Акустическая модель
Оба подхода имеют свои достоинства и недостатки.При разработке технических сисвыбор подхода имеет первостепенное значение.темCуществует два подхода к построенрию акустической модели:изобретательский и бионический.Первый базируется на результатах поиска механизма функционирования акустической модели.При втором подходе разработчик пытается понять и смоделировать работу естественных систем.
Аллофонная база данных
Необходимый речевой материал был записан в следующем режиме оцифровки: частота дискретизации 22 кГц с разрядностью 16 бит.
В качестве базовых элементов компиляции выбраны аллофоны, оптимальный набор которых и представляет собой акустико-фонетическую базу синтеза. Инвентарь базовых единиц компиляции включает в себя 1200 элементов, который занимает около 7 Мбайт памяти. В большинстве случаев элементы компиляции представляют собой сегменты речевой волны фонемной размерности. Для получения необходимой исходной базы единиц компиляции был составлен специальный словарь,который содержит слова и словосочетания с аллофонами во всех учитываемых контекстах. В нем содержится 1130 словоупотреблений.
Архитектура экспертной системы реального времени
Специфические требования, предъявляемые к экспертной системе реального времени, приводят к тому, что их архитектура отличается от архитектуры статических систем. Не вдаваясь в детали, отметим появление двух новых подсистем - моделирования внешнего окружения и сопряжения с внешним миром (датчиками, контроллерами, СУБД и т.п.) - и значительные изменения, которым подвергаются оставшиеся подсистемы.
Для того, чтобы понять, что представляет из себя среда для создания экспертных систем реального времени, опишем ниже жизненный цикл такой системы, а также ее основные компоненты. Описание оболочки экспертной системы реального времени приведем на примере средства G2, поскольку в нем полностью реализованы возможности, которые считаются необходимыми и уместными в подобных программных продуктах.
Базы знаний
Все знания в G2 хранятся в двух типах файлов: базы знаний и библиотеки знаний. В файлах первого типа хранятся знания о приложениях: определения всех объектов, объекты, правила, процедуры и т.п. В файлах библиотек хранятся общие знания, которые могут быть использованы более, чем в одном приложении, например, определение стандартных объектов. Файлы баз знаний могут преобразоваться в библиотеки знаний и обратно.
В целях обеспечения повторной используемости приложений реализовано средство, позволяющее объединять с текущим приложением ранее созданные базы и библиотеки знаний. При этом конфликты в объединяемых знаниях выявляются и отображаются на дисплее.
Знания структурируются: предусмотрены иерархия классов, иерархия модулей, иерархия рабочих пространств. Каждую из них можно показать на дисплее.
Cинтезатор русской речи
В качестве примера рассмотрим разработку "Говорящая мышь" клуба голосовых технологий научного парка МГУ. (Известно, что в некоторых российских организациях и компаниях ведутся аналогичные разработки, однако подробных сведений в печати обнаружить не удалось.
В основе речевого синтеза лежит идея совмещения методов конкатенации и синтеза по правилам. Метод конкатенации при адекватном наборе базовых элементов компиляции обеспечивает качественное воспроизведение спектральных характеристик речевого сигнала, а набор правил - возможность формирования естественного интонационно-просодического оформления высказываний. Существуют и другие методы синтеза, может быть, в перспективе более гибкие, но дающие пока менее естественное озвучивание текста. Это, прежде всего, параметрический (формантный) синтез речи по правилам или на основе компиляции, развиваемый для ряда языков зарубежными исследователями. Однако для реализации этого метода необходимы статистически представительные акустико-фонетические базы данных и соответствующая компьютерная технология, которые пока доступны не всем.
Cистема распознавания речи
Система распознавания речи состоит из двух частей.Эти части могут быть выделены в блоки или в подпрограммы.Для простоты скажем, что система распознавания речи состоит из акустической и лингвистической частей.Лингвистическая часть может включать в себя фонетическую, фонологическую, морфологическую, синтаксическую и семантическую модель языка.
Акустическая модель отвечает за представление речевого сигнала.Лингвистическая модель интерпретирует информацию,получаемую от акустической модели, и отвечает за представление результата распознавания потребителю.
Данные и знания. Основные определения.
Информация, с которой имеют дело ЭВМ, разделяется на процедурную и декларативную. Процедурная информация овеществлена в программах, которые выполняются в процессе решения задач, декларативная информация - в данных, с которыми эти программы работают. Стандартной формой представления информации в ЭВМ является машинное слово, состоящее из определенного для данного типа ЭВМ числа двоичных разрядов - битов. Машинное слово для представления данных и машинное слово для представления команд, образующих программу, могут иметь одинаковое или разное число разрядов. В последнее время для представления данных и команд используются одинаковые по числу разрядов машинные слова. Однако в ряде случаев машинные слова разбиваются на группы по восемь двоичных разрядов, которые называются байтами.
Одинаковое число разрядов в машинных словах для команд и данных позволяет рассматривать их в ЭВМ в качестве одинаковых информационных единиц и выполнять операции над командами, как над данными. Содержимое памяти образует информационную базу.
В большинстве существующих ЭВМ возможно извлечение информации из любого подмножества разрядов машинного слова вплоть до одного бита. Во многих ЭВМ можно соединять два или более машинного слова в слово с большей длиной. Однако машинное слово является основной характеристикой информационной базы, т.к. его длина такова, что каждое машинное слово хранится в одной стандартной ячейке памяти, снабженной индивидуальным именем - адресом ячейки. По этому имени происходит извлечение информационных единиц из памяти ЭВМ и записи их в нее.
Параллельно с развитием структуры ЭВМ происходило развитие информационных структур для представления данных. Появились способы описания данных в виде векторов и матриц, возникли списочные структуры, иерархические структуры. В настоящее время в языках программирования высокого уровня используются абстрактные типы данных, структура которых задается программистом. Появление баз данных (БД) знаменовало собой еще один шаг на пути организации работы с декларативной информацией.
При формализации качественных знаний может быть использована теория нечетких множеств [Заде, 1974], особенно те ее аспекты, которые связаны с лингенетической неопределенностью, наиболее часто возникающей при работе с экспертами на естественном языке. Под лингвистической неопределенностью подразумевается не полиморфизм слов естественного языка, который может быть преодолен на уровне понимания смысла высказываний в рамках байесовской модели [Налимов, 1974], а качественные оценки естественного языка для длины, времени, интенсивности, для целей логического вывода, принятия решений, планирования. Лингвистическая неопределенность в системах представления знаний задается с помощью лингвистических моделей основанных на теории лингвистических переменных и теории приближенных рассуждении [Kikerf 1978]. Эти теории опираются на понятие нечеткого множества, систему операций над нечеткими множествами и методы построения функций принадлежности. Одним из основных понятий, используемых в лингвистических моделях, является понятие лингвистической переменной. Значениями лингвистических переменных являются не числа, а слова или предложения некоторого искусственного либо естественного языка. Например, числовая переменная "возраст" принимает дискретные значения между нулем и сотней, а целое число является значением переменной. Лингвистическая переменная "возраст" может принимать значения: молодой, старый, довольно старый, очень молодой и т. д. Эти термы-лингвистические значения переменной. На это множество (как и на числа) также налагаются ограничения. Множество допустимых значений лингвистической переменной называется терм-множеством. При вводе в ЭВМ информации о лингвистических переменных и терм-множестве ее необходимо представить в форме, пригодной для работы на ЭВМ. Лингвистическая переменная задается набором из пяти компонентов: <Л, Т(А), U, <7, Af>, где Л-имя лингвистической переменной; Г (Л)-ее терм-множество; U- область, на которой определены значения лингвистической переменной; 6 описывает операции по порождению производных значений лингвистической переменной на основе тех значений, которые входят в терм-множество.
Система ИИ в определенном смысле моделирует интеллектуальную деятельность человека и, в частности, - логику его рассуждений. В грубо упрощенной форме наши логические построения при этом сводятся к следующей схеме: из одной или нескольких посылок (которые считаются истинными) следует сделать "логически верное" заключение (вывод, следствие). Очевидно, для этого необходимо, чтобы и посылки, и заключение были представлены на понятном языке, адекватно отражающем предметную область, в которой проводится вывод. В обычной жизни это наш естественный язык общения, в математике, например, это язык определенных формул и т.п. Наличие же языка предполагает, во - первых, наличие алфавита (словаря), отображающего в символьной форме весь набор базовых понятий (элементов), с которыми придется иметь дело и, во - вторых, набор синтаксических правил, на основе которых, пользуясь алфавитом, можно построить определенные выражения. Логические выражения, построенные в данном языке, могут быть истинными или ложными. Некоторые из этих выражений, являющиеся всегда истинными. Объявляются аксиомами (или постулатами). Они составляют ту базовую систему посылок, исходя из которой и пользуясь определенными правилами вывода, можно получить заключения в виде новых выражений, также являющихся истинными. Если перечисленные условия выполняются, то говорят, что система удовлетворяет требованиям формальной теории. Ее так и называют формальной системой (ФС). Система, построенная на основе формальной теории, называется также аксиоматической системой. Формальная теория должна, таким образом, удовлетворять следующему определению: всякая формальная теория F = (A, V, W, R), определяющая некоторую аксиоматическую систему, характеризуется: наличием алфавита (словаря), A, множеством синтаксических правил, V, множеством аксиом, лежащих в основе теории, W, множеством правил вывода, R. Исчисление высказываний (ИВ) и исчисление предикатов (ИП) являются классическими примерами аксиоматических систем.
В базах данных могут одновременно храниться большие объемы информации, а специальные средства, образующие систему управления базами данных (СУБД), позволяют эффективно манипулировать с данными, при необходимости извлекать их из базы данных и записывать их в нужном порядке в базу.
По мере развития исследований в области ИС возникла концепция знаний, которые объединили в себе многие черты процедурной и декларативной информации.
В ЭВМ знания так же, как и данные, отображаются в знаковой форме - в виде формул, текста, файлов, информационных массивов и т.п. Поэтому можно сказать, что знания - это особым образом организованные данные. Но это было бы слишком узкое понимание. А между тем, в системах ИИ знания являются основным объектом формирования, обработки и исследования. База знаний, наравне с базой данных, - необходимая составляющая программного комплекса ИИ. Машины, реализующие алгоритмы ИИ, называются машинами, основанными на знаниях, а подраздел теории ИИ, связанный с построением экспертных систем, - инженерией знаний.
Формализация качественных знаний
С помощью правил из О можно расширить число значений лингвистической переменной, т. е. расширить ее терм-множество. Каждому значению а лингвистической переменной Л соответствует нечеткое множество Ха, являющееся подмножеством V. По аналогии с формальными системами правила из G часто называют синтаксическими Наконец, компонент М образует набор семантических правил. С их помощью происходит отображение значений лингвистической переменной а в нечеткие множества Ха и выполняются обратные преобразования. Именно эти правила обеспечивают формализацию качественных утверждений экспертов при формировании проблемной области в памяти ИС.
На рис. 2Л показаны все компоненты, определяющие лингвистическую переменную <возраста>. В качестве терм-множества использовано множество, состоящее из трех значений: очень молодой (Ом), пожилой (п) и старый (с), задаваемых функциями принадлежности на области V, которую называют носителем лингвистических значений. В примере область V-года жизни от 0 до 150 лет, В качестве семантических правил выступают отображения, задаваемые функциями принадлежности 0<Цд(")<1 к нечетким множествам Лои" Хи, Хе. Как видно из рис. 2Л. человек, возраст которого равен 60 годам, принадлежит

к Хоы со значением 0 (т. в, человек в 60 лет не является очень молодым), к Ха со значением 0.8 и к Хс со значением 0.4.
Для перехода от качественных описаний к формализованным необходимо построить отображения, входящие в М, т. е. построить функции принадлежности, В таком виде подобная задача была исследована в [Блишун, 1987]
При получении от экспертов информации о виде функций принадлежности необходимо учитывать характер измерений (первичные и производные измерения) и тип шкалы, на которую проецируются измерения и на которой будут определяться функции принадлежности [Глотов и др.. 1976]. На этой шкале задается вид допустимых операторов и операций, т. е. некоторая алгебра для функций принадлежности. Кроме того, следует различать характеристики, которые можно измерять непосредственно и характеристики, которые являются качественными и требуют попарного сравнения объектов, обладающих этими характеристиками" чтобы определить их отношение к исследуемому понятию.
Можно выделить две группы методов построения функций принадлежности: прямые и косвенные. В прямых методах эксперт непосредственно задает правила определения значений функции принадлежности lia(u). Эти значения согласуются с его предпочтениями на множестве объектов следующим образом: для любых Ki, и 2 s U имеет место Ио(УО<Ио(и2) тогда и только тогда, когда йд предпочтительнее и\, т. е, в большей степени определяется понятием а; для любых уь u^eU имеет место Ца(1)=Ца(2) тогда и только тогда, когда Нч и и не различаются по отношению к понятию а. К прямым методам относится непосредственное задание функции принадлежности таблицей, формулой или примером [Zadeh, 1975; Ragade et aL, 1977; Thoie et a.. 1979].
В косвенных методах значения функции принадлежности выбираются таким образом, чтобы удовлетворялись заранее сформулированные условия. Экспертная информация является только исходной для дальнейшей обработки. Дополнительные условия могут налагаться как на вид получаемой информации, так и на процедуру обработки. Примерами дополнительных условий могут служить следующие: функция принадлежности должна отражать близость к заранее выделенному эталону, объекты множества являются точками в параметрическом пространстве [Scala, 1978]; результатом процедуры обработки должна быть функция принадлежности, удовлетворяющая условиям интервальной шкалы [Жуковин и др.. 1983]; при попарном сравнении объектов, если один объект оценивается в k раз сильнее, чем другой то второй объект оценивается в \/k раз сильнее, чем первый объект [Saaty, 1974]. и т. д.
Как правило, прямые методы используются для описания понятий, которые характеризуются измеримыми признаками (высотой, ростом, массой, объемом).
В этом случае удобно непосредственное задание функции принадлежности. К прямым методам можно отнести методы, основанные на вероятностной трактовке функций принадлежности: а(и)==Р(а/и), т, е. вероятность того, что объект ueU будет принадлежать к множеству, которое характеризует понятием Так как люди часто искажают оценки, например сдвигают их в направлении концов оценочной шкалы [Thole et al., 1979].то прямые измерения, основанные на непосредственном определении значений функции принадлежности, могут быть использованы только в том случае, когда такие искажения незначительны или маловероятны. Косвенные методы более трудоемки, чем прямые, но обладают стойкостью к искажениям в ответе. Результатом применения косвенных методов является интервальная шкала. В [Thole et al.. 1979] выдвигается для косвенных методов "условие безоговорочного экстремума": при определении степени принадлежности множество исследуемых объектов должно содержать по крайней мере два объекта, численные представления которых на интервале [0. 1] - О и 1 соответственно.
Функции принадлежности могут отражать мнение как некоторой группы экспертов, так и одного уникального эксперта. Комбинируя возможные дэа метода построения функций принадлежности с двумя типами экспертов (коллек-тивным и уникальным), можно получить четыре типа экспертизы [Блишун, 1988]
Формальные модели представления знаний.
Эти ФС хорошо исследованы и имеют прекрасно разработанные модели логического вывода - главной метапроцедуры в интеллектуальных системах. Поэтому все, что может и гарантирует каждая из этих систем, гарантируется и для прикладных ФС как моделей конкретных предметных областей. В частности, это гарантии непротиворечивости вывода, алгоритмической разрешимости (для исчисления высказываний) и полуразрешимости (для исчислений предикатов первого порядка).
ФС имеют и недостатки, которые заставляют искать иные формы представления. Главный недостаток - это "закрытость" ФС, их негибкость. Модификация и расширение здесь всегда связаны с перестройкой всей ФС, что для практических систем сложно и трудоемко. В них очень сложно учитывать происходящие изменения. Поэтому ФС как модели представления знаний используются в тех предметных областях, которые хорошо локализуются и мало зависят от внешних факторов.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Формирование просодических характеристик
К просодическим характеристикам высказывания относятся его тональные, акцентные и ритмические характеристики. Их физическими аналогами являются частота основного тона, энергия и длительность. В речи просодические характеристики высказывания определяются не только составляющими его словами, но также тем, какое значение оно несет и для какого слушателя предназначено, эмоциональным и физическим состоянием говорящего и многими другими факторами. Многие из этих факторов сохраняют свою значимость и при чтении вслух, поскольку человек обычно интерпретирует и воспринимает текст в процессе чтения. Таким образом, от системы синтеза следует ожидать примерно того же, то есть, что она сможет понимать имеющийся у нее на входе текст, используя методы искусственного интеллекта. Однако этот уровень развития компьютерной технологии еще не достигнут, и большинство современных систем автоматического синтеза стараются корректно синтезировать речь с эмоционально нейтральной интонацией. Между тем, даже эта задача на сегодняшний день представляется очень сложной.
Формирование просодических характеристик, необходимых для озвучивания текста, осуществляется тремя основными блоками, а именно: блоком расстановки синтагматических границ (паузы), блоком приписывания ритмических и акцентных характеристик (длительности и энергия), блоком приписывания тональных характеристик (частота основного тона). При расстановке синтагматических границ определяются части высказывания (синтагмы), внутри которых энергетические и тональные характеристики ведут себя единообразно и которые человек может произнести на одном дыхании. Если система не делает пауз на границах таких единиц, то возникает отрицательный эффект: слушающему кажется, что говорящий (в данном случае - система) задыхается. Помимо этого, расстановка синтагматических границ существенна и для фонемной транскрипции текста. Самое простое решение состоит в том, чтобы ставить границы там, где их диктует пунктуация. Для наиболее простых случаев, когда пунктуационные знаки отсутствуют, можно применить метод, основанный на использовании служебных слов. Именно эти методы используются в системах синтеза Рго-Sе-2000, Infovox- 5А-101 и DЕСTаLк, причем в последней просодически ориентированный словарь, помимо служебных слов, включает еще и глагольные формы.
Задача приписывания тональных характеристик обычно ставится достаточно узко. В системах синтеза речи предложению, как правило, приписывается нейтральная интонация. Не предпринималось попыток моделировать эффекты более высокого уровня, такие, как эмоциональная окраска речи, поскольку эту информацию извлечь из текста трудно, а часто и просто невозможно.
Функциональная структура использования СИИ.

Эта структура состоит из трех комплексов вычислительных средств (см. рисунок). Первый комплекс представляет собой совокупность средств, выполняющих программы (исполнительную систему), спроектированных с позиций эффективного решения задач, имеет в ряде случаев проблемную ориентацию. Второй комплекс - совокупность средств интеллектуального интерфейса, имеющих гибкую структуру, которая обеспечивает возможность адаптации в широком спектре интересов конечных пользователей. Третьим комплексом средств, с помощью которых организуется взаимодействие первых двух, является база знаний, обеспечивающая использование вычислительными средствами первых двух комплексов целостной и независимой от обрабатывающих программ системы знаний о проблемной среде. Исполнительная система (ИС) объединяет всю совокупность средств, обеспечивающих выполнение сформированной программы. Интеллектуальный интерфейс - система программных и аппаратных средств, обеспечивающих для конечного пользователя использование компьютера для решения задач, которые возникают в среде его профессиональной деятельности либо без посредников либо с незначительной их помощью. База знаний (БЗ) - занимает центральное положение по отношению к остальным компонентам вычислительной системы в целом, через БЗ осуществляется интеграция средств ВС, участвующих в решении задач.
Инструментальный комплекс для
Рассмотрим особенности инструментальных средств для создания статических ЭС на примере комплекса ЭКО, разработанного в РосНИИ ИТ и АП. Наиболее успешно комплекс применяется для создания ЭС, решающих задачи диагностики (технической и медицинской), эвристического оценивания (риска, надежности и т.д.), качественного прогнозирования, а также обучения.
Комплекс ЭКО используется: для создания коммерческих и промышленных экспертных систем на персональных ЭВМ, а также для быстрого создания прототипов экспертных систем с целью определения применимости методов инженерии знаний в некоторой конкретной проблемной области.
На основе комплекса ЭКО было разработано более 100 прикладных экспертных систем. Среди них отметим следующие:
поиск одиночных неисправностей в персональном компьютере; оценка состояния гидротехнического сооружения (Чарвакская ГЭС); подготовка деловых писем при ведении переписки с зарубежными партнерами; проведение скрининговой оценки иммунологического статуса; оценка показаний микробиологического обследования пациента, страдающего неспецифическими хроническими заболеваниями легких;
Инструментарий синтеза русской речи
Упоминавшийся выше инструментарий синтеза русской речи по тексту позволяет читать вслух смешанные русско-английские тексты. Инструментарий представляет собой набор динамических библиотек (DLL), в который входят модули русского и английского синтеза, словарь ударений русского языка, модуль правил произнесения английских слов. На вход инструментария подается слово или предложение, подлежащее произнесению, с выхода поступает звуковой файл в формате WAV или VOX, записываемый в память или на жесткий диск.
Интеллектуальный интерфейс
Предположим, что на вход ИС поступает текст. Будем говорить, то ИС понимает текст, если она дает ответы, правильные с точки зрения человека, на любые вопросы, относящиеся к тому, о чем говорится в тексте. Под "человеком" понимается конкретный человек-эксперт, которому поручено оценить способности системы к пониманию. Это вносит долю субъективизма, ибо разные люди могут по-разному понимать одни и те же тексты.
Интерфейс с конечным пользователем
Система G2 предоставляет разработчику богатые возможности для формирования простого, ясного и выразительного графического интерфейса с пользователем с элементами мультипликации. Предлагаемый инструментарий позволяет наглядно отображать технологические процессы практически неограниченной сложности на разных уровнях абстракции и детализации. Кроме того, графическое отображение взаимосвязей между объектами приложения может напрямую использоваться в декларативных конструкциях языка описания знаний.
RTworks не обладает собственными средствами для отображения текущего состояния управляемого процесса. Разработчик приложения вынужден использовать систему Dataview фирмы VI Corporation, что в значительной степени ограничивает его возможности.
Интерфейс с пользователем TDC Expert ограничен возможностями системы TDC 3000, т.е. взаимодействие с конечным пользователем
ограничивается текстовым режимом работы.
Интонационное обеспечение
Функция разработанных правил состоит в том, чтобы определить временные и тональные характеристики базовых элементов компиляции, которые при обработке синтагмы выбираются из библиотеки в нужной последовательности специальным процессором (блоком кодировки). Необходимые для этого предварительные операции над синтезируемым текстом: выделение синтагм, выбор типа интонации, определение степени выделенности (ударности-безударности) гласных и символьного звукового наполнения слоговых комплексов осуществляются блоком автоматического транскриптора.
Во временной процессор входят также правила, задающие длительность паузы после окончания синтагмы (конечной/неконечной), которые необходимы для синтеза связного текста. Предусмотрена также модификация общего темпа произнесения синтагмы и текста в целом, причем в двух вариантах: в стандартном - при равномерном изменении всех единиц компиляции - и в специальном, дающем возможность изменения длительности только гласных или только согласных.
Тональный процессор содержит правила формирования для одиннадцати интонационных моделей: нейтральная повествовательная интонация (точка), точковая интонация, типичная для фокусируемых ответов на вопросы; интонация предложений с контрастивным выделением отдельных слов; интонация специального и общего вопроса; интонация особых противопоставительных или сопоставительных вопросов; интонация обращений, некоторых типов восклицаний и команд; два вида незавершенности, перечислительная интонация; интонация вставочных конструкций.
Язык формальной записи правил синтеза
Для создания удобного и быстрого режима изменения и верификации правил, включенных в разные блоки синтезирующей системы, был разработан формализованный и в то же время содержательно прозрачный и понятный язык записи правил, который легко компилируется в исходные тексты программ. В настоящее время блок автоматического транскриптора насчитывает около 1000 строк, записанных на формализованном языке представления правил.
Экспертные системы реального времени - основное направление искусственного интеллекта
Среди специализированных систем, основанных на знаниях, наиболее значимы экспертные системы реального времени, или динамические экспертные системы. На их долю приходится 70 процентов этого рынка. Значимость инструментальных средств реального времени определяется не столько их бурным коммерческим успехом (хотя и это достойно тщательного анализа), но, в первую очередь, тем, что только с помощью подобных средств создаются стратегически значимые приложения в таких областях, как управление непрерывными производственными процессами в химии, фармакологии, производстве цемента, продуктов питания и т.п., аэрокосмические исследования, транспортировка и переработка нефти и газа, управление атомными и тепловыми электростанциями, финансовые операции, связь и многие другие. Классы задач, решаемых экспертными системами реального времени, таковы: мониторинг в реальном масштабе времени, системы управления верхнего уровня, системы обнаружения неисправностей, диагностика, составление расписаний, планирование, оптимизация, системы-советчики оператора, системы проектирования. Статические экспертные системы не способны решать подобные задачи, так как они не выполняют требования, предъявляемые к системам, работающим в реальном времени: 1. Представлять изменяющиеся во времени данные, поступающие от внешних источников, обеспечивать хранение и анализ изменяющихся данных. 2. Выполнять временные рассуждения о нескольких различных асинхронных процессах одновременно (т.е. планировать в соответствии с приоритетами обработку поступивших в систему процессов). 3. Обеспечивать механизм рассуждения при ограниченных ресурсах (время, память). Реализация этого механизма предъявляет требования к высокой скорости работы системы, способности одновременно решать несколько задач (т.е. операционные системы UNIX, VMS, Windows NT, но не MS-DOS). 4. Обеспечивать "предсказуемость" поведения системы, т.е. гарантию того, что каждая задача будет запущена и завершена в строгом соответствии с временными ограничениями.
Например, данное требование не допускает использования в экспертной системе реального времени механизма "сборки мусора", свойственного языку Lisp. 5. Моделировать "окружающий мир", рассматриваемый в данном приложении, обеспечивать создание различных его состояний. 6. Протоколировать свои действия и действия персонала, обеспечивать восстановление после сбоя. 7. Обеспечивать наполнение базы знаний для приложений реальной степени сложности с минимальными затратами времени и труда (необходимо использование объектно-ориентированной технологии, общих правил, модульности и т.п.). 8. Обеспечивать настройку системы на решаемые задачи (проблемная/предметная ориентированность). 9. Обеспечивать создание и поддержку пользовательских интерфейсов для различных категорий пользователей. 10. Обеспечивать уровень защиты информации (по категориям пользователей) и предотвращать несанкционированный доступ. Подчеркнем, что кроме этих десяти требований средства создания экспертных систем реального времени должны удовлетворять и перечисленным выше общим требованиям.
Этапы разработки экспертных систем
Разработка ЭС имеет существенные отличия от разработки обычного программного продукта. Опыт создания ЭС показал, что использование при их разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату.
Использовать ЭС следует только тогда, когда разработка ЭС возможна, оправдана и методы инженерии знаний соответствуют решаемой задаче. Чтобы разработка ЭС была возможной для данного приложения, необходимо одновременное выполнение по крайней мере следующих требований: существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
эксперты сходятся в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС; эксперты способны вербализовать (выразить на естественном языке) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС; решение задачи требует только рассуждений, а не действий; задача не должна быть слишком трудной (т.е. ее решение должно занимать у эксперта несколько часов или дней, а не недель); задача хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения и известные (хотя бы эксперту) способы получения решения задачи; решение задачи не должно в значительной степени использовать "здравый смысл" (т.е. широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), так как подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.Использование ЭС в данном приложении может быть возможно, но не оправдано. Применение ЭС может быть оправдано одним из следующих факторов:
решение задачи принесет значительный эффект, например экономический; использование человека-эксперта невозможно либо из-за недостаточного количества экспертов, либо из-за необходимости выполнять экспертизу одновременно в различных местах;использование ЭС целесообразно в тех случаях, когда при передаче информации эксперту происходит недопустимая потеря времени или информации;
использование ЭС целесообразно при необходимости решать задачу в окружении, враждебном для человека.
Приложение соответствует методам ЭС, если решаемая задача обладает совокупностью следующих характеристик:
задача может быть естественным образом решена посредством манипуляции с символами (т.е. с помощью символических рассуждений), а не манипуляций с числами, как принято в математических методах и в традиционном программировании;
задача должна иметь эвристическую, а не алгоритмическую природу, т.е. ее решение должно требовать применения эвристических правил. Задачи, которые могут быть гарантированно решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходят для применения ЭС;
задача должна быть достаточно сложна, чтобы оправдать затраты на разработку ЭС. Однако она не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решать;
задача должна быть достаточно узкой, чтобы решаться методами ЭС, и практически значимой.
При разработке ЭС, как правило, используется концепция "быстрого прототипа". Суть этой концепции состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования.
Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения.
В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария.
В ходе работ по созданию ЭС сложилась определенная технология их разработки, включающая шесть следующих этапов (рис. 1.4):
идентификацию, концептуализацию, формализацию, выполнение, тестирование, опытную эксплуатацию. На этапе идентификации определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей.

На этапе концептуализации проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач.
На этапе формализации выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями.
На этапе выполнения осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач.
Классификация систем распознавания речи
Классификация по назначению: командные системы системы диктовки текста
По потребительским качествам: диктороориентированные (тренируемые на конкретного диктора) дикторонезависимые распознающие отдельные слова распознающие слитную речь.
По механизмам функциониро-вания: простейшие (корреляционные) детекторы экспертные системы с различным способом формирования и обработки базы знаний вероятностно-сетевые модели принятия решения, в том числе нейронные сети.
Классификация уровней понимания
В существующих ИС можно выделить пять основных уровней понимания и два уровня метапонимания.
Первый уровень характеризуется схемой, показывающей, что любые ответы на вопросы система формирует только на основе прямого содержания, введенного из текста. Если, например, в систему введен текст: "В восемь утра, после завтрака, Петя ушел в школу. В два часа он вернулся домой. После обеда он ушел гулять", то на первом уровне понимания система обязана уметь отвечать правильно на вопросы типа: "Когда Петя ушел в школу?" или "Что сделал Петя после обеда?". В лингвистическом процессоре происходит морфологический, синтаксический и семантический анализ текста и вопросов, относящихся к нему. На выходе лингвистического процессора получается внутреннее представление текста и вопросов, с которыми может работать блок вывода. Используя специальные процедуры, этот блок формирует ответы. Другими словами, уже понимание на первом уровне требует от ИС определенных средств представления данных и вывода на этих данных.
Второй уровень: На втором уровне добавляются средства логического вывода, основанные на информации, содержащейся в тексте. Это разнообразные логики текста (временная, пространственная, каузальная и т. п., которые способны породить информацию, явно отсутствующую в тексте. Для нашего примера на втором уровне возможно формирование правильных ответов на вопросы типа: "Что было раньше: уход Пети в школу или его обед?" или "Гулял Петя после возвращения из школы?" Только построив временную структуру текста, ИС сможет ответить на подобные вопросы.
Схема ИС, с помощью которой может быть реализован второй уровень понимания, имеет еще одну базу знаний. В ней хранятся закономерности, относящиеся к временной структуре событий, возможной их пространственной организации, каузальной зависимости и т. п., а логический блок обладает всеми необходимыми средствами для работы с псевдофизическими логиками.
Третий уровень: К средствам второго уровня добавляются правила пополнения текста знаниями системы о среде.
Недостатком большинства известных в настоящее время систем планирования является их жесткая привязка к схеме планирования. Любая из них всегда ищет решение либо SS-проблемы, либо PR-проблемы. Связано это с фиксацией формы представления информации для планирования. Для классических моделей SS- и PR-проблем эти формы различны. Ясно, однако, что человек в своей деятельности успешно комбинирует шаги планирования из решения SS- и PR-проблем. Вторым недостатком является детерминированность систем планирования. В реальных ИС детерминированность планирования, как правило, не имеет места. Обобщение нечетких SS- и PR-проблем заключается в допущении нечетких состояний и нечетких операторов перехода из состояния в состояние. Разбиение задачи на подзадачи имеет весовые коэффициенты на дугах со значениями из [0, 1], которые интерпретируются как достоверности решения соответствующих подпроблем. Достоверность решения PR-проблемы определяется как минимум достоверностей решения ее подпроблем. При переходе к обобщенной стратегии из решений нечетких подпроблем PR-проблемы, рассматриваемых как нечеткие SS-проблемы, можно получить решение нечеткой PR-проблемы, рассматриваемой также как нечеткая SS-проблема. Схемой SS-проблемы называется пара M=(S,G), где S-множество состояний, G-множество отображений g: S->S, называемых операторами. Путем из состояния s0эS в состояние srэS называется конечная последовательность p=(( s0, , g0), (s1, g1),...,(sk-1, gk-1) sk ) , такая, что giO si= si+1 для i=0,..., k-1. SS-проблема-это четверка Р=(S, G, i ,f), где (S, G)-схема SS-проблемы, i, fэS-соответственно начальное и заключительное состояние. Путь х, ведущий из i в f, есть решение Р, а множество всех подобных путей составляет множество решений. Схемой PR-проблемы называется пара .N=(S , Г), где S
-множество проблем, Г-множество отображений g : S ->S+, называемых операторами. Если РэS , p эS+, то gр(p)-отображение, представляющее проблему Р в виде цепочки подпроблем p = P1...Pn. Для схемы N=(S , Г) накрывающий путь q из проблемы s0 в конечное множество проблем Sk= {s1,...,sn} эS+ является конечной последовательностью, где q= ((x0 , y0), (x1, y1),..., (xk-1, yk-1), xk), xi э S+ для i=0,...,k, yэS+ для i=0,..., k-1, так что x0=s0, xkэS+k.
В общем виде под продукцией понимается выражение следующего вида: (i); Q;P;AЮB;N. Здесь i - имя продукции, с помощью которого данная продукция выделяется из всего множества продукций. В качестве имени может выступать некоторая лексема, отражающая суть данной продукции (например, "покупка книги " ), или порядковый номер продукций в их множестве, хранящимся в памяти системы. Элемент Q характеризует сферу применения продукции. Такие сферы легко выделяются в когнитивных структурах человека. Наши знания как бы "разложены по полочкам". На одной полочке хранятся знания о том, как надо готовить пищу, на другой как добраться до работы, и т.п. Разделение знаний на отдельные сферы позволяет экономить время на поиск нужных знаний. Такое же разделение на сферы в базе знаний ИИ целесообразно и при использовании для представления знаний продукционных моделей. Основным элементом продукции является ее ядро: AЮB. Интерпретация ядра продукции может быть различной и зависит от того, что стоит слева и справа от знака секвенции Ю. Обычное прочтение ядра продукции выглядит так: ЕСЛИ А, ТО В, более сложные конструкции ядра допускают в правой части альтернативный выбор, например , ЕСЛИ А, ТО В1, ИНАЧЕ B2. Секвенция может истолковываться в обычном логическом смысле как знак логического следования В из истинного А (если А не является истинным выражением, то о В ничего сказать нельзя). Возможны и другие интерпретации ядра продукции, например А описывает некоторое условие, необходимое для того, чтобы можно было совершить действие В. Элемент Р есть условие применимости ядра продукции. Обычно Р представляет собой логическое выражение (как правило предикат). Когда Р принимает значение "истина", ядро продукции активизируется. Если Р "ложно", то ядро продукции не может быть использовано. Элемент N описывает постусловия продукции. Они актуализируются только в том случае, если ядро продукции реализовалось. Постусловия продкции описывают действия и процедуры, которые необходимо выполнить после реализации В.
Начало исследований в области ИИ (конец 50-х годов) связывают с работами
Ньюэлла, Саймана и Шоу, исследовавших процессы решения различных задач.
Результатами их работ явились такие программы как "ЛОГИК-ТЕОРЕТИК",
предназначенная для доказательства теорем в исчислении высказываний, и
"ОБЩИЙ РЕШАТЕЛЬ ЗАДАЧ". Эти работы положили начало первому этапу
исследований в области ИИ, связанному с разработкой программ, решающих
задачи на основе применения разнообразных эвристических методов.
Эвристический метод решения задачи при этом рассматривался как
свойственный человеческому мышлению "вообще", для которого
характерно возникновение догадок о пути решения задачи с последующей
проверкой их. Ему противопоставлялся используемый в ЭВМ алгоритмический
метод, который интерпретировался как механическое осуществление заданной
последовательности шагов, детерминированно приводящей к правильному
ответу. Трактовка эвристических методов решения задач как сугубо
человеческой деятельности и обусловила появление и дальнейшее
распространение термина ИИ. Так, при описании своих программ Ньюэлл и
Саймон приводили в качестве доводов, подтверждающих, что их программы
моделируют человеческое мышление, результаты сравнения записей доказательств
теорем в виде программ с записями рассуждения человека. В
начале 70-х годов они опубликовали много данных подобного рода и предложили
общую методику составления программ, моделирующих мышление. Примерно в то
время, когда работы Ньюэлла и Саймона стали привлекать к себе внимание, в
Массачусетсском технологическом институте, Стэнфордском университете и
Стэнфордском исследовательском институте также сформировались
исследовательские группы в области ИИ. В противоположность ранним работам
Ньюэлла и Саймона эти исследования больше относились к формальным
математическим представлениям. Способы решения задач в этих исследованиях
развивались на основе расширения математической и символической логики.
Моделированию же человеческого мышления придавалось второстепенное значение.
Эти знания в ИС, как правило, носят логический характер и фиксируются в виде сценариев или процедур иного типа. На третьем уровне понимания ИС должна дать правильные ответы на вопросы типа: "Где был Петя в десять утра?" или "Откуда Петя вернулся в два часа дня?" Для этого надо знать, что означает процесс "пребывание в школе" и, в частности, что этот процесс является непрерывным и что субъект, участвующий в нем, все время находится "в школе".
Схема ИС, в которой реализуется понимание третьего уровня, внешне не отличается от схемы второго уровня. Однако в логическом блоке должны быть предусмотрены средства не только для чисто дедуктивного вывода, но и для вывода по сценариям.
Три перечисленных уровня понимания реализованы во всех практически работающих ИС. Первый уровень и частично второй входят в разнообразные системы общения на естественном языке.
Следующие два уровня понимания реализованы в существующих ИС лишь частично.
Четвертый уровень: Вместо текста в ней используется расширенный текст, который порождается лишь при наличии двух каналов получения информации. По одному в систему передается текст, по другому-дополнительная информация, отсутствующая в тексте. При человеческой коммуникации роль второго канала, как правило, играет зрение. Более одного канала коммуникации имеют интеллектуальные роботы, обладающие зрением.
Зрительный канал коммуникации позволяет фиксировать состояние среды "здесь и сейчас" и вводить в текст наблюдаемую информацию. Система становится способной к пониманию текстов, в которые введены слова, прямо связанные с той ситуацией, в которой порождается текст. На более низких уровнях понимания нельзя понять, например, текст: "Посмотрите, что сделал Петя! Он не должен был брать это!" При наличии зрительного канала процесс понимания становится возможным.
При наличии четвертого уровня понимания ИС способна отвечать на вопросы типа: "Почему Петя не должен был брать это?" или "Что сделал Петя?" Если вопрос, поступивший в систему, соответствует третьему уровню, то система выдает нужный ответ.
Если для ответа необходимо привлечь дополнительную ("экзегетическую") информацию, то внутреннее представление текста и вопроса передается в блок, который осуществляет соотнесение текста с той реальной ситуацией его порождения, которая доступна ИС по зрительному или какому-нибудь иному каналу фиксации ситуации внешнего мира.
Пятый уровень: Для ответа на этом уровне ИС кроме текста использует информацию о конкретном субъекте, являющемся источником текста, и хранящуюся в памяти системы общую информацию, относящуюся к коммуникации (знания об организации общения, о целях участников общения, о нормах участия в общении). Теория, соответствующая пятому уровню,-это так называемая теория речевых актов.
Было обращено внимание на то, что любая фраза не только обозначает некое явление действительности, но и объединяет в себе три действия: локуцию, иллокуцию и перлокуцию. Локуция-это говорение как таковое, т. е. те действия, которые говорящий произвел, чтобы высказать свою мысль. Иллокуция - это действие при помощи говорения: вопрос, побуждение (приказ или просьба) и утверждение. Перлокуция - это действие, которым говорящий пытается осуществить некоторое воздействие на слушающего: "льстить", "удивлять", "уговаривать" и т. д. Речевой акт можно определить как минимальную осмысленную (или целесообразную) единицу речевого поведения. Каждый речевой акт состоит из локутивного, иллокутивного и перлокутивного акта.
Для четвертого и пятого уровней понимания интересны результаты по невербальным (несловесным) компонентам общения и психологическим принципам, лежащим в основе общения. Кроме того, в правила пополнения текста входят правила вывода, опирающиеся на знания о данном конкретном субъекте общения, если такие знания у системы есть. Например, система может доверять данному субъекту, считая, что порождаемый им текст истинен. Но может не доверять ему и понимать текст, корректируя его в соответствии со своими знаниями о субъекте, породившем текст. Знания такого типа должны опираться на психологические теории общения, которые пока развиты недостаточно.
Например, на вход системы поступает текст: "Нина обещала скоро прийти". Если о Нине у системы нет никакой информации, она может обратиться к базе знаний и использовать для оценки временного указателя "скоро некоторую нормативную информацию. Из этой информации можно узнать, что с большой долей уверенности "скоро" не превышает полчаса. Но у системы может иметься специальная информация о той Нине, о которой идет речь во входном тексте. В этом случае система, получив нужную информацию из базы знаний, может приготовиться, например, к тому, что Нина скорее всего придет не ранее чем через час.
Первый метауровень: На этом уровне происходит изменение содержимого базы знаний. Она пополняется фактами, известными системе и содержащимися в тех текстах, которые в систему введены. Разные ИС отличаются друг от друга характером правил порождения фактов из знаний. Например, в системах, предназначенных для экспертизы в области фармакологии, эти правила опираются на методы индуктивного вывода и распознавания образов. Правила могут быть основаны на принципах вероятностей, размытых выводов и т. п. Но во всех случаях база знаний оказывается априорно неполной и в таких ИС возникают трудности с поиском ответов на запросы. В частности, в базах знаний становится необходимым немонотонный вывод.
Второй метауровень: На этом уровне происходит порождение метафорического знания. Правила порождения знаний метафорического уровня, используемые для этих целей, представляют собой специальные процедуры, опирающиеся на вывод по аналогии и ассоциации. Известные в настоящее время схемы вывода по аналогии используют, как правило, диаграмму Лейбница, которая отражает лишь частный случай рассуждений по аналогии. Еще более бедны схемы ассоциативных рассуждений.
Если рассматривать уровни и метауровни понимания с точки зрения архитектуры ИС, то можно наблюдать последовательное наращивание новых блоков и усложнение реализуемых ими процедур. На первом уровне достаточно лингвистического процессора с базой знаний, относящихся только к самому тексту.
На втором уровне в этом процессоре возникает процедура логического вывода. На третьем уровне необходима база знаний. Появление нового канала информации, который работает независимо от исходного, характеризует четвертый уровень. Кроме процедур, связанных с работой этого канала, появляются процедуры, увязывающие между собой результаты работы двух каналов, интегрирующие информацию, получаемую по каждому из них. На пятом уровне развитие получают разнообразные способы вывода на знаниях и данных. На этом уровне становятся важными модели индивидуального и группового поведения. На метауровнях возникают новые процедуры для манипулирования знаниями, которых не было на более низких уровнях понимания. И этот процесс носит открытый характер. Понимание в полном объеме - некоторая, по-видимому, недостижимая мечта. Но понимание на уровне "бытового понимания" людей в ИС вполне достижимо.
Существуют и другие интерпретации феномена понимания. Можно, например, оценивать уровень понимания по способности системы к объяснению полученного результата. Здесь возможен не только уровень объяснения, когда система объясняет, что она сделала, например, на основе введенного в нее текста, но и уровень обоснования (аргументации), когда система обосновывает свой результат, показывая, что он не противоречит той системе знаний и данных, которыми она располагает. В отличие от объяснения обоснование всегда связано с суммой фактов и знаний, которые определяются текущим моментом существования системы. И вводимый для понимания текст в одних состояниях может быть воспринят системой как истинный, а в других-как ложный. Кроме объяснения и обоснования возможна еще одна функция, связанная с пониманием текстов,- оправдание. Оправдать нечто означает, что выводимые утверждения не противоречат той системе норм и ценностей, которые заложены в ИС. Существующие ИС типа экспертных систем, как правило, способны давать объяснения и лишь частично обоснования. В полном объеме процедуры обоснования и оправдания еще не реализованы.
Комплексная схема нечеткого планирования
Подчеркнем, что как синтаксис, так и семантика подхода разбиения проблемы на подпроблемы не предполагают предварительного определения проблемы. Поэтому можно в качестве проблемы выбрать SS-проблему.
Рассмотрим понятие, объединяющее подходы разбиения проблемы на под-проблемы и поиска в пространстве состояний. 1-проблемой (объединенной проблемой) называется четверка R=(B, Г, Р0, Т), где В-множество SS-проблем;
(В, Г)-схема PR-проблем; Р0эB -основная проблема;T-импликативная сеть, такая, что WTЗB"Ж. Кроме того, R есть решение SS-проблемы Р0. Учитывая связь между существованием импликативной сети и разрешимостью проблемы, легко показать, что если для заданной I-проблемы найден накрывающий путь х из Р0 на множество Ф'Н В, проблемы Ф' разрешимы как SS-проблемы, если х частично представляет импликативную сеть Т, то и проблема R разрешима как SS-проблема.
Рассмотрим головоломку "Ханойская башня" . Имеются три стержня 1, 2 и 3 и три диска различных размеров А, В, С с отверстием в центре, которые могут одеваться на стержни. В исходной позиции диски находятся на стержне 1; самый большой диск С-внизу, самый маленький диск А- наверху. Требуется перенести все диски на стержень 3, перемещая за один раз только один диск. Брать можно только самый верхний диск на стержне, причем его нельзя класть на диск, меньший по размерам. Используем для записи состояний и операторов классическую формализацию. Выражение ijk обозначает конфигурацию, при которой диск С находится на стержне i, диск В - на стержне j и диск А-на стержне k. Выражение xij обозначает действие, при котором диск х перемещается со стержня i на стержень j. С помощью этого формализма можно просто записать все состояния и переходы головоломки в виде треугольного графа, где вершины соответствуют расположению дисков на стержнях, а дуги-возможным перекладываниям дисков (рис.1). На этой головоломке легко проиллюстрировать все основные понятия обобщенной стратегии проблем.
Представим головоломку в виде модели I-проблемы.
Рассмотрим I-проблему R=(B, Г, P0T), где B={Р0, P1,...,P9}; Г={g }; T=={L1,L2,L3}. SS-проблемы Р0,P1..., P9 определяются следующим образом. На рис. 1 показана схема SS-проблемы M==(S, G), где
P0=(S, G, 111, 333), P1=(S, G, 111, 122), P2=(S, G, 122, 322),
Рз=(S, G, 322, 333), P4=(S, G, 111, 113), P5,=(S, G, 113, 123),
P6==(S, G, 123, 122), P7=(S, G, 322, 321), P8=(S, G, 321, 331),
P9=(S G, 331,333).
Схема PR-проблемы N= (В, Г) приведена на рис. 2; импликативная сеть Т- на рис.3, причем L1=(P0, P1Р2Р3, Y), L2= (P1, P4P5P6, Y), L з== (Р3, P7P8P9,Y ), где Y (x1,x2,x3)=x1x2x3.
Проблемы Р2 и P4-P9 решаются перекладыванием одного диска и являются элементарными. Проблемы P1 и Р3 решаются с помощью манипуляций только с дисками В и А и являются более простыми, чем Р0. Проблемы P1 и Р3 решаются, а проблема Р0 сводится к P1, P2 и Р3 аналогичной манипуляцией с дисками, синтаксис которой выражен оператором g, а семантика - отображением Y .
Представление этой головоломки в виде PR-проблемы (рис.2) является более компактным и наглядным, чем представление в виде SS-проблемы (рис.1), а представление в виде I-проблемы (рис..3) сочетает достоинство обоих и показывает взаимосвязь подпроблем и тех действий, которые нужно выполнить, чтобы решить головоломку.
Приведенные определения обобщаются на нечеткий случай, когда состояние системы, для которой строится модель решения проблемы, не является точно заданным, а результаты действий системы
неоднозначны.

Например,у робототехнической системы это может быть связано с несовершенством эф-фекторов и рецепторов, с ограниченными размерами внутренней модели, не отражающей сложности окружающего мира.
Нечеткой SS-проблемой назовем SS-проблему, у которой i , f-нечеткие множества, операторы g эГ-нечеткие матрицы, a-решением нечеткой SS-проблемы называется путь g=g1...gn,giэG,i=1,...,n, такой, что iOg1O... ... OgnOf? a , где О - максимальное произведение нечетких матриц.
Нечеткой PR-проблемой называется PR-проблема, у которой элементам g эГ приписывается степень принадлежности m g (p )э[0,1], a-решением нечеткой PR-проблемы называется решение PR-проблемы, для которой mingij? a,gij эyi.

Накрывающий путь в этом случае называется накрывающим a-путем. Степень принадлежности m g ( p ) интерпретируется как степень возможности разбиения проблемы на подпроблемы.
Нечеткой импликативной схемой называется импликативная схема, все отображения Y которой имеют степень принадлежности m Y ((p )э[0,1]. Степень принадлежности интерпретируется как возможность получения решения проблемы из решений соответствующих подпроблем. Нечеткой импликативной сетью называется импликативная сеть с нечеткими импликативными схемами.Нечеткая PR-проблема представляет нечеткую импликативную сеть, если кроме обычных условий для импликативной сети выполняется неравенство m Y (p )? m g (p ) ? a ,
т. е. возможность разбиения на подпроблемы не меньше возможности получения решения для каждой пары соответствующих Y и g.
Аналогично определяется нечеткая I-проблема. Но построить a-решение нечеткой PR-проблемы по a-решениям ее нечетких подпроблем можно лишь в частных случаях и при наложении дополнительных условий. Пусть задана нечеткая PR-проблема, где S-нечеткие SS-проблемы, и существует простейшее a-решение Z,
т.е.такое p э S +,что m g p ? a,и если p =P1..Pn,то все проблемы Pi a-разрешимы,
где Pi=(Si,Gi,Ji,Fi ).a-решение проблемы P0 существует при m Y (p )? m g (p )? a для импликативной сети.Запишем более конструктивное условие для этого.Пусть для всех i оператор gi есть a-путь решения проблемы Piи Fi=Ji+1.Тогда,если выполняется
max m [FnЗ (Fn-1З (...F1З (J o g1)o g2)...)o gn)]? a
и g=g1...gn,то g- a-решение SS-проблемы P0.
Компоненты продукционных систем
Выполнение N может проиходить сразу после реализации ядра продукции.
Если в памяти системы хранится некоторый набор продукций, то они образуют систему продукций. В системе продукций должны быть заданы специальные процедуры управления продукциями, с помощью которых происходит актуализация продукций и выбор для выполнения той или иной продукции из числа актуализированных. В ряде систем ИИ используют комбинации сетевых и продукционных моделей представления знаний. В таких моделях декларативные знания описываются в сетевом компоненте модели, а процедурные знания - в продукционном. В этом случае говорят о работе продукционной системы над семантической сетью.
Классификация ядер продукции.
Ядра продукции можно классифицировать по различным основаниям. Прежде всего все ядра делятся на два больших типа: детерминированные и недетерминированные. В детерминированных ядрах при актуализации ядра и при выполнимости А правая часть ядра выполняется обязательно; в недетерминированных ядрах В может выполняться и не выполняться. Таким образом, секвенция Ю в детерминированных ядрах реализуется с необходимостью, а в недетерминированных - с возможностью. Интерпретация ядра в этом случае может, например, выглядеть так: ЕСЛИ А, ТО ВОЗМОЖНО В.
Возможность может определяться некоторыми оценками реализации ядра. Например, если задана вероятность выполнения В при актуализации А, то продукция может быть такой: ЕСЛИ А, ТО С ВЕРОЯТНОСТЬЮ р РЕАЛИЗОВАТЬ В. Оценка реализации ядра может быть лингвистической, связанной с понятием терм-множества лингвистической переменной, например: ЕСЛИ А, ТО С БОЛЬШЕЙ ДОЛЕЙ УВЕРЕННОСТИ В. Возможны иные способы реализации ядра.
Детерминированные продукции могут быть однозначными и альтернативными. Во втором случае в правой части ядра указываются альтернативные возможности выбора, которые оцениваются специальными весами выбора. В качестве таких весов могут использоваться вероятностные оценки, лингвистические оценки, экспертные оценки и т.п.
Особым типом являются прогнозирующие продукции, в которых описываются последствия, ожидаемые при актуализации А, например: ЕСЛИ А, ТО С ВЕРОЯТНОСТЬЮ р МОЖНО ОЖИДАТЬ В.
Дальнейшую классификацию ядер продукции можно провести, опираясь на типовую схему СИИ (рис. 1) Если x и y обозначают любой из блоков рисунка (О,Д,З,Л), то ядро АxЮBy означает, что информация об А берется из блока x, а результат срабатывания продукции В посылает в блок y. Комбинации x и y, осмысленные с точки зрения СИИ, отмечены в табл.1 знаком "+"
Т а б л и ц а 1
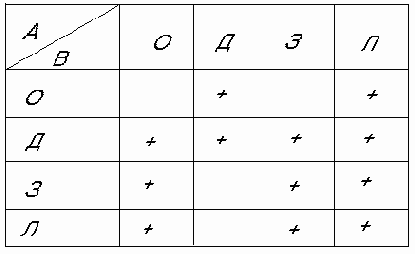

Рис 1
Рассмотрим часто встречающийся тип продукции А3ЮВ3. В этом случае А3 и В3 представляют собой некоторые фрагменты информации, хранящейся в базе знаний. При сетевом представлении это могу быть фрагменты семантической сети, при логических моделях - формулы того или иного исчисления. Тогда смысл продукции А3ЮВ3 состоит в замене одного фрагмента базы знаний другим. Для актуализации этой продукции необходимо, чтобы в базе знаний существовал фрагмент, совпадающий с А. При поиске в базе знаний А играет роль образца, а процедура такого писка называется поиском по образцу.
Краткий исторический обзор развития работ в области ИИ.
На дальнейшие исследования в области ИИ большое влияние оказало появление
метода резолюций Робинсона, основанного на доказательстве теорем в логике
предикатов и являющегося исчерпывающим методом доказательства. При этом
определение термина ИИ претерпело существенное изменение. Целью исследований,
проводимых в направлении ИИ, стала разработка программ, способных решать
"человеческие задачи". Так, один из видных исследователей ИИ того
времени Р. Бенерджи в 1969 году писал: "Область исследований, обычно
называемую ИИ, вероятно, можно представить как совокупность методов и средств
анализа и конструирования машин, способных выполнять задания, с которыми до
недавнего времени мог справиться только человек. При этом по скорости и
эффективности машины должны быть сравнимы с человеком." Функциональный
подход к направленности исследований по ИИ сохранился в основном до настоящего
времени, хотя еще и сейчас ряд ученых, особенно психологов, пытаются
оценивать результаты работ по ИИ с позиций их соответствия человеческому
мышлению.
Исследовательским полигоном для развития методов ИИ на первом этапе
явились всевозможные игры, головоломки, математические задачи. Некоторые
из этих задач стали классическими в литературе по ИИ (задачи об обезьяне и
бананах, миссионерах и людоедах, Ханойской башне игра в 15 и другие).
Выбор таких задач обуславливался простотой и ясностью проблемной среды
(среды, в которой разворачивается решение задачи), ее относительно малой
громоздкостью, возможностью достаточно легкого подбора и даже
искусственного конструирования "под метод". Основной расцвет
такого рода исследований приходится на конец 60-х годов, после чего стали
делаться первые попытки применения разработанных методов для задач, решаемых
не в искусственных, а в реальных проблемных средах. Необходимость исследования
систем ИИ при их функционировании в реальном мире привело к постановке
задачи создания интегральных роботов. Проведение таких работ можно считать
вторым этапом исследований по ИИ.
В Стэнфордском университете, Стэнфордском
исследовательском институте и некоторых других местах были разработаны
экспериментальные роботы, функционирующие в лабораторных условиях. Проведение
этих экспериментов показало необходимость решения кардинальных вопросов,
связанных с проблемой представления знаний о среде функционирования, и
одновременно недостаточную исследованность таких проблем, как зрительное
восприятие, построение сложных планов поведения в динамических средах,
общение с роботами на естественном языке. Эти проблемы были более ясно
сформулированы и поставлены перед исследователями в середине 70-х гг,
связанных с началом третьего этапа исследований систем ИИ. Его характерной
чертой явилось смещение центра внимания исследователей с создания автономно
функционирующих систем, самостоятельно решающих в реальной среде поставленные
перед ними задачи, к созданию человеко-машинных систем, интегрирующих в единое
целое интеллект человека и способности ВМ для достижения общей цели - решение
задачи, поставленной перед интегральной человеко-машинной решающей
системой. Такое смещение обуславливалось двумя причинами:
К этому времени выяснилось, что даже простые на первый взгляд задачи,
возникающие перед интегральным роботом при его функционирование в
реальном времени, не могут быть решены методами, разработанными для
экспериментальных задач специально сформированных проблемных средах;
Стало ясно, что сочетание дополняющих друг друга возможностей человека
и ЭВМ позволяет обойти острые углы путем перекладывания на человека
тех функций, которые пока еще не доступны для ЭВМ.
На первый план выдвигалась не разработка отдельных методов машинного
решения задач, а разработка методов средств, обеспечивающих тесное
взаимодействие человека и вычислительной системы в течение всего процесса
решения задачи с возможностью оперативного внесения человеком изменений в
ходе этого процесса.
Развитие исследований по ИИ в данном направлении обусловливалось также
резким ростом производства средств вычислительной техники и также резким
их удешевлением, делающим их потенциально доступными для более широких
кругов пользователей.
Лекции 2-3: Модели и методы решения задач
Классификация представления задач.
Логические модели.
Сетевые модели
Продукционные модели.
Сценарии.
Интеллектуальный интерфейс
Классификация уровней понимания
Методы решения задач.
Решение задач методом поиска в пространстве состояний.
Решение задач методом редукции.
Решение задач дедуктивного выбора
Решение задач, использующие немонотонные логики, вероятностные логики.
Лекции 7-8: Экспертные системы
Назначение экспертных систем
Структура экспертных систем
Этапы разработки экспертных систем
Интерфейс с конечным пользователем
Представление знаний в ЭС
Уровни представления и уровни детальности
Организация знаний в рабочей системе
Организация знаний в базе данных
Методы поиска решений в экспертных системах
Инструментальный комплекс для создания статических экспертных систем (на примере интегрированного комплекса ЭКО)
Средства представления знаний и стратегии управления
Инструментальный комплекс для создания экспертных систем реального времени (на примере интегрированной среды g2-gensym corp., Сша)
Лекция 1: Введение
Лекция 4: Представление знаний в интеллектуальных системах
Предисловие Данные и знания. Основные определения. Особенности знаний. Переход от Базы Данных к Базе Знаний. Модели представления знаний. Неформальные (семантические) модели. Формальные модели представления знаний.
Лекция 5: Представление знаний в интеллектуальных системах (часть 2)
Продукционные системы Компоненты продукционных систем Стратегии решений организации поиска Логический подход. Представление простых фактов в логических системах Примеры применения логики для представления знаний Литература
Лекция 6: Планирование задач
Основные определения Комплексная схема нечеткого планирования Особенности планирования целенаправленных действий Оценка сложности задачи планирования Литература
Лекция 9: Методы работы со знаниями
Основные определения Подготовительный этап Основной этап Системы приобретения знаний от экспертов Формализация качественных знаний Пример формализации качественных знаний
Лекция 10: Системы понимания естественного языка
Введение Предпосылки возникновения систем понимания естественного языка Понимание в диалоге Примеры системы обработки естественного языка Методы озвучивания речи Наиболее распространенные системы синтеза речи Речевой вывод информации Автоматический компьютерный синтез речи по тексту Методы синтеза речи Обобщенная функциональная структура синтезатора Модуль лингвистической обработки Лингвистический анализ Формирование просодических характеристик Cинтезатор русской речи Язык формальной записи правил синтеза Интонационное обеспечение Аллофонная база данных Лингвистический анализ Инструментарий синтеза русской речи Система распознавания речи Акустическая модель Лингвистическая модель Классификация систем распознавания речи Заключение Литература
Лекция 11: Системы машинного зрения
Введение Основные принципы или целостность восприятия Распознавание символов Шаблонные системы Структурные системы Признаковые системы Структурно-пятенный эталон Уроки машинного чтения от Cognitive Technologies Распознавание рукописных текстов Резюме
Лекция 12: Тенденции развития систем искусственного интеллекта
Введение Состояние и тенденции развития искусственного интеллекта Успехи систем искусственного интеллекта и их причины Экспертные системы реального времени - основное направление искусственного интеллекта Основные производители Архитектура экспертной системы реального времени Жизненный цикл приложения Разработка прототипа приложения Расширение прототипа до приложения Тестирование приложения на ниличие ошибок Тестирование логики приложения и ограничений (по времени и памяти) Сопровождение приложения Основные компоненты База знаний Сущности и иерархия классов Иерархия модулей и рабочих пространств Структуры данных Выполняемые утверждения Машина вывода, подсистема моделирования и планировщик Заключение Литература
Лингвистическая модель
Лингвистический блок подразделяется на следующие ярусы (слои, уровни); фонетический, фонологический, морфологический, лексический,синтаксический, семантический.Всего их шесть. За основу взят русский язык. Все ярусы суть априорная информация о структуре естественного языка, а, как известно, любая априорная информация об интересующем предмете увеличивает шансы принятия верного решения. На том стоит вся статистическая радиотехника. А естественный язык несет весьма сильно структурированную информацию, из чего, кстати, вытекает, что для каждого естественного языка может потребоваться своя уникальная лингвистическая модель (предвижу трудности с русификацией сложных систем распознавания речи). В соответствии с данной моделью на первом - фонетическом- уровне производится преобразование входного (для лингвистического блока) представления речи в последовательность фонем, как наименьших единиц языка. Считается, что в реальном речевом сигнале можно обнаружить лишь аллофоны - варианты фонем, зависящие от звукового окружения. Но сути это не меняет. Обратите внимание, что фонемы сотоварищи могут перекочевать в лингвистический блок. На следующем - фонологическом - уровне накладываются ограничения на комбинаторику фонем (аллофонов). Ограничение - это правило наизнанку, значит, опять есть полезная априорная информация: не все сочетания фонем (аллофонов) встречаются, а те, что встречаются, имеют различную вероятность появления, зависящую еще и от окружения. Для описания этой ситуации используется математический аппарат цепей Маркова. Далее, на морфологическом уровне оперируют со слогоподобными единицами речи более высокого уровня, чем фонема. Иногда они называются морфемами. Они накладывают ограничение уже на структуру слова, подчиняясь закономерностям моделируемого естественного языка. Лексический ярус охватывает слова и словоформы того или иного естественного языка, то есть словарь языка, так же внося важную априорную информацию о том, какие слова возможны для данного естественного языка. Семантика устанавливает соотношения между объектами действительности и словами, их обозначающими. Она является высшим уровнем языка. При помощи семантических отношений интеллект человека производит как бы сжатие речевого сообщения в систему образов, понятий, представляющих суть речевого сообщения. Отсюда следует вывод, что система должна быть "умной". Чем лучше у нее будет построена модель семантических связей, эквивалента "системы мысленных образов", тем больше вероятность правильно распознать речь.
Лингвистический анализ
После процедуры нормализации каждому слову текста (каждой словоформе) необходимо приписать сведения о его произношении, то есть превратить в цепочку фонем или, иначе говоря, создать его фонемную транскрипцию. Во многих языках, в том числе и в русском, существуют достаточно регулярные правила чтения -правила соответствия между буквами и фонемами (звуками), которые, однако, могут требовать предварительной расстановки словесных ударений. В английском языке правила чтения очень нерегулярны, и задача данного блока для английского синтеза тем самым усложняется. В любом случае при определении произношения имен собственных, заимствований, новых слов, сокращений и аббревиатур возникают серьезные проблемы. Просто хранить транскрипцию для всех слов языка не представляется возможным из-за большого объема словаря и контекстных изменений произношения одного и того же слова во фразе.
Кроме того, следует корректно рассматривать случаи графической омонимии: одна и та же последовательность буквенных символов в различных контекстах порой представляет два различных слова/словоформы и читается по-разному (ср. выше приведенный пример слова "замок"). Часто удается решить проблему неоднозначности такого рода путем грамматического анализа, однако иногда помогает только использование более широкой семантической информации.
Для языков с достаточно регулярными правилами чтения одним из продуктивных подходов к переводу слов в фонемы является система контекстных правил, переводящих каждую букву/буквосочетание в ту или иную фонему, то есть автоматический фонемный транскриптор. Однако чем больше в языке исключений из правил чтения, тем хуже работает этот метод. Стандартный способ улучшения произношения системы состоит в занесении нескольких тысяч наиболее употребительных исключений в словарь. Альтернативное подходу "слово-буква-фонема" решение предполагает морфемный анализ слова и перевод в фонемы морфов (то есть значимых частей слова: приставок, корней, суффиксов и окончаний). Однако в связи с разными пограничными явлениями на стыках морфов разложение на эти элементы представляет собой значительные трудности. В то же время для языков с богатой морфологией, например, для русского, словарь морфов был бы компактнее. Морфемный анализ удобен еще и потому, что с его помощью можно определять принадлежность слов к частям речи, что очень важно для грамматического анализа текста и задания его просодических характеристик. В английских системах синтеза морфемный анализ был реализован в системе МIТа1к, для которой процент ошибок транскриптора составляет 5%.
Особую проблему для данного этапа обработки текста образуют имена собственные.
На основе данных, полученных от остальных модулей синтеза речи и от аллофонной базы, программа формирования акустического сигнала позволяет осуществлять модификацию длительности согласных и гласных. Она дает возможность модифицировать длительность отдельных периодов на вокальных звуках, используя две или три точки тонирования на аллофонном сегменте, осуществляет модификацию энергетических характеристик сегмента и соединяет модифицированные аллофоны в единую слитную речь.
На этапе синтеза акустического сигнала программа позволяет получать разнообразные акустические эффекты -такие как реверберация, эхо, изменение частотной окраски.
Готовый акустический сигнал преобразуется в формат данных, принятый для вывода звуковой информации. Используются два формата: WAV (Waveform Audio File Format), являющийся одним из основных, или VОХ (Voice File Format), широко используемый в компьютерной телефонии. Вывод также может осуществляться непосредственно на звуковую карту.
Литература
Перспективы развития вычислительной техники.Кн.2. Интеллектуализация ЭВМ.М., 1989 Уинстон П. Искусственный интеллект. М.1980. Хант Э. Искусственный интеллект. М.1978.
| Оглавление | Вперед |
| Каталог | Индекс раздела |
F. Hayes-Roth, N. Jacobstein. The State of Enowledge-Based Systems. Communications of the АСМ, March, 1994, v.37, n.3, рр.27-39. Р. Harmon. The Size of the Commercial AI Market in the US. Intelligent Software Strategies. 1994, v.10, n.1, рр. 1-6. Expert system saves 20 million L on pipeline management. C&I July, 1994, р.31. Д. Поспелов . "Справочник по ИИ том-2".
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Аверкин А.Н. и др. .Обобщенные стратегии в решателях проблем. Диковский А.Я. , Канович М.И. . Вычислительные модели с разделяемыми подзадачами. Ефимов Е.И. Решатели интеллектуальных задач. Эрлих А.И. . Диалоговая система моделирования альтернатив и выбора решений в проектировании / Представление знаний в человеко-машинных и робото-технических системах. Файкс Р, Нильсон Н. . Система STRIPS - новый подход к применению доказательства при решении задач / / Интегральные роботы. Ньюэлл А. Эмпирические исследования машин "Логик-теоретик": пример изучения эвристики.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Логический подход к искусственному интеллекту. / Под ред. Гаврилова Г.П. - М.: Мир,1990. Эндрю А. Искусственный интеллект / Под ред. Поспелова Д.А. - М.: Мир, 1985. Internet.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
Компьютерра 08.12.97.p.26-43 Ю.М.Смирнов. Интеллектуализация ЭВМ.Москва,Высшая школа,1989 г. Expert system saves 20 million L on pipeline management. C&I July, 1994, р.31. Р. Harmon. The Market for Intelligent Software Products. Intelligent Sopware Strategies 1992, v.8, n.2, рр.5-12. D.R Perley. Migrating to Open Systems: Taming he Tiger. McGraw-Hill, 1993, р.252. Р. Harmon. The AI Tools Market The Market for Intelligent Software Building Tools. Part I. Intelligent Softwane Strategies, 1994, v 10, n.2, pp.1-14. Р. Harmon. The market for intelligent software pnducts Intelligent Software Strategies, 1992, v.8, n.2, рр.5-12. B.R. Clements and F. Preto. Evaluating Commencial Real Time Expert System Software for Use in the Process Industries. C&I, 1993, рр. 107-114. В. Моorе et al. Questions and Answers about G2. 1993. Gensym Corporation. рр.26-28. B. Moore. Memorandum. 1993, April. Gensym Corparation. Р. Богатырев. "Этот странный придуманный мир". Компьютерра. c.30-33. 1996 год.
| Назад | Оглавление | Вперед |
| Каталог | Индекс раздела |
F. Hayes-Roth, N. Jacobstein. The State of Enowledge-Based Systems. Communications of the АСМ, March, 1994, v.37, n.3, рр.27-39. Р. Harmon. The Size of the Commercial AI Market in the US. Intelligent Software Strategies. 1994, v.10, n.1, рр. 1-6. Expert system saves 20 million L on pipeline management. C&I July, 1994, р.31. Р. Harmon. The Market for Intelligent Software Products. Intelligent Sopware Strategies 1992, v.8, n.2, рр.5-12. D.R Perley. Migrating to Open Systems: Taming he Tiger. McGraw-Hill, 1993, р.252. Р. Harmon. The AI Tools Market The Market for Intelligent Software Building Tools. Part I. Intelligent Softwane Strategies, 1994, v 10, n.2, pp.1-14. Р. Harmon. The market for intelligent software pnducts Intelligent Software Strategies, 1992, v.8, n.2, рр.5-12. B.R. Clements and F. Preto. Evaluating Commencial Real Time Expert System Software for Use in the Process Industries. C&I, 1993, рр. 107-114. В. Мооге et al. Questions and Answers about G2. 1993. Gensym Corporation. рр.26-28. B. Moore. Memorandum. 1993, April. Gensym Corparation. Р. Богатырев. "Этот странный придуманный мир". Компьютерра. c.30-33. 1996 год.
| Назад | Оглавление |
| Каталог | Индекс раздела |
Логические модели.
Постановка и решение любой задачи всегда связаны с ее "погружением" в подходящую предметную область. Так, решая задачу составления расписания обработки деталей на металлорежущих станках, мы вовлекаем в предметную область такие объекты, как конкретные станки, детали, интервалы времени, и общие понятия "станок", "деталь", "тип станка" и т. п. Все предметы и события, которые составляют основу общего понимания необходимой для решения задачи информации, называются предметной областью. Мысленно предметная область представляется состоящей из реальных или абстрактных объектов, называемых сущностями.
Сущности предметной области находятся в определенных отношениях друг к другу (ассоциациях), которые также можно рассматривать как сущности и включать в предметную область. Между сущностями наблюдаются различные отношения подобия. Совокупность подобных сущностей составляет класс сущностей, являющийся новой сущностью предметной области.
Отношения между сущностями выражаются с помощью суждений. Суждение-это мысленно возможная ситуация, которая может иметь место для предъявляемых сущностей или не иметь места. В языке (формальном или естественном) суждениям отвечают предложения. Суждения и предложения также можно рассматривать как сущности и включать в предметную область.
Языки, предназначенные для описания предметных областей, называются языками представления знаний. Универсальным языком представления знаний является естественный язык. Однако использование естественного языка в системах машинного представления знаний наталкивается на большие трудности ввиду присущих ему нерегулярностей, двусмысленностей, пресуппозиций и т. п. Но главное препятствие заключается в отсутствии формальной семантики естественного языка, которая имела бы достаточно эффективную операционную поддержку.
Для представления математического знания в математической логике давно пользуются логическими формализмами - главным образом исчислением предикатов, которое имеет ясную формальную семантику и операционную поддержку в том смысле, что для него разработаны механизмы вывода. Поэтому исчисление предикатов было первым логическим языком, который применили для формального описания предметных областей, связанных с решением прикладных задач.
Описания предметных областей, выполненные в логических языках, называются (формальными) логическими моделями.
Логический подход. Представление простых фактов в логических системах
Представление - это действие, делающее некоторое понятие воспринимаемым посредством фигуры, записи, языка или формализма. Теория знаний изучает связи между субъектом (изучающим) и объектом. Знание (в объективном смысле) - то, что известно (то, что знаем после изучения).
Представление знаний- формализация истинных убеждений посредством фигур, записей или языков. Нас особенно интересуют формализации, воспринимаемые (распознаваемые) ЭВМ. Возникает вопрос о представлении знаний в памяти ЭВМ, т.е. о создании языков и формализмов представления знаний. Они преобразуют наглядное представление (созданное посредством речи, изображением, естественным языком, вроде английского или немецкого, формальным языком, вроде алгебры или логики, рассуждениями и т.д.) в пригодное для ввода и обработки в ЭВМ. Результат формализации должен быть множеством инструкций, составляющих часть языка программирования.
Представлению знаний присущ пассивный аспект: книга, таблица, заполненная информацией память. В ИИ подчеркивается активный аспект представления: знать должно стать активной операцией, позволяющей не только запоминать, но и извлекать воспринятые (приобретенные, усвоенные) знания для рассуждений на их основе. Следовательно, истоки представления знаний - в науке о познании, а его конечная цель - программные средства информатики. Во многих случаях подлежащие представлению знания относятся к довольно ограниченной области, например: описание состояния человека, описание ситуации в игре (например, расположение фигур в шахматах), описание размещения персонала предприятия, описание пейзажа.
Для характеристики некой области говорят об "области рассуждений" или "области экспертизы". Численная формализация таких описаний в общем мало эффективна. Напротив, использование символического языка, такого, как язык математической логики, позволяет формулировать описания в форме, одновременно близкой и к обычному языку, и к языку программирования. Впрочем, математическая логика позволяет рассуждать, базируясь на приобретенных знаниях: логические выводы действительно являются активными операциями получения новых знаний из усвоенных.
В силу всех этих причин математическая логика лежит в основе различных представлений в ИИ. Данный раздел посвящен представлению простых фактов с помощью логики предикатов. Логическое представление служит также отправной точкой для других представлений (таких как "сетевые" и "объективные"), используемых в ИИ.
Синтаксис логики предикатов.
Язык логики предикатов задается синтакисом. Для представления знаний базисные синтаксические категории языка изображаются такими символами, которые несут достаточно четкую информацию и дают довольно ясную картину об области рассуждений (экспертизы).
Логика предикатов, называемая также логикой первого порядка, допускает четыре типа выражений.
Константы. Они служат именами индивидуумов (в отличие от имен совокупностей): объектов, людей или событий. Константы представляются символами вроде Жак_2 (добавление 2 к слову Жак указывает на вполне определенного человека среди людей с таким именем), Книга_22, Посылка_8. Переменные. Обозначают имена совокупностей, таких как человек, книга, посылка, событие. Символ Книга_22 представляет вполне определенный экземпляр, а символ книга указывает либо множество "всех книг", либо "понятие книги". Символами x,y,z представлены имена совокупностей (определенных множеств или понятий). Предикатные имена. Они задают правила соединения констанат и переменных, например правила грамматики, процедуры, математические операции. Для предикативных имен используются символы наподобие следующих: Фраза, Посылать, Писать, Плюс, Разделить. Предикатное имя иначе называется предикатной константой. Функциональные имена представляют такие же правила, как и предикаты. Чтобы не спутать с предикатными именами, функциональные имена пишут одними строчными буквами: фраза, посылать, писать, плюс, разделить. Их называют так же функциональными константами. Символы, которые применяются для представления констант, переменных, предикатов и функций, не являются "словами русского языка".Они суть символы некоторого представления - слова "объектного языка" (в нашем случае языка предикатов).
Представление должно исключать всякую двусмысленность языка. Поэтому имена индивидуумов содержат цифры, приписываемые к именам совокупностей. Жак_1 и Жак_2 представляют двух людей с одинаковыми именами. Эти представления суть конкретизации имени совокупности "Жак". Предикат - это предикатное имя вместе с подходящим числом термов. Предикат называют так же предикатной формой.
Машина вывода, подсистема моделирования и планировщики
Главный недостаток прямого и обратного вывода, используемых в статических экспертных системах, - непредсказуемость затрат времени на их выполнение. С точки зрения динамических систем, полный перебор возможных к применению правил - непозволительная роскошь. В связи с тем, что G2 ориентирована на приложения, работающие в реальном времени, в машине вывода должны быть средства для сокращения перебора, для реакции на непредвиденные события и т.п. Для машины вывода G2 характерен богатый набор способов возбуждения правил. Предусмотрено девять случаев:
Данные, входящие в антецедент правила изменились (прямой вывод - forward chaining). Правило определяет значение переменной, которое требуется другому правил или процедуре (обратный вывод - backward chaining). Каждые n секунд, где n - число, определенное для данного правила (сканирование - scan). Явное или неявное возбуждение другим правилом - путем применения действий фокусирования и возбуждения (focus и invoke). Каждый раз при запуске приложения. Входящей в антецедент переменной присвоено значение, независимо от того, изменилось оно или нет. Определенный объект на экране перемещен пользователем или другим правилом. Определенное отношение между объектами установлено или уничтожено. Переменная не получила значения в результате обращения к своему источнику данных.Если первые два способа достаточно распространены и в статических системах, а третий хорошо известен как механизм запуска процедур-демонов, то остальные являются уникальной особенностью системы G2. В связи с тем, что G2-приложение управляет множеством одновременно исполняемых задач, необходим планировщик. Хотя пользователь никогда не взаимодействует с ним, планировщик контролирует всю активность, видимую пользователем, и активность фоновых задач. Планировщик определяет порядок обработки задач, взаимодействует с источниками данных и пользователями, запускает процессы и осуществляет коммуникацию с другими процессами в сети.
Подсистема моделирования G2 - достаточно автономная, но важная часть системы.
На различных этапах жизненного цикла прикладной системы она служит достижению различных целей. Во время разработки подсистема моделирования используется вместо объектов реального мира для имитации показаний датчиков. Очевидно, что проводить отладку на реальных объектах может оказаться слишком дорого, а иногда (например, при разработке системы управления атомной станцией) и небезопасно.
На этапе эксплуатации прикладной системы процедуры моделирования выполняются параллельно функциям мониторинга и управления процессом, что обеспечивает следующие возможности:
верификация показаний датчиков во время исполнения приложения; подстановка модельных значений переменных при невозможности получения реальных значений (выход из строя датчика или длительное время реакции на запрос).
Как видим, играя роль самостоятельного агента знаний, подсистема моделирования повышает жизнеспособность и надежность приложений. Для описания внешнего мира подсистема моделирования использует уравнения трех видов: алгебраические, разностные и дифференциальные (первого порядка).
Методы озвучивания речи
Теперь скажем несколько слов о наиболее распространенных методах озвучивания, то есть о методах получения информации, управляющей параметрами создаваемого звукового сигнала, и способах формирования самого звукового сигнала.Самое широкое разделение стратегий, применяемых при озвучивании речи, - это разделение на подходы, которые направлены на построение действующей модели речепроизводящей системы человека, и подходы, где ставится задача смоделировать акустический сигнал как таковой. Первый подход известен под названием артикуляторного синтеза. Второй подход представляется на сегодняшний день более простым, поэтому он гораздо лучше изучен и практически более успешен. Внутри него выделяется два основных направления- формантный синтез по правилам и компилятивный синтез.
Формантные синтезаторы используют возбуждающий сигнал, который проходит через цифровой фильтр, построенный на нескольких резонансах, похожих на резонансы голосового тракта. Разделение возбуждающего сигнала и передаточной функции голосового тракта составляет основу классической акустической теории речеобразования.
Компилятивный синтез осуществляется путем склейки нужных единиц компиляции из имеющегося инвентаря. На этом принципе построено множество систем, использующих разные типы единиц и различные методы составления инвентаря. В таких системах необходимо применять обработку сигнала для приведения частоты основного тона, энергии и длительности единиц к тем, которыми должна характеризоваться синтезируемая речь. Кроме того, требуется, чтобы алгоритм обработки сигнала сглаживал разрывы в формантной (и спектральной в целом) структуре на границах сегментов. В системах компилятивного синтеза применяются два разных типа алгоритмов обработки сигнала: LР (сокр. англ. Linear Рreduction - линейное предсказание) и РSOLA (сокр. англ. Рitch Sуnchronous Оvеrlap аnd Аdd). LP-синтез основан в значительной степени на акустической теории речеобразования, в отличие от РSOLA-синтеза, который действует путем простого разбиения звуковой волны, составляющей единицу компиляции, на временные окна и их преобразования. Алгоритмы РSOLA позволяют добиваться хорошего сохранения естественности звучания при модификации исходной звуковой волны.
Методы поиска решений в экспертных системах
Методы решения задач, основанные на сведении их к поиску, зависят от
психодиагностика в психосоматике, а также другие системы. особенностей предметной области, в которой решается задача, и от требований, предъявляемых пользователем к решению. Особенности предметной области с точки зрения методов решения можно характеризовать следующими параметрами:
размер, определяющий объем пространства, в котором предстоит искать решение; изменяемость области, характеризует степень изменяемости области во времени и пространстве (здесь будем выделять статические и динамические области); полнота модели, описывающей область, характеризует адекватность модели, используемой для описания данной области. Обычно если модель не полна, то для описания области используют несколько моделей, дополняющих друг друга за счет отражения различных свойств предметной области; определенность данных о решаемой задаче, характеризует степень точности (ошибочности) и полноты (неполноты) данных. Точность (ошибочность) является показателем того, что предметная область с точки зрения решаемых задач описана точными или неточными данными; под полнотой (неполнотой) данных понимается достаточность (недостаточность) входных данных для однозначного решения задачи.Требования пользователя к результату задачи, решаемой с помощью поиска, можно характеризовать количеством решений и свойствами результата и (или) способом его получения. Параметр "количество решений" может принимать следующие основные значения: одно решение, несколько решений, все решения. Параметр "свойства" задает ограничения, которым должен удовлетворять полученный результат или способ его получения. Так, например, для системы, выдающей рекомендации по лечению больных, пользователь может указать требование не использовать некоторое лекарство (в связи с его отсутствием или в связи с тем, что оно противопоказано данному пациенту). Параметр "свойства" может определять и такие особенности, как время решения ("не более чем", "диапазон времени" и т.п.), объем памяти, используемой для получения результата, указание об обязательности (невозможности) использования каких-либо знаний (данных) и т.п.
Итак, сложность задачи, определяемая вышеприведенным набором параметров, варьируется от простых задач малой размерности с неизменяемыми определенными данными и отсутствием ограничений на результат и способ его получения до сложных задач большой размерности с изменяемыми, ошибочными и неполными данными и произвольными ограничениями на результат и способ его получения. Из общих соображений ясно, что каким-либо одним методом нельзя решить все задачи. Обычно одни методы превосходят другие только по некоторым из перечисленных параметров.
Рассмотренные ниже методы могут работать в статических и динамических проблемных средах. Для того чтобы они работали в условиях динамики, необходимо учитывать время жизни значений переменных, источник данных для переменных, а также обеспечивать возможность хранения истории значений переменных, моделирования внешнего окружения и оперирования временными категориями в правилах.
Существующие методы решения задач, используемые в экспертных системах, можно классифицировать следующим образом:
методы поиска в одном пространстве - методы, предназначенные для использования в следующих условиях: области небольшой размерности, полнота модели, точные и полные данные;
методы поиска в иерархических пространствах - методы, предназначенные для работы в областях большой размерности;
методы поиска при неточных и неполных данных ;
методы поиска, использующие несколько моделей, предназначенные для работы с областями, для адекватного описания которых одной модели недостаточно.
Предполагается, что перечисленные методы при необходимости должны объединяться для того, чтобы позволить решать задачи сложность которых возрастает одновременно по нескольким параметрам.
Методы решения задач.
Функционирование многих ИС носит целенаправленный характер (примером могут служить автономные интеллектуальные роботы). Типичным актом такого функционирования является решение задачи планирования пути достижения нужной цели из некоторой фиксированной начальной ситуации. Результатом решения задачи должен быть план действий - частично-упорядоченная совокупность действий. Такой план напоминает сценарий, в котором в качестве отношения между вершинами выступают отношения типа: "цель-подцель" "цель-действие", "действие-результат" и т. п. Любой путь в этом сценарии, ведущий от вершины, соответствующей текущей ситуации, в любую из целевых вершин, определяет план действий.
Поиск плана действий возникает в ИС лишь тогда, когда она сталкивается с нестандартной ситуацией, для которой нет заранее известного набора действий, приводящих к нужной цели. Все задачи построения плана действий можно разбить на два типа, которым соответствуют различные модели: планирование в пространстве состояний (SS-проблема) и планирование в пространстве задач (PR-проблема).
В первом случае считается заданным некоторое пространство ситуаций. Описание ситуаций включает состояние внешнего мира и состояние ИС, характеризуемые рядом параметров. Ситуации образуют некоторые обобщенные состояния, а действия ИС или изменения во внешней среде приводят к изменению актуализированных в данный момент состояний. Среди обобщенных состояний выделены начальные состояния (обычно одно) и конечные (целевые) состояния. SS-проблема состоит в поиске пути, ведущего из начального состояния в одно из конечных. Если, например, ИС предназначена для игры в шахматы, то обобщенными состояниями будут позиции, складывающиеся на шахматной доске. В качестве начального состояния может рассматриваться позиция, которая зафиксирована в данный момент игры, а в качестве целевых позиций - множество ничейных позиций. Отметим, что в случае шахмат прямое перечисление целевых позиций невозможно. Матовые и ничейные позиции описаны на языке, отличном от языка описания состояний, характеризуемых расположением фигур на полях доски. Именно это затрудняет поиск плана действий в шахматной игре.
При планировании в пространстве задач ситуация несколько иная. Пространство образуется в результате введения на множестве задач отношения типа: "часть - целое", "задача - подзадача", "общий случай - частный случай" и т. п. Другими словами, пространство задач отражает декомпозицию задач на подзадачи (цели на подцели). PR-проблема состоит в поиске декомпозиции исходной задачи на подзадачи, приводящей к задачам, решение которых системе известно. Например, ИС известно, как вычисляются значения sin x и cosx для любого значения аргумента и как производится операция деления. Если ИС необходимо вычислить tg x, то решением PR-проблемы будет представление этой задачи в виде декомпозиции tgx=sin x/cos x (кроме х=p /2+kp ).
Методы синтеза речи
Теперь, после оптимистического описания ближайшего будущего, давайте обратимся собственно к технологии синтеза речи. Рассмотрим какой-нибудь хотя бы минимально осмысленный текст. Текст состоит из слов, разделенных пробелами и знаками препинания. Произнесение слов зависит от их расположения в предложении, а интонация фразы - от знаков препинания. Более того, довольно часто и от типа применяемой грамматической конструкции: в ряде случаев при произнесении текста слышится явная пауза, хотя какие-либо знаки препинания отсутствуют. Наконец, произнесение зависит и от смысла слова! Сравните, например, выбор одного из вариантов "за 'мок" или " замо 'к" для одного и того же слова "замок".
Уже стартовый анализ проблемы показывает ее сложность. И в самом деле, на эту тему написаны десятки монографий, и огромное количество публикаций осуществляется ежемесячн. Поэтому мы здесь коснемся только самых общих, наиболее важных для понимания моментов.
Модели представления знаний. Неформальные (семантические) модели.
Существуют два типа методов представления знаний (ПЗ):
Формальные модели ПЗ; Неформальные (семантические, реляционные) модели ПЗ.Очевидно, все методы представления знаний, которые рассмотрены выше, включая продукции (это система правил, на которых основана продукционная модель представления знаний), относятся к неформальным моделям. В отличие от формальных моделей, в основе которых лежит строгая математическая теория, неформальные модели такой теории не придерживаются. Каждая неформальная модель годится только для конкретной предметной области и поэтому не обладает универсальностью, которая присуща моделям формальным. Логический вывод - основная операция в СИИ - в формальных системах строг и корректен, поскольку подчинен жестким аксиоматическим правилам. Вывод в неформальных системах во многом определяется самим исследователем, который и отвечает за его корректность.
Каждому из методов ПЗ соответствует свой способ описания знаний.
1. Логические модели. В основе моделей такого типа лежит формальная система, задаваемая четверкой вида: M = <T, P, A, B>. Множество T есть множество базовых элементов различной природы, например слов из некоторого ограниченного словаря, деталей детского конструктора, входящих в состав некоторого набора и т.п. Важно, что для множества T существует некоторый способ определения принадлежности или непринадлежности произвольного элемента к этому множеству. Процедура такой проверки может быть любой, но за конечное число шагов она должна давать положительный или отрицательный ответ на вопрос, является ли x элементом множества T. Обозначим эту процедуру П(T).
Множество P есть множество синтаксических правил. С их помощью из элементов T образуют синтаксически правильные совокупности. Например, из слов ограниченного словаря строятся синтаксически правильные фразы, из деталей детского конструктора с помощью гаек и болтов собираются новые конструкции. Декларируется существование процедуры П(P), с помощью которой за конечное число шагов можно получить ответ на вопрос, является ли совокупность X синтаксически правильной.
В множестве синтаксически правильных совокупностей выделяется некоторое подмножество A. Элементы A называются аксиомами. Как и для других составляющих формальной системы, должна существовать процедура П(A), с помощью которой для любой синтаксически правильной совокупности можно получить ответ на вопрос о принадлежности ее к множеству A.
Множество B есть множество правил вывода. Применяя их к элементам A, можно получать новые синтаксически правильные совокупности, к которым снова можно применять правила из B. Так формируется множество выводимых в данной формальной системе совокупностей. Если имеется процедура П(B), с помощью которой можно определить для любой синтаксически правильной совокупности, является ли она выводимой, то соответствующая формальная система называется разрешимой. Это показывает, что именно правило вывода является наиболее сложной составляющей формальной системы.
Для знаний, входящих в базу знаний, можно считать, что множество A образуют все информационные единицы, которые введены в базу знаний извне, а с помощью правил вывода из них выводятся новые производные знания. Другими словами формальная система представляет собой генератор порождения новых знаний, образующих множество выводимых в данной системе знаний. Это свойство логических моделей делает их притягательными для использования в базах знаний. Оно позволяет хранить в базе лишь те знания, которые образуют множество A, а все остальные знания получать из них по правилам вывода.
2. Сетевые модели. В основе моделей этого типа лежит конструкция, названная ранее семантической сетью. Сетевые модели формально можно задать в виде H = <I, C1, C2, ..., Cn, Г>. Здесь I есть множество информационных единиц; C1, C2, ..., Cn - множество типов связей между информационными единицами. Отображение Г задает между информационными единицами, входящими в I, связи из заданного набора типов связей.
В зависимости от типов связей, используемых в модели, различают классифицирующие сети, функциональные сети и сценарии.
В классифицирующих сетях используются отношения структуризации. Такие сети позволяют в базах знаний вводить разные иерархические отношения между информационными единицами. Функциональные сети характеризуются наличием функциональных отношений. Их часто называют вычислительными моделями, т.к. они позволяют описывать процедуры "вычислений" одних информационных единиц через другие. В сценариях используются каузальные отношения, а также отношения типов "средство - результат", "орудие - действие" и т.п. Если в сетевой модели допускаются связи различного типа, то ее обычно называют семантической сетью.
3. Продукционные модели. В моделях этого типа используются некоторые элементы логических и сетевых моделей. Из логических моделей заимствована идея правил вывода, которые здесь называются продукциями, а из сетевых моделей - описание знаний в виде семантической сети. В результате применения правил вывода к фрагментам сетевого описания происходит трансформация семантической сети за счет смены ее фрагментов, наращивания сети и исключения из нее ненужных фрагментов. Таким образом, в продукционных моделях процедурная информация явно выделена и описывается иными средствами, чем декларативная информация. Вместо логического вывода, характерного для логических моделей, в продукционных моделях появляется вывод на знаниях.
4. Фреймовые модели. В отличие от моделей других типов во фреймовых моделях фиксируется жесткая структура информационных единиц, которая называется протофреймом. В общем виде она выглядит следующим образом:
(Имя фрейма:
Имя слота 1(значение слота 1)
Имя слота 2(значение слота 2)
. . . . . . . . . . . . . . . . . . . . . .
Имя слота К (значение слота К)).
Значением слота может быть практически что угодно (числа или математические соотношения, тексты на естественном языке или программы, правила вывода или ссылки на другие слоты данного фрейма или других фреймов). В качестве значения слота может выступать набор слотов более низкого уровня, что позволяет во фреймовых представлениях реализовать "принцип матрешки".
При конкретизации фрейма ему и слотам присваиваются конкретные имена и происходит заполнение слотов. Таким образом, из протофреймов получаются фреймы - экземпляры. Переход от исходного протофрейма к фрейму - экземпляру может быть многошаговым, за счет постепенного уточнения значений слотов.
Например, структура табл. 1.1, записанная в виде протофрейма, имеет вид
(Список работников:
Фамилия (значение слота 1);
Год рождения (значение слота 2);
Специальность (значение слота 3);
Стаж (значение слота 4)).
Если в качестве значений слотов использовать данные табл. 1.1, то получится фрейм - экземпляр
(Список работников:
Фамилия (Попов - Сидоров - Иванов - Петров);
Год рождения (1965 - 1946 - 1925 - 1937);
Специальность (слесарь - токарь - токарь - сантехник);
Стаж (5 - 20 - 30 - 25)).
Связи между фреймами задаются значениями специального слота с именем "Связь". Часть специалистов по ИС считает, что нет необходимости специально выделять фреймовые модели в представлении знаний, т.к. в них объединены все основные особенности моделей остальных типов.
Модуль лингвистической обработки
Прежде всего, текст, подлежащий прочтению, поступает в модуль лингвистической обработки. В нем производится определение языка (в многоязычной системе синтеза), а также отфильтровываются не подлежащие произнесению символы. В некоторых случаях используются спелчекеры (модули исправления орфографических и пунктуационных ошибок). Затем происходит нормализация текста, то есть осуществляется разделение введенного текста на слова и остальные последовательности символов. К символам относятся, в частности, знаки препинания и символы начала абзаца. Все знаки пунктуации очень информативны.Для озвучивания цифр разрабатываются специальные подблоки. Преобразование цифр в последовательности слов является относительно легкой задачей (если читать цифры как цифры, а не как числа, которые должны быть правильно оформлены грамматически), но цифры, имеющие разное значение и функцию, произносятся по-разному. Для многих языков можно говорить, например, о существовании отдельной произносительной подсистемы телефонных номеров. Пристальное внимание нужно уделить правильной идентификации и озвучиванию цифр, обозначающих числа месяца, годы, время, телефонные номера, денежные суммы и т. д. (список для различных языков может быть разным).
Наиболее распространенные системы синтеза речи
Наиболее распространенными системами синтеза речи на сегодня, очевидно, являются системы, поставляемые в комплекте со звуковыми платами. Если ваш компьютер оснащен какой-либо из них, существует значительная вероятность того, что на нем установлена система синтеза речи - увы, не русской, а английской речи, точнее, ее американского варианта. К большинству оригинальных звуковых плат Sound Blaster прилагается система Сreative Техt-Аssist, а вместе со звуковыми картами других производителей часто поставляется программа Моnо1оgue компании First Byte.
TextAssist представляет собой реализацию формантного синтезатора по правилам и базируется на системе DECTalk, разработанной корпорацией Digital Eguipment при участии известного американского фонетиста Денниса Клана (к сожалению, рано ушедшего из жизни). DECTalk до сих пор остается своего рода стандартом качества для синтеза речи американского варианта английского. Компания Сrеаtive Technologies предлагает разработчикам использовать ТехtАssist в своих программах с помощью специального ТехtАssistАpi(ААРI). Поддерживаемые операционные системы - МS Windows и Windows 95; для Windws NT также существует версия системы DЕСТаlk, изначально создававшейся для Digital Units. Новая версия ТехtАssist, объявленная фирмой Аssotiative Computing, inс. и разработанная с использованием технологий DЕСTа1k и Сrеаtivе, является в то же время многоязычной системой синтеза, поддерживая английский, немецкий, испанский и французский языки. Это обеспечивается прежде всего использованием соответствующих лингвистических модулей, разработчик которых - фирма Lеrnout& Наuspie Sреесh Рrоducts, признанный лидер в поддержке многоязычных речевых технологий. В новой версии будет встроенный редактор словаря, а также специализированное устройство ТехtRеаdеr с кнопочным управлением работой синтезатора в разных режимах чтения текста.
Программа Моnоlоguе, предназначенная для озвучивания текста, находящегося в буфере обмена МS Windows, использует систему РrоVоiсе.
РrоVоiсе - компилятивный синтезатор с использованием оптимального выбора режима компрессии речи и сохранения пограничных участков между звуками, разновидность ТD-РS0LА. Рассчитан на американский и британский английский, немецкий, французский, латино-американскую разновидность испанского и итальянский языки. Инвентарь сегментов компиляции - смешанной размерности: сегменты - фонемы или аллофоны. Компания First Вуtе позиционирует систему РrоVоicе и программные продукты, основанные на ней, как приложения с низким потреблением процессорного времени. FirstByte также предлагает рассчитанную на мощные компьютеры систему артикуляторного синтеза РrimoVox для использования в приложениях телефонии. Для разработчиков: Моnо1оguе Win32 поддерживает спецификацию Мicrosoft SAPI.
Мода на свободно распространяемые продукты не миновала и области приложений синтеза речи. МВR0LA- так называется система многоязычного синтеза, реализующая особый гибридный алгоритм компилятивного синтеза и работающая как под РС/ Windows 3.1, РС/Windows 95, так и под Sun4. Впрочем, система принимает на входе цепочку фонем, а не текст, и потому не является, строго говоря, системой синтеза речи по тексту. Формантный синтезатор Тru-Voicе фирмы Сеntigram Cоmmunication Соrporation(США) близок к описанным выше системам по архитектуре и предоставляемым возможностям, однако он поддерживает больше языков: американский английский, латино-американский, испанский, немецкий, французский, итальянский. Кроме того, в этот синтезатор включен специальный препроцессор, который обеспечивает быструю подготовку для чтения сообщений, получаемых по электронной почте, факсов и баз данных.
Назначение экспертных систем
В начале восьмидесятых годов в исследованиях по искусственному интеллекту сформировалось самостоятельное направление, получившее название "экспертные системы" (ЭС). Цель исследований по ЭС состоит в разработке программ, которые при решении задач, трудных для эксперта-человека, получают результаты, не уступающие по качеству и эффективности решениям, получаемым экспертом. Исследователи в области ЭС для названия своей дисциплины часто используют также термин "инженерия знаний", введенный Е.Фейгенбаумом как "привнесение принципов и инструментария исследований из области искусственного интеллекта в решение трудных прикладных проблем, требующих знаний экспертов".
Программные средства (ПС), базирующиеся на технологии экспертных систем, или инженерии знаний (в дальнейшем будем использовать их как синонимы), получили значительное распространение в мире. Важность экспертных систем состоит в следующем:
технология экспертных систем существенно расширяет круг практически значимых задач, решаемых на компьютерах, решение которых приносит значительный экономический эффект; технология ЭС является важнейшим средством в решении глобальных проблем традиционного программирования: длительность и, следовательно, высокая стоимость разработки сложных приложений; высокая стоимость сопровождения сложных систем, которая часто в несколько раз превосходит стоимость их разработки; низкий уровень повторной используемости программ и т.п.; объединение технологии ЭС с технологией традиционного программирования добавляет новые качества к программным продуктам за счет: обеспечения динамичной модификации приложений пользователем, а не программистом; большей "прозрачности" приложения (например, знания хранятся на ограниченном ЕЯ, что не требует комментариев к знаниям, упрощает обучение и сопровождение); лучшей графики; интерфейса и взаимодействия.По мнению ведущих специалистов , в недалекой перспективе ЭС найдут следующее применение:
ЭС будут играть ведущую роль во всех фазах проектирования, разработки, производства, распределения, продажи, поддержки и оказания услуг;технология ЭС, получившая коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей.
ЭС предназначены для так называемых неформализованных задач, т.е. ЭС не отвергают и не заменяют традиционного подхода к разработке программ, ориентированного на решение формализованных задач.
Неформализованные задачи обычно обладают следующими особенностями:
ошибочностью, неоднозначностью, неполнотой и противоречивостью исходных данных;
ошибочностью, неоднозначностью, неполнотой и противоречивостью знаний о проблемной области и решаемой задаче;
большой размерностью пространства решения, т.е. перебор при поиске решения весьма велик;
динамически изменяющимися данными и знаниями.
Следует подчеркнуть, что неформализованные задачи представляют большой и очень важный класс задач. Многие специалисты считают, что эти задачи являются наиболее массовым классом задач, решаемых ЭВМ.
Экспертные системы и системы искусственного интеллекта отличаются от систем обработки данных тем, что в них в основном используются символьный (а не числовой) способ представления, символьный вывод и эвристический поиск решения (а не исполнение известного алгоритма).
Экспертные системы применяются для решения только трудных практических (не игрушечных) задач. По качеству и эффективности решения экспертные системы не уступают решениям эксперта-человека. Решения экспертных систем обладают "прозрачностью", т.е. могут быть объяснены пользователю на качественном уровне. Это качество экспертных систем обеспечивается их способностью рассуждать о своих знаниях и умозаключениях. Экспертные системы способны пополнять свои знания в ходе взаимодействия с экспертом. Необходимо отметить, что в настоящее время технология экспертных систем используется для решения различных типов задач (интерпретация, предсказание, диагностика, планирование, конструирование, контроль, отладка, инструктаж, управление ) в самых разнообразных проблемных областях, таких, как финансы, нефтяная и газовая промышленность, энергетика, транспорт, фармацевтическое производство, космос, металлургия, горное дело, химия, образование, целлюлозно-бумажная промышленность, телекоммуникации и связь и др.
Коммерческие успехи к фирмам-разработчикам систем искусственного интеллекта (СИИ) пришли не сразу. На протяжении 1960 - 1985 гг. успехи ИИ касались в основном исследовательских разработок, которые демонстрировали пригодность СИИ для практического использования. Начиная примерно с 1985 г. (в массовом масштабе с 1988 - 1990 гг.), в первую очередь ЭС, а в последние годы системы, воспринимающие естественный язык (ЕЯ-системы), и нейронные сети (НС) стали активно использоваться в коммерческих приложениях.
Следует обратить внимание на то, что некоторые специалисты (как правило, специалисты в программировании, а не в ИИ) продолжают утверждать, что ЭС и СИИ не оправдали возлагавшихся на них ожиданий и умерли. Причины таких заблуждений состоят в том, что эти авторы рассматривали ЭС как альтернативу традиционному программированию, т.е. они исходили из того, что ЭС в одиночестве (в изоляции от других программных средств) полностью решают задачи, стоящие перед заказчиком. Надо отметить, что на заре появления ЭС специфика используемых в них языков, технологии разработки приложений и используемого оборудования (например, Lisp-машины) давала основания предполагать, что интеграция ЭС с традиционными, программными системами является сложной и, возможно, невыполнимой задачей при ограничениях, накладываемых реальными приложениями. Однако в настоящее время коммерческие инструментальные средства (ИС) для создания ЭС разрабатываются в полном соответствии с современными технологическими тенденциями традиционного программирования, что снимает проблемы, возникающие при создании интегрированных приложений.
Причины, приведшие СИИ к коммерческому успеху, следующие.
Интегрированность. Разработаны инструментальные средства искусственного интеллекта (ИС ИИ), легко интегрирующиеся с другими информационными технологиями и средствами (с CASE, СУБД, контроллерами, концентраторами данных и т.п.).
Открытость и переносимость. ИС ИИ разрабатываются с соблюдением стандартов, обеспечивающих открытость и переносимость [14].
Использование языков традиционного программирования и рабочих станций. Переход от ИС ИИ, реализованных на языках ИИ (Lisp, Prolog и т.п.), к ИС ИИ, реализованным на языках традиционного программирования (С, C++ и т.п.), упростил обеспечение интегриро-ванности, снизил требования приложений ИИ к быстродействию ЭВМ и объемам оперативной памяти. Использование рабочих станций (вместо ПК) резко увеличило круг приложений, которые могут быть выполнены на ЭВМ с использованием ИС ИИ.
Архитектура клиент-сервер. Разработаны ИС ИИ, поддерживающие распределенные вычисления по архитектуре клиент-сервер, что позволило:снизить стоимость оборудования, используемого в приложениях, децентрализовать приложения, повысить надежность и общую производительность (так как сокращается количество информации, пересылаемой между ЭВМ, и каждый модуль приложения выполняется на адекватном ему оборудовании).
Проблемно/предметно-ориентированные ИС ИИ. Переход от разработок ИС ИИ общего назначения (хотя они не утратили свое значение как средство для создания ориентированных ИС) к проблемно/предметно-ориентированным ИС ИИ [9] обеспечивает: сокращение сроков разработки приложений; увеличение эффективности использования ИС; упрощение и ускорение работы эксперта; повторную используемость информационного и программного обеспечения (объекты,классы,правила,процедуры).
Область применения.
Доказательства теорем; Игры; Распознавание образов; Принятие решений; Адаптивное программирование; Сочинение машинной музыки; Обработка данных на естественном языке; Обучающиеся сети (нейросети); Вербальные концептуальные обучения.
Планы на будущее в области применения ИИ: В сельском хозяйстве компьютеры должны оберегать посевы от вредителей, подрезать деревья и обеспечивать избирательный уход. В горной промышленности компьютеры призваны работать там, где возникают слишком опасные условия для людей. В сфере производства ВМ должны выполнять различного вида задачи по сборке и техническом контроле. В учреждениях ВМ обязаны заниматься составлением расписаний для коллективов и отдельных людей, делать краткую сводку новостей. В учебных заведениях ВМ должны рассматривать задачи, которые решают студенты, в поисках ошибок, подобно тому как ищутся ошибки в программе, и устранять их. Они должны обеспечивать студентов суперкнигами, хранящимися в памяти вычислительных систем. В больницах ВМ должны помогать ставить диагноз, направлять больных в соответствующие отделения, контролировать ход лечения. В домашнем хозяйстве ВМ должны помогать советами по готовке пищи, закупке продуктов, следить за состоянием пола в квартире и газона в саду. Конечно, в настоящее время ни одна из этих вещей не представляется возможной, но исследования в области ИИ могут способствовать их реализации.
Обобщенная функциональная структура синтезатора
Структура идеализированной системы автоматического синтеза речи состоит из нескольких блоков. Определение языка текста Нормализация текста Лингвистический анализ:синтаксический,морфемный анализ и т.д. Формирование просоидических характеристик Фонемный транскриптор Формирование управляющей информации Получение звукового сигнала
Она не описывает ни одну из существующих реально систем, но содержит компоненты, которые можно обнаружить во многих системах. Авторы конкретных систем, независимо от того, являются ли эти системы уже коммерческим продуктом или еще находятся в стадии исследовательской разработки, уделяют различное внимание отдельным блокам и реализуют их очень по-разному, в соответствии с практическими требованиями.
Оценки сложности задачи планирования
Приведем ряд результатов, касающихся сложности решения задач планирования.
1. Анализ вычислительных задач оказывается PSPACE-полной проблемой даже при условии, что "пустых" величин W нет .
2. Для вычислительных моделей без функциональных величин, т. е. с пустыми Db и F, проблема анализа вычислительных задач оказывается: а) PSPACE-полной для Н, содержащих функциональные и операторные зависимости без W ; б) NP-полной для Н, содержащих только функциональные и вариантные зависимости без "пустой" величины W ; в) полиномиальной (по времени работы планировщика) для Н, содержащих только функциональные и неявные зависимости; г) можно построить планировщики с линейным временем работы для Н только с функциональными зависимостями без W и для Н с функциональными и неявными зависимостями .
В системе ПГИЗ Db и F пусты, а в Н имеются только функциональные и операторные зависимости без "пустой" величины W. В системе автоматического синтеза программ СПОРА используется исчисление предикатов, для которого разработана специальная стратегия вывода .
Дерево анализа для вычислительной задачи - это дерево из формул используемого исчисления, в корне которого находится формула, представляющая исходную задачу, каждая нетерминальная вершина дерева может быть получена по одному из правил вывода "исчисления вычислительных задач" из формул, расположенных в дереве непосредственно ниже, а терминальные (висячие) вершины не являются заключением ни одного из правил вывода "исчисления вычислительных задач".
Планировщик в таком исчислении работает следующим образом: для заданной задачи конструируется какое-нибудь дерево анализа. Если все его висячие вершины являются аксиомами, то по этому дереву "собирается" программа. В противном случае формируется обоснование того, что задача неразрешима. Отсутствие детерминизма при логическом выводе в исчислениях стандартного типа приводит к экспоненциальному перебору возможных ветвей. Обнаружение при таком переборе тупика оказывается бесполезным (или почти бесполезным) для поиска на других ветвях дерева вывода.
Показателем интеллектуальности системы с точки зрения представления знаний считается способность системы использовать в нужный момент необходимые (релевантные) знания. Системы, не имеющие средств для определения релевантных знаний, неизбежно сталкиваются с проблемой "комбинаторного взрыва". Можно утверждать, что эта проблема является одной из основных причин, ограничивающих сферу применения экспертных систем. В проблеме доступа к знаниям можно выделить три аспекта: связность знаний и данных, механизм доступа к знаниям и способ сопоставления. Связность {агрегация) знаний является основным способом, обеспечивающим ускорение поиска релевантных знаний. Большинство специалистов пришли к убеждению, что знания следует организовывать вокруг наиболее важных объектов (сущностей) предметной области. Все знания, характеризующие некоторую сущность, связываются и представляются в виде отдельного объекта. При подобной организации знаний, если системе потребовалась информация о некоторой сущности, то она ищет объект, описывающий эту сущность, а затем уже внутри объекта отыскивает информацию о данной сущности. В объектах целесообразно выделять два типа связок между элементами: внешние и внутренние. Внутренние связки объединяют элементы в единый объект и предназначены для выражения структуры объекта. Внешние связки отражают взаимозависимости, существующие между объектами в области экспертизы. Многие исследователи классифицируют внешние связки на логические и ассоциативные. Логические связки выражают семантические отношения между элементами знаний. Ассоциативные связки предназначены для обеспечения взаимосвязей, способствующих ускорению процесса поиска релевантных знаний. Основной проблемой при работе с большой базой знаний является проблема поиска знаний, релевантных решаемой задаче. В связи с тем, что в обрабатываемых данных может не содержаться явных указаний на значения, требуемые для их обработки, необходим более общий механизм доступа, чем метод прямого доступа (метод явных ссылок).
В " исчислении вычислительных задач" для полного решения задачи планировщику достаточно располагать каким-нибудь деревом анализа. При разумной стратегии построения деревьев анализа это позволяет получать сравнительно быстрые процедуры планирования .
В общем случае планировщику приходится решать PSPACE-полную задачу. Это означает, что все известные сейчас планировщики на почти всех вычислительных задачах работают экспоненциальное время. В реальности ситуация не столь плоха. Практически интересные задачи, как правило, допускают эффективное планирование. И хотя доля подобных задач с ростом параметров, определяющих их, стремится к нулю, именно они представляют интерес с точки зрения эффективности автоматического синтеза программ. Показателем практически интересных задач может служить степень взаимодействия подзадач в процессе решения исходной задачи . Понятия "подзадача" и "условия подзадачи" возникают уже на стадии наивной интерпретации следующих зависимостей.
Функциональной зависимости (F->Y1), где F -функциональная величина типа (X->-Y), предполагающей предварительный синтез процедуры вычисления F, входными параметрами которой являются величины из списка X.
Операторных зависимостей, предполагающих синтез т процедур с входами "условиями подзадач" X1, Х2, ..., Хь-
Вариантных зависимостей, предполагающих, что создаются две ветви вычислений: для первой известны значения всех величин из списка Y1, для второй - из списка У2.
Рассмотрим простой (но типичный) пример. Пусть имеют место функциональная зависимость D1: (A, В, СR Е) и операторные зависимости D2: ((СR Е ) R Е1), D3:(( BR Е1))R Е2)), D4: ((AR Е2 ) R Е3). Необходимо найти Ез. Для этого следует решить подзадачу (AR Е2 ). Если воспользоваться зависимостью D3, то придем к поиску решения новой подзадачи ( BR Е1). Если использовать зависимость D2, то придем к необходимости решения подзадачи ( CR Е), которая согласно D1 разрешима только тогда, когда A и В известны.
Степень взаимодействия подзадач в этом примере равна трем. Процесс является типичной схемой планирования в пространстве задач .
Для планировщиков, работающих в "исчислении вычислительных задач;", синтез решения вычислительной задачи происходит за время hqrl/r!, где h - константа, l-длина записи задачи, определяемая как суммарное число вхождений имен используемых величин в F и H, q- общее число "различных" аргументов величин из "условия подзадач" в операторных зависимостях из H и "условий вариантов" в вариантных зависимостях из H, r-минимальная степень взаимодействия подзадач в исходной задаче . Эта оценка носит квазиоптимальный характер. Планировщик работает долго только на тех задачах, которые не являются естественными, так как требуют предельного переплетения между собой всех подзадач, на которые разбивается исходная задача. Эксперименты показывают, что для задач, встречающихся на практике, время работы планировщика является полиномиальным. Память, необходимая для работы планировщика в "исчислении вычислительных задач", оценивается величиной bl2, где Ь - константа. Если в Н нет вариантных зависимостей, то требуется линейный объем памяти dl, где d-константа .
В известных сейчас планировщиках получаемые программы далеки от оптимальных. Наблюдается тенденция ухудшения качества программ при уменьшении времени работы планировщика. При этом синтезировать оптимальные последовательные программы труднее, чем оптимальные параллельные программы. Это обстоятельство в связи с развитием ЭВМ новой архитектуры, ориентированной на параллельные процессы, может оказаться выгодным. Например, задача поиска минимальных по времени последовательного исполнения программ для решения вычислительных задач, у которых Db пусто, а Н состоит только из функциональных зависимостей W , оказывается NP-полной в сильном смысле . С другой стороны, в "исчислении вычислительных задач" при условии, что Db пусто, а Н состоит из функциональных и неявных зависимостей, можно за линейное время kl (k - константа) синтезировать программу, параллельное выполнение которой требует минимального для данной задачи времени .
В системе ПРИЗ и ее модификациях вычислительная задача считается разрешимой, если соответствующая ей формула выводима в позитивном фрагменте интуиционистского исчисления высказываний , т. е. в том и только том случае, когда достигается успех планировщиком системы ПРИЗ. Для "исчисления вычислительных задач" возможны две семантики для разрешимости .
Предельно неконструктивная; вычислительная задача считается разрешимой, если в любой базе данных (любой интерпретации), удовлетворяющей всем ограничениям вычислительной модели, имеет место некоторая функция типа (XR Y);
предельно конструктивная: обобщенная стандартная схема программы считается решением вычислительной задачи, если в любой интерпретации, удовлетворяющей всем ограничениям вычислительной модели, имеет место функция типа (XR Y), вычисляемая программой П, получающейся из обобщенной стандартной схемы программы соответствующей конкретизацией предикатных и функциональных символов.
"Исчисление вычислительных задач" корректно и полно относительно обеих семантик. При первой семантике планировщик всегда выдает решение исходной задачи в виде правильной программы, при второй - класс всех пропозициональных формул, описывающих разрешимые вычислительные задачи, совпадает с классом всех формул, выводимых в интуиционистском исчислении высказываний. Это показывает, что "исчисление вычислительных задач" можно рассматривать как один из вариантов формализации предложенной в интерпретации интуиционистской логики как логики "задач".
Во многих ИС используются планировщики, возможности которых существенно шире, чем у планировщика системы ПРИЗ, или того, который применяется в "исчислении вычислительных задач". Исчисления, с которыми имеют дело многие планировщики систем автоматизированного проектирования, планирования и управления, шире интуиционистских исчислений высказываний. При этом используются эвристические соображения, не имеющие аналогов в тех соотношениях, в которых описывались вычислительные модели.Примером может служить планировщик системы МАВР, предназначенной для ИС автоматизированного проектирования . При его работе возникают ситуации, не разрешимые в теории, которая описывалась выше. Такие случаи заставляют искать иные пути построения системы для поиска планов действий.
Организация знаний в базе данных
Задача этого механизма состоит в том, чтобы по некоторому описанию сущности , имеющемуся в рабочей памяти, найти , базе знаний объекты, удовлетворяющие этому описанию. Очевидно, что упорядочение и структурирование знаний могут значительно ускорить процесс поиска.
Нахождение желаемых объектов в общем случае уместно рассматривать как двухэтапный процесс. На первом этапе, соответствующем процессу выбора по ассоциативным связкам, совершается предварительный выбор в базе знаний потенциальных кандидатов на роль желаемых объектов. На втором этапе путем выполнения операции сопоставления потенциальных кандидатов с описаниями кандидатов осуществляется окончательный выбор искомых объектов. При организации подобного механизма доступа возникают определенные трудности: Как выбрать критерий пригодности кандидата? Как организовать работу в конфликтных ситуациях? и т.п.
Операция сопоставления может использоваться не только как средство выбора нужного объекта из множества кандидатов; она может быть использована для классификации, подтверждения, декомпозиции и коррекции. Для идентификации неизвестного объекта он может быть сопоставлен с некоторыми известными образцами. Это позволит классифицировать неизвестный объект как такой известный образец, при сопоставлении с которым были получены лучшие результаты. При поиске сопоставление используется для подтверждения некоторых кандидатов из множества возможных. Если осуществлять сопоставление некоторого известного объекта с неизвестным описанием, то в случае успешного сопоставления будет осуществлена частичная декомпозиция описания.
Операции сопоставления весьма разнообразны. Обычно выделяют следующие их формы: синтаксическое, параметрическое, семантическое и принуждаемое сопоставления. В случае синтаксического сопоставления соотносят формы (образцы), а не содержание объектов. Успешным является сопоставление, в результате которого образцы оказываются идентичными. Обычно считается, что переменная одного образца может быть идентична любой константе (или выражению) другого образца.Иногда на переменные, входящие в образец, накладывают требования, определяющие тип констант, с которыми они могут сопоставляться. Результат синтаксического сопоставления является бинарным: образцы сопоставляются или не сопоставляются . В параметрическом сопоставлении вводится параметр, определяющий степень сопоставления. В случае семантического сопоставления соотносятся не образцы объектов, а их функции. В случае принуждаемого сопоставления один сопоставляемый образец рассматривается с точки зрения другого. В отличие от других типов сопоставления здесь всегда может быть получен положительный результат. Вопрос состоит в силе принуждения. Принуждение могут выполнять специальные процедуры, связываемые с объектами. Если эти процедуры не в состоянии осуществить сопоставление, то система сообщает, что успех может быть достигнут только в том случае, если определенные части рассматриваемых сущностей можно считать сопоставляющимися.
![]()