В связи с тем, что знания первого уровня не содержат ссылок на знания нулевого уровня, знания первого уровня независимы от проблемной среды.
Число уровней представления может быть больше двух. Второй Уровень представления содержит сведения о знаниях первого уровня, т.е. знания о представлении базовых понятий первого уровня. Разделение знаний по уровням представления обеспечивает расширение области применимости системы.
Выделение уровней детальности позволяет рассматривать знания с различной степенью подробности. Количество уровней детальности во многом определяется спецификой решаемых задач, объемом знаний и способом их представления. Как правило, выделяется не менее трех уровней детальности, отражающих соответственно общую, логическую и физическую организацию знаний. Введение нескольких уровней детальности обеспечивает дополнительную степень гибкости системы, так как позволяет производить изменения на одном уровне, не затрагивая другие. Изменения на одном уровне детальности могут приводить к дополнительным изменениям на этом же уровне , что оказывается необходимым для обеспечения согласованности структур данных и программ. Однако наличие различных уровней препятствует распространению изменений с одного уровня на другие.
Успехи систем искусственного интеллекта и их причины
Использование экспертных систем и нейронных сетей приносит значительный экономический эффект. Так, например: - American Express [1] сократила свои потери на 27 млн. долларов в год благодаря экспертной системе, определяющей целесообразность выдачи или отказа в кредите той или иной фирме; - DEC ежегодно экономит [1] 70 млн. долларов в год благодаря системе XCON/XSEL, которая по заказу покупателя составляет конфигурацию вычислительной системы VAX. Ее использование сократило число ошибок от 30% до 1%; - Sira сократила затраты на строительство трубопровода в Австралии на 40 млн. долларов [3] за счет управляющей трубопроводом экспертной системы, реализованной на базе описываемой ниже системы G2. Коммерческие успехи к экспертным системам и нейронным сетям пришли не сразу. На протяжении ряда лет (с 1960-х годов) успехи касались в основном исследовательских разработок, демонстрировавших пригодность систем искусственного интеллекта для практического использования. Начиная примерно с 1985 (а в массовом масштабе, вероятно, с 1988-1990 годов), в первую очередь, экспертные системы, а в последние два года и нейронные сети стали активно использоваться в реальных приложениях. Причины, приведшие системы искусственного интеллекта к коммерческому успеху, следующие: 1. Специализация. Переход от разработки инструментальных средств общего назначения к проблемно/предметно специализированным средствам [4], что обеспечивает сокращение сроков разработки приложений, увеличивает эффективность использования инструментария, упрощает и ускоряет работу эксперта, позволяет повторно использовать информационное и программное обеспечение (объекты, классы, правила, процедуры). 2. Использование языков традиционного программирования и рабочих станций. Переход от систем, основанных на языках искусственного интеллекта (Lisp, Prolog и т.п.), к языкам традиционного программирования (С, С++ и т.п.) упростил "интегрированность" и снизил требования приложений к быстродействию и емкости памяти. Использование рабочих станций вместо ПК резко увеличило круг возможных приложений методов искусственного интеллекта. 3. Интегрированность. Разработаны инструментальные средства искусственного интеллекта, легко интегрирующиеся с другими информационными технологиями и средствами (с CASE, СУБД, контроллерами, концентраторами данных и т.п.). 4. Открытость и переносимость. Разработки ведутся с соблюдением стандартов, обеспечивающих данные характеристики [5]. 5. Архитектура клиент/сервер. Разработка распределенной информационной системы в данной архитектуре позволяет снизить стоимость оборудования, используемого в приложении, децентрализовать приложения, повысить надежность и общую производительность, поскольку сокращается объем информации, пересылаемой между ЭВМ, и каждый модуль приложения выполняется на адекватном оборудовании.
Перечисленные причины могут рассматриваться как общие требования к инструментальным средствам создания систем искусственного интеллекта. Из пяти факторов, обеспечивших их успех в передовых странах, в России, пожалуй, полностью не реализованы четыре с половиной (в некоторых отечественных системах осуществлен переход к языкам традиционного программирования, однако они, как правило, ориентированы среду на MS-DOS, а не ОС UNIX или Windows NT. Кроме того, в России и СНГ в ряде направлений исследования практически не ведутся, и, следовательно, в этих направлениях (нейронные сети; гибридные системы; рассуждения, основанные на прецедентах; рассуждения, основанные на ограничениях) нельзя ожидать и появления коммерческих продуктов. Итак, в области искусственного интеллекта наибольшего коммерческого успеха достигли экспертные системы и средства для их разработки. В свою очередь, в этом направлении наибольшего успеха достигли проблемно/предметно специализированные средства. Если в 1988 году доход от них составил только 3 млн. долларов, то в 1993 году - 55 млн. долларов.
О существовании специальных систем, которые
О существовании специальных систем, которые "автоматически вводят в компьютер текст", знают даже начинающие пользователи. Со стороны все выглядит довольно просто и логично. На отсканированном изображении система находит фрагменты, в которых "узнает" буквы, а затем заменяет эти изображения настоящими буквами, или, по-другому, их машинными кодами. Так осуществляется переход от изображения текста к "настоящему" тексту, с которым можно работать в текстовом редакторе. Как этого добиться?
Компанией "Бит" была разработана специальная технология распознавания символов, которая получила название "Фонтанного преобразования" , а на ее основе - коммерческий продукт, получивший высокую оценку. Это система оптического распознавания Fine Reader. Сегодня на рынке представлена уже третья версия продукта, которая работает не только с текстом, но и с формами, таблицами, а разработчики уже колдуют над новой четвертой версией Fine Reader, которая будет распознавать не только печатный но и рукописный текст.
Процесс общения с машиной долгое время оставался уделом специалистов и был недоступен для понимания простым смертным. Тем самым "простым смертным", которые, собственно говоря, и являлись потребителями компьютерных услуг.Технологи зачастую самой ЭВМ и в глаза-то не видели, а общались с машиной через посредника-программиста". Компьютерный интерфейс на первых этапах развития вычислительной техники в качестве обязательного элемента непременно включал человека-специалиста (что касается нашей страны, то кое-где такое положение сохранялось вплоть до начала девяностых; именно поэтому у нас во многих конторах до сих пор имеют привычку называть программистом любого человека, способного различить пару клавиш на клавиатуре. Что, конечно, по большому счету потребителей не очень-то устраивало.Вот если бы можно было пообщаться с компьютером напрямую, не забивая голову всяческими техническими сведениями...
" Человек благоразумный подстраивает себя под окружающий мир, тогда как безрассудный человек упорно подстраивает этот мир под самого себя. Так что весь прогресс опирается на людей безрассудных".
Бернард Шоу.
Парадоксальное высказывание Бернарда Шоу имеет непосредственное отношение к тексту статьи. В самом деле, почему человек так стремится поработить себя машинами? На сколько велика их власть над людьми? Неужели весь прогресс человечества в том только и заключается, чтобы построить такой мир, в котором сам человек станет звеном избыточным, а потом неизбежно исчезнет?
В этой статье я хотел бы затронуть некоторые из последних научных работ в области искусственной жизни и искусственного интеллекта. Искусственный интеллект вообще и экспертные системы в частности прошли долгий и тернистый путь: первые увлечения (1960 год), лженаука (1960-65), успехи при решении головоломок и игр (1965-1975), разочарование при решении практических задач (1970-1985), первые успехи при решении ряда практических задач (1962-1992), массовое коммерческое использование при решении практических задач (1993-1995). Но основу коммерческого успеха по праву составляют экспертные системы и, в первую очередь, экспертные системы реального времени. Именно они позволили искусственному интеллекту перейти от игр и головоломок к массовому использованию при решении практически значимых задач.
Выполняемые утверждения
Основу выполняемых утверждений баз знаний составляют правила и процедуры. Кроме того, есть формулы, функции, действия и т.п. Правила в G2 имеют традиционный вид: левая часть (антецедент) и правая часть (консеквент). Кроме if-правила, используется еще четыре типа правил: initially, unconditionally, when и whenever. Каждое из типов правил может быть как общим, т.е. относящимся ко всему классу, так и специфическим, относящимся к конкретным экземплярам класса.
Возможность представлять знания в виде общих правил, а не только специализированных, позволяет минимизировать избыточность базы знаний, упрощает ее наполнение и сопровождение, сокращает число ошибок, способствует повторной используемости знаний (общие правила запоминаются в библиотеке и могут использоваться в сходных приложениях).
Несмотря на то что продукционные правила обеспечивают достаточную гибкость для описания реакций системы на изменения окружающего мира, в некоторых случаях, когда необходимо выполнить жесткую последовательность действий, например, запуск или остановку комплекса оборудования, более предпочтителен процедурный подход. Язык программирования, используемый в G2 для представления процедурных знаний, является достаточно близким родственником Паскаля. Кроме стандартных управляющих конструкций язык расширен элементами, учитывающими работу процедуры в реальном времени: ожидание наступления событий, разрешение другим задачам прерывать ее выполнение, директивы, задающие последовательное или параллельное выполнение операторов. Еще одна интересная особенность языка - итераторы, позволяющие организовать цикл над множеством экземпляров класса.
и привычным является именно диалог,
Для человека естественным и привычным является именно диалог, а не монолог. Как следствие недооценки необходимости речевого ответа появляется повышенная утомляемость операторов, монотонность речи и ограниченность применимости речевого интерфейса. Чем может помочь слепому компьютер, оснащенный распознавателем речи, если он лишен устройства обратной не визуальной связи? Широко известен факт непроизвольной подстройки голоса под голос собеседника. Почему не использовать эту способность человека для увеличения безошибочности распознавания речи компьютером за счет корректировки произношения оператора с помощью двустороннего диалога? Кроме того, вполне возможно, что правильно организованный и модулированный синтез может в значительной степени снизить риск появления у оператора заболеваний, связанных с монотонностью речи и дополнительным напряжением. Повсеместное проникновение графического пользовательского интерфейса было обеспечено за счет совместного применения графического монитора, средства вывода графической информации, и мыши- для ее ввода, а также, не в последнюю очередь, благодаря гениальным концептуальным находкам в области оконного интерфейса фирмы Xerox. Будущее речевого интерфейса в не меньшей степени зависит от умения современных разработчиков не только создать технологическую основу речевого ввода, но и гармонично слить технологические находки в единую логически завершенную систему взаимодействия "человек-компьютер". Основная работа еще впереди!!!
Рассмотренные в статье тенденции развития искусственного интеллекта позволяют утверждать, что одним из основных направлений в этой области являются экспертные системы реального времени. Рассмотрение проведено на примере оболочки экспертных систем реального времени G2, представляющей собой самодостаточную среду для разработки, внедрения и сопровождения приложений в широком диапазоне отраслей. G2 объединяет в себе как универсальные технологии построения современных информационных систем (стандарты открытых систем, архитектура клиент/сервер, объектно-ориентированное программирование, использование ОС, обеспечивающих параллельное выполнение в реальном времени многих независимых процессов), так и специализированные методы (рассуждения, основанные на правилах, рассуждения, основанные на динамических моделях, или имитационное моделирование, процедурные рассуждения, активная объектная графика, структурированный естественный язык для представления базы знаний), а также интегрирует технологии систем, основанных на знаниях с технологией традиционного программирования (с пакетами программ, с СУБД, с контроллерами и концентраторами данных и т.д.).
Все это позволяет с помощью данной оболочки создавать практически любые большие приложения значительно быстрее, чем с использованием традиционных методов программирования, и снизить трудозатраты на сопровождение готовых приложений и их перенос на другие платформы.
Жизненный цикл приложения
Жизненный цикл приложения в G2 состоит из ряда этапов.